Lo spamming è certamente uno dei più grandi flagelli dell’era di Internet. Spam non è soltanto l’invio indiscriminato di posta spazzatura, ma è anche ogni attività online di promozione indiscriminata di prodotti e/o servizi mediante gli strumenti offerti da Internet come la posta elettronica, ma anche forum, newsgroup, chat, ecc.
Al fine di combattere questo tipo di attività, molte web applications (come forum, blog, ecc.) integrano al loro interno dei metodi di protezione che hanno lo scopo principale di discriminare gli interventi umani (che si assume essere per lo più legittimi) da quelli automatici (effettuati tramite robot che hanno lo scopo di riempire il web di contenuti promozionali). Questo tipo di strumento prende il nome di CAPTCHA (Acronimo di Completely Automated Public Turing test to tell Computers and humans Apart).
Il CAPTCHA, come molti di voi già sapranno, non è altro che un semplice sistema di verifica basato su un file d’immagine contenente al suo interno una parola (generalmente scritta con caratteri particolari ed articolati) che dev’essere digitata dall’utente affinchè il modulo venga processato. In questo modo se l’utente è un essere umano il form verrà processato, se viceversa l’utente è un robot la sua incapacità di leggere il contenuto di quel file d’immagine impedirà il corretto submit del form.
Da un punto di vista logico il ragionamento è ineccepibile, se non fosse che gli spammer si stanno facendo sempre più bravi (il giro d’affari dello spam è tanto elevato da giustificare tutti gli sforzi profusi dagli spammer) tanto d’aver progettato robot intelligenti in grado di riconoscere (mediante la tecnologia OCR – Optica Character Recognition) il contenuto dei CAPTCHA, eludendo di fatto il controllo di sicurezza.
Al fine di dare una risposta ai bisogni di sicurezza delle comuni web application è nato ReCAPTCHA, un utile servizio on-line (ideato dalla prestigiosa Carnegie Mellon University ed in seguito acquisito da Google) che consente di integrare nel proprio sito un CAPTCHA con elevati livelli di sicurezza ed avanzate funzionalità (come ad esempio il supporto audio per gli utenti non vedenti).
Lo scopo di ReCAPTCHA, tuttavia, non è soltanto sconfiggere lo spam, ma è anche (e soprattutto) quello ancor più nobile di offrire un contributo alla colossale opera di digitalizzazione di migliaia di libri antichi al fine di salvaguarne i preziosi contenuti per le generazioni future.
Spesso i libri antichi, infatti, non possono essere digitalizzati automaticamente mediante le tecniche di OCR (ad esempio perchè il supporto cartaceo è deteriorarto e non consente una corretta lettura dei caratteri) ma richiedono un intervento umano e quindi un’enorme dispendio di tempo e di risorse che non sempre il mondo della cultura ha a sua disposizione.
Di seguito un esempio circa i suddetti problemi di scannerizzazione mediante OCR:

L’idea nasce da un dato piuttosto interessante: secondo una recente stima ogni giorno sarebbero circa 60.000.000 i CAPTCHA risolti dagli utenti della Rete; moltiplicando questo dato per il tempo medio impiegato per leggere, interpretare e scrivere ogni CAPTCHA si ottiene che il tempo complessivo speso dai surfers sarebbe pari a circa 150.000 ore ogni giorno!
I cervelloni sponsorizzati dalla Carnegie Mellon University hanno così pensato di "recuperare" questa enorme mole di lavoro per impiegarla nell’opera di traduzione/digitalizzazione dell’Internet Archive.
Il sistema funziona così: attraverso una sofisticata tecnologia, ReCAPTCHA fornisce all’utente un codice CAPTCHA composto da due parole:
- una dal significato certo
- ed una "sconosciuta" (si tratta, appunto, di una parola tratta da un libro antico non riconosciuta dall’OCR).
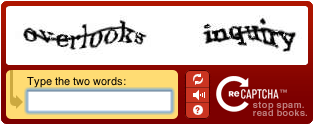
- la verifica del CAPTCHA ha esito positivo (ed il modulo viene processato);
- la lettura umana della parola "sconosciuta" viene salvata da ReCAPTCHA quale possibile corretta traduzione della stessa. Questo processo viene ripetuto, ovviamente, con migliaia di utenti diversi in modo da avere delle risultanze "statisticamente" certe circa il significato del temine del testo antico che non si era riusciti a scannerizzare mediante OCR.
Da un punto di vista meramente tecnico il servizio offerto da ReCAPTCHA porta allo sviluppatore notevoli vantaggi:
- nessun carico di lavoro per il server locale;
- non è necessario installare nessuna libreria o acquistare applicativi per la gestione del CAPTCHA;
- essendo gestito da remoto ReCAPTCHA è costantemente aggiornato per far fronte alle ultime minacce dello spam;
- offre un elevato grado di sicurezza, integrando tra l’altro un sistema di verifica degli IP in grado di riconoscere e bannare automaticamente quelli identificati come fonti di spam;
In futuri articoli vedremo come integrare questa risorsa nelle nostre web-application.