- Mittente e destinatario sono situati nella stessa rete – Il router leggendo il pacchetto si accorge che la destinazione si trova nella rete da lui gestita e quindi semplicemente inoltrerà il pacchetto verso la destinazione.
- Mittente e destinazione sono situati su reti diverse – In questa situazione le cose si complicano perchè l’instradamento non è immediato. Il router che serve la rete del mittente si accorge che il pacchetto non è indirizzato a nessuno degli host a lui connessi. A questo punto il router controlla la sua tabbella di routing e inoltra il pacchetto al router indicato nella tabella. Questo processo di inoltro del pacchetto tra vari router prosegue finchè il pacchetto non raggiunge il router che serve la rete di destinazione. A questo punto quest’ultimo si accorge che il pacchetto è indirizzato ad uno dei suoi host connessi e semplicemente inoltra il pacchetto direttamente all’host di destinazione.
Routing statico e routing dinamico
Fino a questo momento abbiamo visto cos’è e come viene compiuto il processo di routing. A questo punto diventa fondamentale effettuare un distinguo tra routing statico e routing dinamico. La differenza tra queste due tipologie è nel modo in cui viene creata la tabella di routing per ogni singolo router della rete. Come vedremo più avanti l’implementazione del routing statico può essere adatto a reti piccole, mentre se si vuole creare una rete di una certa dimensione si deve necessariamente implementare il routing dinamico.
Routing statico
In questa implementazione si ha che le righe costituenti la tabella di routing vengono inserite manualmente dall’amministratore di rete che crea dei percorsi fissi tra generiche sorgenti e generiche destinazioni.
E’ evidente che questa tipologia di routing è improponibile in reti di grosse dimensioni in quanto l’amministratore di rete dovrebbe scrivere migliaia di righe in ogni tabella dei router presenti nella rete. Un altro problema che affligge questa tipologia è quello della possibile rottura di un collegamento tra due host: dato che i router non si scambiano pacchetti per aggiornare dinamicamente le proprie tabelle di routing, avremo che il router non avrà modo di capire che un certo collegamento è guasto e quindi continuerà ad inviarvi pacchetti con un’evidente inefficienza della rete. A questo punto dovrà intervenire nuovamente l’amministratore di rete e riconfigurare, scegliendo un percorso alternativo, la tabella di routing.
Questa tipologia ha anche un grande vantaggio, ovvero quello del ridotto consumo di banda da parte dei router dato che quest’ultimi non scambieranno nessun pacchetto per creare le proprie tabelle di routing. Dal punto di vista della sicurezza questa tiplogia è estremamente sicura in quanto per ogni nodo si ha un solo punto d’ingresso e un solo punto d’uscita e ciò rende difficile la possibilità di introdursi, in maniera illegale, nella rete. Inoltre, dato che non è richiesto nessuno sforzo computazionale per calcolare il percorso a costo minimo, è possibile, se si vuole implementare questa tipologia di routing, fare affidamento a router a basso costo e quindi adatti per gestire reti domestiche e piccole aziende.
Routing dinamico
Questa tipologia di routing è praticamente l’antitesi della tipologia di routing statico visto prima. In questo caso le tabelle di routing vengono aggiornate in maniera dinamica da ogni router e non c’è più bisogno della presenza di un amministratore di rete che configuri i vari cammini.
I router si scambiano dei pacchetti di dimensione, struttura e informazioni diverse a seconda del tipo di algoritmo di routing che andranno ad implementare. E’ evidente che parte della banda, su tutti i collegamenti, verrà occupata dallo scambio, molto frequente, di aggiornamenti sullo stato della rete per ottimizzare maggiormente la scelta dei percorsi.
Questa tipologia di routing ha il vantaggio di poter essere implementata in reti di garndi e grandissime dimensioni e che è reattiva alla rilevazione dei guasti: infatti nel caso in cui un cammino subisca un guasto, quando un router si accorge di questo problema, riconfigurerà la propria tabella di routing cercando percorsi alternativi.
Inoltre l’utilizzo della rete è maggiormente ottimizzato in quanto, se viene rilevato un congestionamento di un certo cammino, il traffico può essere convogliato su altri percorsi che hanno volumi di traffico minori.
Dal punto di vista della sicurezza, però, questa tipologia è più vulnerabile ad attacchi rispetto al routing statico: immaginiamo cosa potrebbe succedere se un malintenzionato mandasse pacchetti di aggiornamento fasulli, verso i router, con l’obiettivo di saturare alcuni canali… E’ evidente che dunque la sicurezza deve essere garantita in un altro modo implementando un sistema di riconoscimento dei pacchetti per riuscire a capire se il pacchetto ricevuto sia prodotto da un router o da un malintenzionato.
Algoritmi di routing e classificazione
Come accennato precedentemente esistono vari tipi di algoritmi di routing più o meno performanti. Un modo per identificare vantaggi e svantaggi, è definire dei criteri precisi di valutazione che sono la base per l’analisi di un algoritmo. I criteri di valutazione e confronto sono sostanzialmente i seguenti:
- Semplicità: per quanto riguarda la realizzazione e l’implementazione nei dispositivi.
- Robustezza: l’algoritmo deve sapere reagire in maniera positiva e autonoma a particolari perturbazioni. Più precisamente l’algoritmo non deve subire penalizzazioni, per quanto riguarda l’efficienza, se avvengono degli errori o cambiamenti di metrica (che spiegheremo più avanti) all’interno della rete. Un buon algoritmo di routing deve rilevare autonomamente se sono presenti degli errori, per esempio un mal funzionamento di un nodo, ed adattarsi di conseguenza.
- Stabilità: l’algoritmo dovrà convergere ad una situazione che garantisca la stabilità. In particolare se avvengono errori all’interno della rete che allontanano l’algoritmo del punto di stabilità, l’algoritmo deve reagire velocemente a questa situazione e riuscire a convergere nuovamente alla stabilità nel minor tempo possibile.
- Ottimalità: questo parametro viene valutato seguendo opportuni criteri.
I quattro criteri di valutazione, a volte, possono trovarsi in contrapposizione tra di loro: lavorando sull’ottimizzazione, ad esempio, viene compromessa, di fatto, la semplicità, in quanto l’algoritmo ottimizzato solitamente è più complesso rispetto a quello non ottimizzato.
Diciamo che gli obiettivi principali da raggiungere sono la robustezza e la stabilità dell’algoritmo ed in un secondo momento riuscire ad avvicinarsi il più possibile all’ottimalità, per quanto riguarda le prestazione, senza però minare sensibilmente la semplicità di implementazione.
Gli algoritmi di routing, a seconda della loro implementazione, possono essere classificati nel modo seguente:
- Algoritmi con tabella: Un nodo che implementa un algoritmo di questa famiglia memorizza, per ogni richiesta di instradamento in ingresso, la linea in uscita che deve essere utilizzata.
- Algoritmi senza tabella: Questo tipo di algoritmi non prevedono abbinamenti ingresso-uscita predefiniti, ma sono di tipo reattivo, cioè attivati solo su richiesta, quando necessario.
- Algoritmi centralizzati: Prevedono esclusivamente l’uso di tabelle e hanno una unità di elaborazione dell’algoritmo centralizzata.
- Algoritmi distribuiti: Prevedono un’esecuzione dell’algoritmo in maniera distribuita a volte detta cooperativa. Anche in questo caso si prevede l’uso di tabelle.
- Algoritmi isolati: Tipicamente rivolti a realizzazioni senza tabella. Prevedono l’esecuzione in locale (stand-alone) dell’algoritmo.
A questo punto è necessario, ai fini della comprensione delle pagine seguenti, introdurre il concetto di metrica. Sostanzialmente con questo termine si intende classificare un certo percorso così da capire quale sia il più conveniente. Vengono così introdotti due parametri fondamentali per la metrica che sono gli Hops (che rappresentano il numero di nodi intermedi attraversati nel percorso mittente-destinatario) e il costo (che rappresenta il costo totale del cammino ovvero la somma dei costi di ogni singola interconnessione tra due nodi intermedi attraversati). Solitamente il costo di un percorso è inversamente proporzionale alla velocità di trasmissione e, quindi, interconnessioni che garantiscono velocità di trasmissione molto alte avranno un costo molto basso.
L’obiettivo principale degli algoritmi di routing che ricerchino l’ottimo è quello di minimizzare il costo del percorso.
Algoritmi di routing senza tabella
In questa lezione cerchiamo di analizzare, in maniera più approfondita, gli algoritmi di instradamento evidenziandone pregi e difetti.
Algoritmi senza tabella: Random
E’ una tecnica semplice e robusta: ogni richiesta di inoltro in ingresso viene selezionata in maniera casuale (random) una delle possibili uscite. E’ robusta perchè se si rompe una linea il tutto continua a funzionare in maniera corretta, semplicemente non verrà esclusa dalle pussibili uscite la linea rotta. Anche se robusto, questo tipo di algoritmo non è ottimo in quanto tutte le linee di uscite vengono considerate con lo stesso costo senza tenere traccia del congestionamento della rete. Questo fa si che se si ha un’uscita altamente congestionata e, dato la scelta casuale, viene scelta proprio quella linea si avrà un ritardo ancora maggiore. Questo algoritmo, semplicissimo da implementare, può portare ad evidenti problemi di gestione di reti con alto traffico.
Algoritmi senza tabella: Source Routing
In questo tipo di algoritmo il percorso che deve seguire il pacchetto è già inserito nell’header del pacchetto stesso. In questo caso, dunque, ipotizzando di dover inviare un messaggio da un nodo A ad un nodo B, il nodo A scriverà nel pacchetto il percorso che dovrà seguire (scriverà, per esempio, che dovrà passare dal router 1, poi dal router 2 ed infine al router 3 che inoltrerà il pacchetto al nodo B). In questo modo quindi il router che riceverà il pacchetto non compierà nessuna operazione di gestione, ma si limiterà ad inoltrare il pacchetto verso il router indicato nell’header del pacchetto.
Questo algoritmo è poco utilizzato in quanto non è assolutamente affidabile dato che il nodo A, non conoscendo la topologia della rete, non può sapere se un certo collegamento è interrotto (con conseguente perdita del pacchetto) o congestionato. Questo tipo di algoritmo, oltre ad essere inaffidabile è molto pericoloso per quanto riguarda la sicurezza della rete: se un malintenzionato avesse come obiettivo l’intasamento di un certo percorso, basterà che il malintenzionato crei un alto volumi di pacchetto inserendo il percorso da congestionare nell’header di ogni pacchetto. Per questo motivo i router presenti nella rete Internet, per garantire la sicurezza della rete, scartano a priori pacchetti nei quali è già inserito il percorso da seguire.
Algoritmi senza tabella: Flooding
Il principio su cui si basano questi algoritmi è perfettamente coerente con la sua definizione. Viene semplificata ancora di più l’implementazione dell’algoritmo in quanto ogni richiesta di inoltro presente sugli ingressi viene ripetuta su tutte le uscite. Sicuramente è una tecnica robusta (è utilizzata in diverse applicazioni militari) e ottima, ma in questo caso, l’ottimo non viene raggiunto in maniera efficiente.
Questa tecnica, tuttavia, soffre di una carenza operativa molto importante: operando con questa politica si rischia di congestionare rapidamente la rete. Un possibile rimedio a questo problema è l’introduzione di un campo nel pacchetto che porta il valore massimo delle volte che può essere ripetuto nella rete. Ogni volta che uno stesso pacchetto viene ripetuto, il campo viene decrementato di una unità e se un nodo riceve un pacchetto con il valore di questo campo a zero il pacchetto viene scartato.
Algoritmi di routing con tabella: Distance Vector
Analizziamo adesso i protocolli di routing con tabella (che sono quelli che implementati nelle reti Internet).
Il primo algoritmo con tabella che vedremo è l’algoritmo Distance Vector o vettore delle distanze. Questo tipo di algorimo ha una struttura abbastanza semplice e permette, al termine dell’algoritmo, di individuare il percorso tra una qualsiasi sorgente e una qualsiasi destinazione a costo minore. Chiramente questo algoritmo non è esente da problemi che lo affliggono in situazioni particolari che però vedremo più avanti.
L’implementazione di questo algoritmo è di tipo collaborativo dato che ogni nodo definisce in maniera autonoma la propria tabella di routing che poi viene pubblicata agli altri nodi connessi. Gli altri nodi connessi, analizzando la tabella di routing pubblicata dai nodi adiacenti, potranno aggiornare la propria tabella con percorsi a costo minore.
In questo algoritmo ogni nodo dispone di una tabella che associa ad ogni possibile destinazione un percorso mediante la specifica del nodo vicino (next-hop).
Vediamo adesso con un esempio chiarificatore di come opera l’algoritmo:
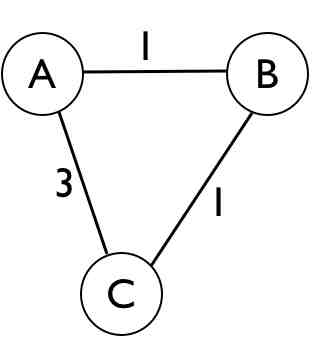
Dunque, come abbiamo detto, i nodi A, B e C creeranno le proprie tabelle di instradamento che poi pubblicheranno ai nodi adiacenti i quali valuteranno la presenza di percorsi a costo minore. Per il nostro esempio terremo in considerazione le tabelle dei nodi A e B. Inizialmente la tabella dei cammini di A sarà la seguente:
| Destinazione | Costo | Next-Hop |
| A | 0 | – |
| B | 1 | B |
| C | 3 | C |
Mentre quella dei cammini di B è la seguente:
| Destinazione | Costo | Next-Hop |
| A | 1 | A |
| B | 0 | – |
| C | 1 | C |
I due nodi (A e B) pubblicano la propria tabella.
Nella trattazione del nostro esempio ci poniamo dal punto di vista del nodo A. Quest’ultimo nota che se volesse inviare un pacchetto direttamente a C quel percorso avrebbe un costo 3 mentre seguendo il percorso A-B-C quest’ultimo avrebbe costo pari a 2. Dunque essendo il percorso A-B-C minore rispetto al percorso diretta A-C, il nodo aggiornerà il record relativo al percorso inserendo il cammino più vantaggioso.
In questo modo, anche all’interno di reti molto grandi, ogni nodo riuscirà a trovare il percorso a minima distanza anche se sorgente e destinazione si trovino a distanza notevoli.
Come detto precedentemente questo tipo di algoritmo soffre di un problema noto in caso di guasti su alcuni cammini della rete. Andiamo adesso, per meglio chiarire questo problema, a discutere l’esempio mostrato in figura:
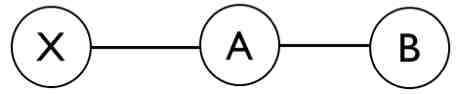
Quando un collegamento si guasta convenzionalmente il costo del cammino risulta pari ad infinito e, di fatto, il nodo è irraggiungibile. Il nodo A pubblica la nuova tabella, aggiornando il costo del collegamento A-X e si suppone che prima che il nodo B riceva l’aggiornamento dal nodo A il nodo B abbia pubblicato la propria tabella di instradamento nella quale viene dichiarato che X è raggiungibile dal nodo B con costo 6. Di conseguenza il nodo A ritiene raggiungibile X tramite il nodo B quando in realtà non lo è. Questo è un grosso problema in quanto, se ipotizziamo malfunzionamenti diffusi nella rete, quest’ultimi porterebbero ad un numero di pacchetti persi molto elevato, minando così l’affidabilità dell’intera rete. E’ chiaro che se si ricerca una buona affidabilità della rete queste problematiche devono essere risolte e ciò lo si fa utilizzando principalmente la tecnica di Split Horizon.
Questa tecnica, che complica un po’ l’algoritmo base del Distance Vector, fa si che il router scinda le informazioni in suo possesso in due parti:
- le informazioni ricevute da parte dei nodi vicini;
- e le informazioni "proprie" che egli stesso notifica ai nodi vicini.
Ciascun router, nell’inoltrare le proprie tabelle di routing ai vicini, omette per ciascun vicino gli specifici percorsi appresi da quel router. Sostanzialmente viene previsto l’aggiornamento solo per i cammini che non interessano il nodo di destinazione. Per chiarire meglio questo concetto affidiamoci all’esempio riportato in figura:

Come possiamo vedere ci sono tre nodi connessi in maniera lineare. Il nodo 1 dunque può raggiungere il nodo 3 passando per il nodo 2 con un certo costo. Quando il nodo 1 pubblica la sua tabella di routing ometterà di poter raggiungere il nodo 3 attraverso il nodo 2 dato che questa informazione, per il nodo 2, comporterebbe il passaggio per se stesso (immaginiamo che il nodo 2 voglia comunicare verso il nodo 3, non avrebbe senso il percorso 2-1-2-3). Oltre ad evitare cammini ciclici, questa tecnica permette anche di risolvere il problema, visto prima, del guasto di un collegamento: supponiamo che il collegamento tra il nodo 2 e il nodo 3 si interrompa per un generico guasto, se non venisse adottata la tecnica di split horizon il nodo 2 vedrebbe raggiungibile il nodo 3 attraverso il nodo 1 compiendo il cammino 2-1-2-3 che in questo caso, oltre a non avere senso, è anche scorretto in quanto il collegamento 2-3 non è funzionante.
Protocolli di instradamento RIP e IGRP
Nella pagina precedente abbiamo descritto il funzionamento dell’algoritmo Distance Vector che, sostanzialmente, si basa sulla pubblicazione delle tabelle d’instradamento ai nodi adiacenti per cercare i percorsi a costo minore.
In questa sezione analizzeremo in che modo vengono "trasportate" queste informazioni e, più precisamente, analizzaremo il protocollo d’instradamento RIP e il protocollo di instradamento IGRP utilizzati dall’algoritmo Distance Vector.
Protocollo di instradamento RIP
Questo protocollo è stato il primo ad essere sviluppato nel 1982. In seguito è stata proposta una seconda versione, denominata RIP2, che consente di trasmettere un numero maggiore di informazioni. Il RIP è molto diffuso in Internet e la sua caratteristica principale è quella di basare la sua metrica sull’Hop Count (ovvero il conteggio dei numeri dei salti tra i vari router prima di raggiungere la destinazione). Gli update relativi ad ogni router sono settati, di default, a 30 secondi e comportano la trasmissione – per intero! – della tabella di routing agli altri router. Questo fa si che in reti in cui il mezzo trasmissivo non è di alta qualità, dato che il protocollo RIP genera volumi di traffico abbastanza elevati, si abbia una saturazione della banda dovuta agli update delle tabelle.
Come visto precedentemente, in una procedura di instradamento di un pacchetto, si può incorrere in percorsi ciclici e quindi il RIP, per risolvere questo problema, pone un Hop Count massimo di 15, ovvero un pacchetto non potrà passare per più di 15 router prima di arrivare a destinazione.
E’ interessante analizzare anche la struttura di un generico pacchetto RIP che possiamo vedere in figura:

Facciamo adesso una rapida analisi dei campi del pacchetto:
- Command: Questo campo indica la tipologia del pacchetto, ovvero se è un pacchetto di request, che è un pacchetto inviato da un router ad un altro per richiedere la routing table, oppuere se è un pacchetto di response, che è un pacchetto che fa riferimento ad un normale update della tabella di routing o generato in risposta ad un pacchetto di request.
- Versione: Indica la versione del protocollo.
- Zeros: Progettato per usi futuri.
- Address Family Identifier: Indica il tipo di indirizzo che verrà espresso in relazione alla struttura della rete in cui è implementato il RIP. Nello standard TCP/IP l’indirizzi saranno indirizzi IP.
- IP Address: Indica l’indirizzo IP della rete di destinazione.
- Metrica: In questo campo viene inserito il valore della metrica.
Protocollo di instradamento IGRP
Questo tipo di protocollo nasce per migliorare alcuni aspetti del RIP ed è un protocollo prorietario sviluppato dalla CISCO. Le caratteristiche principali di questo protocollo sono: una maggiore scalabilità (in quanto l’hop count può salire fino al valore di 255), utilizzo di una metrica complessa che viene costruita sull’analisi di diversi fattori (che vedremo più avanti) e la possibilità di inserire nella tabella di ruting percorsi multipli per poter gestire il traffico in maniera più effciente.
Come accennato, questo protocollo usa un calcolo della metrica abbastanza complesso basato fondamentalmente su i fattori seguenti:
- Banda: Questo valore indica la larghezza di banda di una certa connessione e viene inserita durante la fase di cofigurazione. Qesto valore è abbastanza indicativo dato che non è detto che il valore indicata necessariamente rispecchi la reale larghezza di banda della connessione a cui fa riferimento.
- Affidabilità: E’ un valore che indica l’affidabilità di un certo collegamento. Questo valore è calcolato come il rapporto tra i pacchetti giunti a destinazione in maniera corretta e quelli giunti a destinazione con errori. Nel calcolo della metrica questa campo ha un peso notevole.
- Carico: Indica il volume di traffico presente in un certo percorso al momento della rilevazione.
- Ritardo: E’ un valore che indica il tempo trascorso per attraversare il collegamento. Chiaramente questo valore è variabile e dipende dal livello di congestione del collegamento.
Per quanto riguarda il funzionamento dell’update questo è identico a quello usato dal RIP, soltanto che nel IGRP la periodicità degli aggiornamenti è pari a 90 secondi.
Come possiamo vedere il protocollo IGRP è superiore, per quanto riguarda l’ottimizzazione delle decisioni di instradamento, rispetto al RIP ma se quest’ultimo è uno standard open il primo è uno standard proprietario e quindi è utilizzabile solamente dai router prodotti dalla Cisco.
Algoritmo con tabella Link State
Altro impotante algoritmo di instradamento che fa uso di tabelle è l’algoritmo Link State. Questo tipo di algoritmo è significativamente diverso rispetto al Distance Vector in quanto ogni nodo ha una visione completa della topologia della rete.
Avendo a disposizione la topologia dell’intera rete, con i costi relativi per ogni cammino, è possibile ricavare il percorso a costo minimo in maniera più diretta e non come avveniva con il Distance Vector sfruttando la pubblicazione delle tabelle di routing dei router adiacenti.
Vediamo adesso come viene creata la topologia della rete riassumendo il procedimento negli step seguenti:
- Nella fase iniziale, detta fase di start-up o inizializzazione, ogni router rileva i percorsi verso gli altri router adiacenti con il relativo costo.
- Le informazioni raccolte da ogni router vengono inviate in broadcast, ovvero a tutti i router conosciuti e connessi alla stessa rete, utilizzando pacchetti Link State
- Quando un router riceve un pacchetto LInk State, prima di analizzarlo, controlla il numero di sequenza e a seconda del valore presente compie un’operazione. Nel caso in cui il numero di sequenza sia maggiore rispetto a quello dell’ultimo pacchetto ricevuto il router capisce che il pacchetto è un reale aggiornamento e quindi processa le informazioni e memorizza i dati. Se invece il numero di sequenza del pacchetto è minore rispetto all’ultimo ricevuto presumibilmente il router mittente non ha ricevuto un aggiornamento (magari perchè il pacchetto è andato perduto), quindi il router destinazione invia il contenuto dell’ultimo pacchetto che ha ricevuto il router mittente. Infine se il numero di sequenza è invariato semplicemente il pacchetto viene scartato dato che le informazioni sono già state processate precedentemente. Alla fine tutti i router avranno a disposizione un database che sostanzialmente racchiude la topologia della rete.
A questo punto ogni router ha tutte le informazioni necessarie per calcolarsi, in maniera autonoma, i percorsi a costo minimo tra una generica sorgente e una generica destinazione. Questo calcolo viene effettuato utilizzando uno degli algoritmi shortest path first (SPF); in particolare viene utilizzato l’algoritmo di Djkstra. Questo algoritmo opera su grafi, ovvero un insieme di nodi collegati tra di loro da archi, che hanno costi positivi per ogni collegamento. Questa restrizione a costi positivi è logica in quanto non avrebbe senso imporre il costo di un certo cammino tra due router per esempio pari a -2. In questo algoritmo, implementato dal Link State, abbiamo che i nodi del grafo sono rappresentati dai router e gli archi che collegano i nodi rappresentano il percorso tra due router direttamente connessi. Il grafo dell’intera topologia della rete viene costruito partendo dalle informazioni contenute all’interno del database che ogni router possiede. La complessità dell’algoritmo di Dijkstra è quadratica, ma risulta comunque un algoritmo molto efficiente per l’individuazione di percorsi a costo minimo.
Riassumendo il protocollo Link State è molto più complesso per quanto riguarda l’implementazione rispetto all’algoritmo Distance Vector, ma riesce a gestire reti molto complesse, cosa che non riesce a fare il Distance Vector. Questa complessità dell’algoritmo porta a delle criticità dal punto di vista dell’implementazione nei router principalemnte per i seguenti fattori:
- Memoria: La conoscenza completa della topologia della rete necessita la presenza, all’interno del router, di unità di memoria abbastanza corposi.
- Capacità computazionale: E’ necessario, per l’operazione di ricerca del percorso a costo minimo, che il router sia equipaggiato da un processore che abbia una notevole capacità di calcolo. Infatti nel caso in cui la capacità di calcolo non sia sufficiente, avremo che i pacchetti, in attesa dell’instradamento, si accumulino nella coda del router generando ritardi anche consistenti.
- Banda: La fase di start-up richiede una banda suffiente a supportare volumi di traffico consistenti in quanto in questa fase tutti i router mandano in broadcast le proprie informazioni.
In sostanza i router che implementano il Link State sono router di qualità molto superiore rispetto ad altri che sono in grado di implementare solo il Distance Vector.
In questo articolo faremo una rapida – ma completa – panoramica sugli algoritmi di routing implementabili nel livello di rete, ma prima di iniziare questa analisi è necessario capire cosa si intende con la parola routing.
In linea generale, il routing è la funzione di instradamento svolta da un commutatore il cui compito consiste nel decidere dove inviare un dato elemeto di una comunicazione.
Questa funzione è normalmente implementata in dispositivi di rete detti router che lavorano, appunto, al livello rete al fine di gestirne i flussi di traffico. Oltre alle fuznionalità specifiche di inoltro, i Router possono svolgere diversi altri compiti, ad esempio:
- integrare funzionalità di Access Point (nel caso si trovasse in una rete Wi-Fi);
- svolgere funzioni di filtro mediante l’implementazione di firewall interni per l’analisi del traffico.
Per quanto riguarda la funzione di routing (in senso stretto) possiamo fare un’analogia con il sistama postale: affinchè una lettera venga recapitata con successo al destinatario abbiamo bisogno di conoscerne nome e cognome ed indirizzo; oltre a queste informazioni, però, un centro di smistamento postale avrà bisogno di conoscere anche altri dati riguardanti, ad esempio, la situazione die centri postali limitrofi, ad esempio per sapere se un dato centro postale è chiuso o intasato al fine di cercare un percorso alternativo per la consegna della missiva. Anche il processo di routing, necessariamente, ha bisogno di alcune informazioni: indispensabile l’indirizzo IP del destinatario del pacchetto, ma è anche necessario conoscere lo stato dei router adiacenti per capire se un cammino è interrottto, troppo congestionato ed eventualmente scegliere un percorso alternativo. Il router quindi, acquisite le informazioni dagli altri router, creerà delle tabelle di routing (nel caso in cui venga implementato un algortimo di routing con tabella) dove verranno inseriti i cammini più convenienti per collegare una generica sorgente con una generica destinazione.
Distinguiamo due scenari possibili per quanto riguarda il processo di routing:
- Mittente e destinatario sono situati nella stessa rete – Il router leggendo il pacchetto si accorge che la destinazione si trova nella rete da lui gestita e quindi semplicemente inoltrerà il pacchetto verso la destinazione.
- Mittente e destinazione sono situati su reti diverse – In questa situazione le cose si complicano perchè l’instradamento non è immediato. Il router che serve la rete del mittente si accorge che il pacchetto non è indirizzato a nessuno degli host a lui connessi. A questo punto il router controlla la sua tabbella di routing e inoltra il pacchetto al router indicato nella tabella. Questo processo di inoltro del pacchetto tra vari router prosegue finchè il pacchetto non raggiunge il router che serve la rete di destinazione. A questo punto quest’ultimo si accorge che il pacchetto è indirizzato ad uno dei suoi host connessi e semplicemente inoltra il pacchetto direttamente all’host di destinazione.
Routing statico e routing dinamico
Fino a questo momento abbiamo visto cos’è e come viene compiuto il processo di routing. A questo punto diventa fondamentale effettuare un distinguo tra routing statico e routing dinamico. La differenza tra queste due tipologie è nel modo in cui viene creata la tabella di routing per ogni singolo router della rete. Come vedremo più avanti l’implementazione del routing statico può essere adatto a reti piccole, mentre se si vuole creare una rete di una certa dimensione si deve necessariamente implementare il routing dinamico.
Routing statico
In questa implementazione si ha che le righe costituenti la tabella di routing vengono inserite manualmente dall’amministratore di rete che crea dei percorsi fissi tra generiche sorgenti e generiche destinazioni.
E’ evidente che questa tipologia di routing è improponibile in reti di grosse dimensioni in quanto l’amministratore di rete dovrebbe scrivere migliaia di righe in ogni tabella dei router presenti nella rete. Un altro problema che affligge questa tipologia è quello della possibile rottura di un collegamento tra due host: dato che i router non si scambiano pacchetti per aggiornare dinamicamente le proprie tabelle di routing, avremo che il router non avrà modo di capire che un certo collegamento è guasto e quindi continuerà ad inviarvi pacchetti con un’evidente inefficienza della rete. A questo punto dovrà intervenire nuovamente l’amministratore di rete e riconfigurare, scegliendo un percorso alternativo, la tabella di routing.
Questa tipologia ha anche un grande vantaggio, ovvero quello del ridotto consumo di banda da parte dei router dato che quest’ultimi non scambieranno nessun pacchetto per creare le proprie tabelle di routing. Dal punto di vista della sicurezza questa tiplogia è estremamente sicura in quanto per ogni nodo si ha un solo punto d’ingresso e un solo punto d’uscita e ciò rende difficile la possibilità di introdursi, in maniera illegale, nella rete. Inoltre, dato che non è richiesto nessuno sforzo computazionale per calcolare il percorso a costo minimo, è possibile, se si vuole implementare questa tipologia di routing, fare affidamento a router a basso costo e quindi adatti per gestire reti domestiche e piccole aziende.
Routing dinamico
Questa tipologia di routing è praticamente l’antitesi della tipologia di routing statico visto prima. In questo caso le tabelle di routing vengono aggiornate in maniera dinamica da ogni router e non c’è più bisogno della presenza di un amministratore di rete che configuri i vari cammini.
I router si scambiano dei pacchetti di dimensione, struttura e informazioni diverse a seconda del tipo di algoritmo di routing che andranno ad implementare. E’ evidente che parte della banda, su tutti i collegamenti, verrà occupata dallo scambio, molto frequente, di aggiornamenti sullo stato della rete per ottimizzare maggiormente la scelta dei percorsi.
Questa tipologia di routing ha il vantaggio di poter essere implementata in reti di garndi e grandissime dimensioni e che è reattiva alla rilevazione dei guasti: infatti nel caso in cui un cammino subisca un guasto, quando un router si accorge di questo problema, riconfigurerà la propria tabella di routing cercando percorsi alternativi.
Inoltre l’utilizzo della rete è maggiormente ottimizzato in quanto, se viene rilevato un congestionamento di un certo cammino, il traffico può essere convogliato su altri percorsi che hanno volumi di traffico minori.
Dal punto di vista della sicurezza, però, questa tipologia è più vulnerabile ad attacchi rispetto al routing statico: immaginiamo cosa potrebbe succedere se un malintenzionato mandasse pacchetti di aggiornamento fasulli, verso i router, con l’obiettivo di saturare alcuni canali… E’ evidente che dunque la sicurezza deve essere garantita in un altro modo implementando un sistema di riconoscimento dei pacchetti per riuscire a capire se il pacchetto ricevuto sia prodotto da un router o da un malintenzionato.
Algoritmi di routing e classificazione
Come accennato precedentemente esistono vari tipi di algoritmi di routing più o meno performanti. Un modo per identificare vantaggi e svantaggi, è definire dei criteri precisi di valutazione che sono la base per l’analisi di un algoritmo. I criteri di valutazione e confronto sono sostanzialmente i seguenti:
- Semplicità: per quanto riguarda la realizzazione e l’implementazione nei dispositivi.
- Robustezza: l’algoritmo deve sapere reagire in maniera positiva e autonoma a particolari perturbazioni. Più precisamente l’algoritmo non deve subire penalizzazioni, per quanto riguarda l’efficienza, se avvengono degli errori o cambiamenti di metrica (che spiegheremo più avanti) all’interno della rete. Un buon algoritmo di routing deve rilevare autonomamente se sono presenti degli errori, per esempio un mal funzionamento di un nodo, ed adattarsi di conseguenza.
- Stabilità: l’algoritmo dovrà convergere ad una situazione che garantisca la stabilità. In particolare se avvengono errori all’interno della rete che allontanano l’algoritmo del punto di stabilità, l’algoritmo deve reagire velocemente a questa situazione e riuscire a convergere nuovamente alla stabilità nel minor tempo possibile.
- Ottimalità: questo parametro viene valutato seguendo opportuni criteri.
I quattro criteri di valutazione, a volte, possono trovarsi in contrapposizione tra di loro: lavorando sull’ottimizzazione, ad esempio, viene compromessa, di fatto, la semplicità, in quanto l’algoritmo ottimizzato solitamente è più complesso rispetto a quello non ottimizzato.
Diciamo che gli obiettivi principali da raggiungere sono la robustezza e la stabilità dell’algoritmo ed in un secondo momento riuscire ad avvicinarsi il più possibile all’ottimalità, per quanto riguarda le prestazione, senza però minare sensibilmente la semplicità di implementazione.
Gli algoritmi di routing, a seconda della loro implementazione, possono essere classificati nel modo seguente:
- Algoritmi con tabella: Un nodo che implementa un algoritmo di questa famiglia memorizza, per ogni richiesta di instradamento in ingresso, la linea in uscita che deve essere utilizzata.
- Algoritmi senza tabella: Questo tipo di algoritmi non prevedono abbinamenti ingresso-uscita predefiniti, ma sono di tipo reattivo, cioè attivati solo su richiesta, quando necessario.
- Algoritmi centralizzati: Prevedono esclusivamente l’uso di tabelle e hanno una unità di elaborazione dell’algoritmo centralizzata.
- Algoritmi distribuiti: Prevedono un’esecuzione dell’algoritmo in maniera distribuita a volte detta cooperativa. Anche in questo caso si prevede l’uso di tabelle.
- Algoritmi isolati: Tipicamente rivolti a realizzazioni senza tabella. Prevedono l’esecuzione in locale (stand-alone) dell’algoritmo.
A questo punto è necessario, ai fini della comprensione delle pagine seguenti, introdurre il concetto di metrica. Sostanzialmente con questo termine si intende classificare un certo percorso così da capire quale sia il più conveniente. Vengono così introdotti due parametri fondamentali per la metrica che sono gli Hops (che rappresentano il numero di nodi intermedi attraversati nel percorso mittente-destinatario) e il costo (che rappresenta il costo totale del cammino ovvero la somma dei costi di ogni singola interconnessione tra due nodi intermedi attraversati). Solitamente il costo di un percorso è inversamente proporzionale alla velocità di trasmissione e, quindi, interconnessioni che garantiscono velocità di trasmissione molto alte avranno un costo molto basso.
L’obiettivo principale degli algoritmi di routing che ricerchino l’ottimo è quello di minimizzare il costo del percorso.
Algoritmi di routing senza tabella
In questa lezione cerchiamo di analizzare, in maniera più approfondita, gli algoritmi di instradamento evidenziandone pregi e difetti.
Algoritmi senza tabella: Random
E’ una tecnica semplice e robusta: ogni richiesta di inoltro in ingresso viene selezionata in maniera casuale (random) una delle possibili uscite. E’ robusta perchè se si rompe una linea il tutto continua a funzionare in maniera corretta, semplicemente non verrà esclusa dalle pussibili uscite la linea rotta. Anche se robusto, questo tipo di algoritmo non è ottimo in quanto tutte le linee di uscite vengono considerate con lo stesso costo senza tenere traccia del congestionamento della rete. Questo fa si che se si ha un’uscita altamente congestionata e, dato la scelta casuale, viene scelta proprio quella linea si avrà un ritardo ancora maggiore. Questo algoritmo, semplicissimo da implementare, può portare ad evidenti problemi di gestione di reti con alto traffico.
Algoritmi senza tabella: Source Routing
In questo tipo di algoritmo il percorso che deve seguire il pacchetto è già inserito nell’header del pacchetto stesso. In questo caso, dunque, ipotizzando di dover inviare un messaggio da un nodo A ad un nodo B, il nodo A scriverà nel pacchetto il percorso che dovrà seguire (scriverà, per esempio, che dovrà passare dal router 1, poi dal router 2 ed infine al router 3 che inoltrerà il pacchetto al nodo B). In questo modo quindi il router che riceverà il pacchetto non compierà nessuna operazione di gestione, ma si limiterà ad inoltrare il pacchetto verso il router indicato nell’header del pacchetto.
Questo algoritmo è poco utilizzato in quanto non è assolutamente affidabile dato che il nodo A, non conoscendo la topologia della rete, non può sapere se un certo collegamento è interrotto (con conseguente perdita del pacchetto) o congestionato. Questo tipo di algoritmo, oltre ad essere inaffidabile è molto pericoloso per quanto riguarda la sicurezza della rete: se un malintenzionato avesse come obiettivo l’intasamento di un certo percorso, basterà che il malintenzionato crei un alto volumi di pacchetto inserendo il percorso da congestionare nell’header di ogni pacchetto. Per questo motivo i router presenti nella rete Internet, per garantire la sicurezza della rete, scartano a priori pacchetti nei quali è già inserito il percorso da seguire.
Algoritmi senza tabella: Flooding
Il principio su cui si basano questi algoritmi è perfettamente coerente con la sua definizione. Viene semplificata ancora di più l’implementazione dell’algoritmo in quanto ogni richiesta di inoltro presente sugli ingressi viene ripetuta su tutte le uscite. Sicuramente è una tecnica robusta (è utilizzata in diverse applicazioni militari) e ottima, ma in questo caso, l’ottimo non viene raggiunto in maniera efficiente.
Questa tecnica, tuttavia, soffre di una carenza operativa molto importante: operando con questa politica si rischia di congestionare rapidamente la rete. Un possibile rimedio a questo problema è l’introduzione di un campo nel pacchetto che porta il valore massimo delle volte che può essere ripetuto nella rete. Ogni volta che uno stesso pacchetto viene ripetuto, il campo viene decrementato di una unità e se un nodo riceve un pacchetto con il valore di questo campo a zero il pacchetto viene scartato.
Algoritmi di routing con tabella: Distance Vector
Analizziamo adesso i protocolli di routing con tabella (che sono quelli che implementati nelle reti Internet).
Il primo algoritmo con tabella che vedremo è l’algoritmo Distance Vector o vettore delle distanze. Questo tipo di algorimo ha una struttura abbastanza semplice e permette, al termine dell’algoritmo, di individuare il percorso tra una qualsiasi sorgente e una qualsiasi destinazione a costo minore. Chiramente questo algoritmo non è esente da problemi che lo affliggono in situazioni particolari che però vedremo più avanti.
L’implementazione di questo algoritmo è di tipo collaborativo dato che ogni nodo definisce in maniera autonoma la propria tabella di routing che poi viene pubblicata agli altri nodi connessi. Gli altri nodi connessi, analizzando la tabella di routing pubblicata dai nodi adiacenti, potranno aggiornare la propria tabella con percorsi a costo minore.
In questo algoritmo ogni nodo dispone di una tabella che associa ad ogni possibile destinazione un percorso mediante la specifica del nodo vicino (next-hop).
Vediamo adesso con un esempio chiarificatore di come opera l’algoritmo:
Dunque, come abbiamo detto, i nodi A, B e C creeranno le proprie tabelle di instradamento che poi pubblicheranno ai nodi adiacenti i quali valuteranno la presenza di percorsi a costo minore. Per il nostro esempio terremo in considerazione le tabelle dei nodi A e B. Inizialmente la tabella dei cammini di A sarà la seguente:
| Destinazione | Costo | Next-Hop |
| A | 0 | – |
| B | 1 | B |
| C | 3 | C |
Mentre quella dei cammini di B è la seguente:
| Destinazione | Costo | Next-Hop |
| A | 1 | A |
| B | 0 | – |
| C | 1 | C |
I due nodi (A e B) pubblicano la propria tabella.
Nella trattazione del nostro esempio ci poniamo dal punto di vista del nodo A. Quest’ultimo nota che se volesse inviare un pacchetto direttamente a C quel percorso avrebbe un costo 3 mentre seguendo il percorso A-B-C quest’ultimo avrebbe costo pari a 2. Dunque essendo il percorso A-B-C minore rispetto al percorso diretta A-C, il nodo aggiornerà il record relativo al percorso inserendo il cammino più vantaggioso.
In questo modo, anche all’interno di reti molto grandi, ogni nodo riuscirà a trovare il percorso a minima distanza anche se sorgente e destinazione si trovino a distanza notevoli.
Come detto precedentemente questo tipo di algoritmo soffre di un problema noto in caso di guasti su alcuni cammini della rete. Andiamo adesso, per meglio chiarire questo problema, a discutere l’esempio mostrato in figura:
Quando un collegamento si guasta convenzionalmente il costo del cammino risulta pari ad infinito e, di fatto, il nodo è irraggiungibile. Il nodo A pubblica la nuova tabella, aggiornando il costo del collegamento A-X e si suppone che prima che il nodo B riceva l’aggiornamento dal nodo A il nodo B abbia pubblicato la propria tabella di instradamento nella quale viene dichiarato che X è raggiungibile dal nodo B con costo 6. Di conseguenza il nodo A ritiene raggiungibile X tramite il nodo B quando in realtà non lo è. Questo è un grosso problema in quanto, se ipotizziamo malfunzionamenti diffusi nella rete, quest’ultimi porterebbero ad un numero di pacchetti persi molto elevato, minando così l’affidabilità dell’intera rete. E’ chiaro che se si ricerca una buona affidabilità della rete queste problematiche devono essere risolte e ciò lo si fa utilizzando principalmente la tecnica di Split Horizon.
Questa tecnica, che complica un po’ l’algoritmo base del Distance Vector, fa si che il router scinda le informazioni in suo possesso in due parti:
- le informazioni ricevute da parte dei nodi vicini;
- e le informazioni "proprie" che egli stesso notifica ai nodi vicini.
Ciascun router, nell’inoltrare le proprie tabelle di routing ai vicini, omette per ciascun vicino gli specifici percorsi appresi da quel router. Sostanzialmente viene previsto l’aggiornamento solo per i cammini che non interessano il nodo di destinazione. Per chiarire meglio questo concetto affidiamoci all’esempio riportato in figura:
Come possiamo vedere ci sono tre nodi connessi in maniera lineare. Il nodo 1 dunque può raggiungere il nodo 3 passando per il nodo 2 con un certo costo. Quando il nodo 1 pubblica la sua tabella di routing ometterà di poter raggiungere il nodo 3 attraverso il nodo 2 dato che questa informazione, per il nodo 2, comporterebbe il passaggio per se stesso (immaginiamo che il nodo 2 voglia comunicare verso il nodo 3, non avrebbe senso il percorso 2-1-2-3). Oltre ad evitare cammini ciclici, questa tecnica permette anche di risolvere il problema, visto prima, del guasto di un collegamento: supponiamo che il collegamento tra il nodo 2 e il nodo 3 si interrompa per un generico guasto, se non venisse adottata la tecnica di split horizon il nodo 2 vedrebbe raggiungibile il nodo 3 attraverso il nodo 1 compiendo il cammino 2-1-2-3 che in questo caso, oltre a non avere senso, è anche scorretto in quanto il collegamento 2-3 non è funzionante.
Protocolli di instradamento RIP e IGRP
Nella pagina precedente abbiamo descritto il funzionamento dell’algoritmo Distance Vector che, sostanzialmente, si basa sulla pubblicazione delle tabelle d’instradamento ai nodi adiacenti per cercare i percorsi a costo minore.
In questa sezione analizzeremo in che modo vengono "trasportate" queste informazioni e, più precisamente, analizzaremo il protocollo d’instradamento RIP e il protocollo di instradamento IGRP utilizzati dall’algoritmo Distance Vector.
Protocollo di instradamento RIP
Questo protocollo è stato il primo ad essere sviluppato nel 1982. In seguito è stata proposta una seconda versione, denominata RIP2, che consente di trasmettere un numero maggiore di informazioni. Il RIP è molto diffuso in Internet e la sua caratteristica principale è quella di basare la sua metrica sull’Hop Count (ovvero il conteggio dei numeri dei salti tra i vari router prima di raggiungere la destinazione). Gli update relativi ad ogni router sono settati, di default, a 30 secondi e comportano la trasmissione – per intero! – della tabella di routing agli altri router. Questo fa si che in reti in cui il mezzo trasmissivo non è di alta qualità, dato che il protocollo RIP genera volumi di traffico abbastanza elevati, si abbia una saturazione della banda dovuta agli update delle tabelle.
Come visto precedentemente, in una procedura di instradamento di un pacchetto, si può incorrere in percorsi ciclici e quindi il RIP, per risolvere questo problema, pone un Hop Count massimo di 15, ovvero un pacchetto non potrà passare per più di 15 router prima di arrivare a destinazione.
E’ interessante analizzare anche la struttura di un generico pacchetto RIP che possiamo vedere in figura:
Facciamo adesso una rapida analisi dei campi del pacchetto:
- Command: Questo campo indica la tipologia del pacchetto, ovvero se è un pacchetto di request, che è un pacchetto inviato da un router ad un altro per richiedere la routing table, oppuere se è un pacchetto di response, che è un pacchetto che fa riferimento ad un normale update della tabella di routing o generato in risposta ad un pacchetto di request.
- Versione: Indica la versione del protocollo.
- Zeros: Progettato per usi futuri.
- Address Family Identifier: Indica il tipo di indirizzo che verrà espresso in relazione alla struttura della rete in cui è implementato il RIP. Nello standard TCP/IP l’indirizzi saranno indirizzi IP.
- IP Address: Indica l’indirizzo IP della rete di destinazione.
- Metrica: In questo campo viene inserito il valore della metrica.
Protocollo di instradamento IGRP
Questo tipo di protocollo nasce per migliorare alcuni aspetti del RIP ed è un protocollo prorietario sviluppato dalla CISCO. Le caratteristiche principali di questo protocollo sono: una maggiore scalabilità (in quanto l’hop count può salire fino al valore di 255), utilizzo di una metrica complessa che viene costruita sull’analisi di diversi fattori (che vedremo più avanti) e la possibilità di inserire nella tabella di ruting percorsi multipli per poter gestire il traffico in maniera più effciente.
Come accennato, questo protocollo usa un calcolo della metrica abbastanza complesso basato fondamentalmente su i fattori seguenti:
- Banda: Questo valore indica la larghezza di banda di una certa connessione e viene inserita durante la fase di cofigurazione. Qesto valore è abbastanza indicativo dato che non è detto che il valore indicata necessariamente rispecchi la reale larghezza di banda della connessione a cui fa riferimento.
- Affidabilità: E’ un valore che indica l’affidabilità di un certo collegamento. Questo valore è calcolato come il rapporto tra i pacchetti giunti a destinazione in maniera corretta e quelli giunti a destinazione con errori. Nel calcolo della metrica questa campo ha un peso notevole.
- Carico: Indica il volume di traffico presente in un certo percorso al momento della rilevazione.
- Ritardo: E’ un valore che indica il tempo trascorso per attraversare il collegamento. Chiaramente questo valore è variabile e dipende dal livello di congestione del collegamento.
Per quanto riguarda il funzionamento dell’update questo è identico a quello usato dal RIP, soltanto che nel IGRP la periodicità degli aggiornamenti è pari a 90 secondi.
Come possiamo vedere il protocollo IGRP è superiore, per quanto riguarda l’ottimizzazione delle decisioni di instradamento, rispetto al RIP ma se quest’ultimo è uno standard open il primo è uno standard proprietario e quindi è utilizzabile solamente dai router prodotti dalla Cisco.
Algoritmo con tabella Link State
Altro impotante algoritmo di instradamento che fa uso di tabelle è l’algoritmo Link State. Questo tipo di algoritmo è significativamente diverso rispetto al Distance Vector in quanto ogni nodo ha una visione completa della topologia della rete.
Avendo a disposizione la topologia dell’intera rete, con i costi relativi per ogni cammino, è possibile ricavare il percorso a costo minimo in maniera più diretta e non come avveniva con il Distance Vector sfruttando la pubblicazione delle tabelle di routing dei router adiacenti.
Vediamo adesso come viene creata la topologia della rete riassumendo il procedimento negli step seguenti:
- Nella fase iniziale, detta fase di start-up o inizializzazione, ogni router rileva i percorsi verso gli altri router adiacenti con il relativo costo.
- Le informazioni raccolte da ogni router vengono inviate in broadcast, ovvero a tutti i router conosciuti e connessi alla stessa rete, utilizzando pacchetti Link State
- Quando un router riceve un pacchetto LInk State, prima di analizzarlo, controlla il numero di sequenza e a seconda del valore presente compie un’operazione. Nel caso in cui il numero di sequenza sia maggiore rispetto a quello dell’ultimo pacchetto ricevuto il router capisce che il pacchetto è un reale aggiornamento e quindi processa le informazioni e memorizza i dati. Se invece il numero di sequenza del pacchetto è minore rispetto all’ultimo ricevuto presumibilmente il router mittente non ha ricevuto un aggiornamento (magari perchè il pacchetto è andato perduto), quindi il router destinazione invia il contenuto dell’ultimo pacchetto che ha ricevuto il router mittente. Infine se il numero di sequenza è invariato semplicemente il pacchetto viene scartato dato che le informazioni sono già state processate precedentemente. Alla fine tutti i router avranno a disposizione un database che sostanzialmente racchiude la topologia della rete.
A questo punto ogni router ha tutte le informazioni necessarie per calcolarsi, in maniera autonoma, i percorsi a costo minimo tra una generica sorgente e una generica destinazione. Questo calcolo viene effettuato utilizzando uno degli algoritmi shortest path first (SPF); in particolare viene utilizzato l’algoritmo di Djkstra. Questo algoritmo opera su grafi, ovvero un insieme di nodi collegati tra di loro da archi, che hanno costi positivi per ogni collegamento. Questa restrizione a costi positivi è logica in quanto non avrebbe senso imporre il costo di un certo cammino tra due router per esempio pari a -2. In questo algoritmo, implementato dal Link State, abbiamo che i nodi del grafo sono rappresentati dai router e gli archi che collegano i nodi rappresentano il percorso tra due router direttamente connessi. Il grafo dell’intera topologia della rete viene costruito partendo dalle informazioni contenute all’interno del database che ogni router possiede. La complessità dell’algoritmo di Dijkstra è quadratica, ma risulta comunque un algoritmo molto efficiente per l’individuazione di percorsi a costo minimo.
Riassumendo il protocollo Link State è molto più complesso per quanto riguarda l’implementazione rispetto all’algoritmo Distance Vector, ma riesce a gestire reti molto complesse, cosa che non riesce a fare il Distance Vector. Questa complessità dell’algoritmo porta a delle criticità dal punto di vista dell’implementazione nei router principalemnte per i seguenti fattori:
- Memoria: La conoscenza completa della topologia della rete necessita la presenza, all’interno del router, di unità di memoria abbastanza corposi.
- Capacità computazionale: E’ necessario, per l’operazione di ricerca del percorso a costo minimo, che il router sia equipaggiato da un processore che abbia una notevole capacità di calcolo. Infatti nel caso in cui la capacità di calcolo non sia sufficiente, avremo che i pacchetti, in attesa dell’instradamento, si accumulino nella coda del router generando ritardi anche consistenti.
- Banda: La fase di start-up richiede una banda suffiente a supportare volumi di traffico consistenti in quanto in questa fase tutti i router mandano in broadcast le proprie informazioni.
In sostanza i router che implementano il Link State sono router di qualità molto superiore rispetto ad altri che sono in grado di implementare solo il Distance Vector.