La programmazione sequenziale offre la garanzia che le istruzioni siano sempre eseguite in ordine, senza possibili variazioni. Il comportamento che ne deriva è di tipo deterministico: inserendo gli stessi input, si ottiene in output sempre il medesimo risultato. Per ogni programma in esecuzione il sistema operativo crea un processo cui assegna uno spazio di memoria protetto. Questo garantisce la possibilità che processi indipendenti operino simultaneamente senza che si verifichino errori.
Diversa (e più evoluta) è la programmazione concorrente. Prima di siegare cos’è e come funziona è bene introdurre, a mio avviso, un particolare tipo di oggetto Kernel chiamato Thread.
In qualità di oggetti Kernel i Thread sono gestiti dal sistema operativo, e hanno due particolarità fondamentali:
- Ogni Thread ha una struttura dati riservata, in cui viene memorizzato uno stack proprio, informazioni sulle eccezioni, prossima istruzione da eseguire;
- Ogni Thread condivide con l’intero processo una zona di memoria comune.
L’utilizzo dei Thread offre diversi vantaggi a livello di esecuzione. In particolare si sfruttano appieno le prestazioni delle CPU multi-core, le quali costituiscono attualmente la tecnologia dominante nel mercato dei personal computer. Non è pensabile che applicazioni moderne di una certa complessità siano concepite in maniera sequenziale, in tal modo potrebbero sfruttare alla volta, uno solo dei core che la macchina mette a disposizione.
Come altro vantaggio, si può notare come due processi diversi che eseguono lo stesso codice, magari con diversi parametri, hanno minore efficienza di due thread che possono sfruttare in modo diretto la memoria condivisa. In un sistema che non supporta i thread, se si vuole eseguire contemporaneamente più volte lo stesso programma, è necessario creare più processi basati sullo stesso programma. Tale tecnica funziona, ma è dispendiosa di risorse ed è più lenta.
In terzo luogo, i thread offrono vantaggio nel caso in cui vengano chiamate operazioni di I/O bloccanti: invece che attendere l’evento scatenato dall’utente fermando l’esecuzione dell’algoritmo, è possibile avviare un nuovo thread evitando un inutile tempo morto che peggiora le prestazioni globali.
Di contro la programmazione concorrente necessita del supporto dei costrutti di sincronizzazione, fondamentali per evitare che accessi casuali alla memoria condivisa causino errori in output. Inoltre espone il programmatore ad una serie nutrita di errori spesso poco prevedibili a causa del comportamento non deterministico del programma.
Oltre questo i costrutti di sincronizzazione hanno un costo, sia in termini di tempo macchina necessario ad eseguire il loro codice che soprattutto in perdita di prestazioni causata dalle attese generate dai costrutti stessi al fine di garantire la correttezza nell’esecuzione concorrente.
Gli oggetti principali che permettono la gestione della concorrenza sono anticipati di seguito e descritti per esteso nei paragrafi successivi:
- Elementi volatile
- Funzioni Interlocked
- Semafori
- Sezioni critiche
- Eventi
- Timer
- Mutex
Ognuno di questi elementi si adatta in modo naturale alla risoluzione di una classe specifica di problemi semplici. Per i problemi più complessi è sufficiente combinare gli stessi oggetti tra loro per ottenere un risultato corretto e soddisfacente; il passaggio tra la risoluzione di problemi che richiedono l’utilizzo di una sola delle primitive ed i problemi che sopra sono definiti come complessi è un punto fortemente critico. La combinazione degli oggetti di sincronizzazione può rivelarsi complicatissima, nel migliore dei casi perchè non si riesce ad ottenere una prestazione sufficientemente elevata, in un caso peggiore, perchè non si riesce a trovare facilmente la soluzione che assicura la correttezza del risultato. Non ultimo il caso pessimo: è presente un bug grave e non lo si individua immediatamente. Questo frangente è frequentissimo, sia per la delicatezza dei problemi di cui si sta trattando, sia per il fatto che il debugging in ambiente concorrente è sempre problematico, i flussi di esecuzione non sono infatti deterministici, ad ogni esecuzione del programma, l’ordine con cui il processore esegue le operazioni è sempre diverso.
Reference per le funzioni di sincronizzazione
Il reference completo, importantissimo per il programmatore che deve destreggiarsi fra le numerose funzioni di libreria che gestiscono la sincronizzazione si trova a questo indirizzo. Le funzioni citate in questo articolo sono un sottoinsieme rappresentativo e rilevante di quelle elencate nella MSDN Library al link indicato.
Elementi "volatile"
Se due thread diversi eseguono operazioni sullo stesso dato è possibile che si verifichino immediatamente questi due tipi di errori:
Un thread scrive un dato su una variabile, la quale viene letta non aggiornata da un altro thread perchè il dato stesso è stato allocato ad esempio in un registro.
Il compilatore ottimizza il codice come se questo fosse sequenziale, generando errori del tipo di quelli illustrati nell’esempio:
//Thread 1
int i=0;
dato1 = *dato_arcano;
dato2 = datoCasuale();
i=1;¯il compilatore ottimizza con:
//Thread 1
int i=1;
dato1 = *dato_arcano;
dato2 = datoCasuale();se un altro thread esegue un test per capire se i dati sono stati scritti… l’errore è alle porte. Naturalmente con una esecuzione sequenziale l’ottimizzazione non avrebbe prodotto alcun danno.
//Thread 2
while (i!=1);
[..codice..]La parola chiave volatile evita questi tipi di errori. Forza il compilatore a non fare alcun tipo di ottimizzazione sulla variabile e si assicura che un accesso alla variabile in questione avvenga realmente: volatile impedisce al compilatore di allocare una variabile in un registro, anche per un breve periodo. Questo fa si che la variabile possa essere modificata in qualsiasi momento da qualsiasi processo.
Ecco un esempio del codice concorrente corretto per il caso precedente:
//Thread 1
volatile int i=0;
dato1 = *dato_arcano;
dato2 = datoCasuale();
i=1;Creazione di un thread
Come ogni oggetto kernel in C++, i thread sono generati da una funzione del tipo Create[Oggetto](parametri). In particolare dalla funzione CreateThread, la cui definizione è citata di sotto.
HANDLE WINAPI CreateThread(
__in_opt LPSECURITY_ATTRIBUTES lpThreadAttributes,
__in SIZE_T dwStackSize,
__in LPTHREAD_START_ROUTINE lpStartAddress,
__in_opt LPVOID lpParameter,
__in DWORD dwCreationFlags,
__out_opt LPDWORD lpThreadId );In particolare i parametri indicano:
- lpThreadAttributes: contesto di sicurezza (NULL assegna quello corrente)
- dwStackSize: dimensione dello stack dedicato (0 assegna la dimensione di default)
- lpStartAddress: indirizzo della funzione principale (di ingresso)
- lpParameter: puntatore all’eventuale parametro della start routine
- dwCreationFlags: principalmente puo assumere due valori principali: 0 se il thread è attivato immediatamente oppure CREATE_SUSPENDED se lo si vuole inizializzare in attesa
- lpThreadId: parametro di uscita in cui è scritto l’ID numerico del thread
Il valore di ritorno è un HANDLE all’oggetto kernel. Tramite esso il programmatore può gestire le operazioni relative al thread.
Terminazione di un thread
La terminazione di un thread avviene nei seguenti modi:
1) Un thread appartenente al processo esegue la funzione TerminateThread();
BOOL WINAPI TerminateThread(
__inout HANDLE hThread,
__in DWORD dwExitCode);2) Il thread stesso chiama ExitThread()
VOID WINAPI ExitThread(
__in DWORD dwExitCode);3) Il thread chiama un return
In C++ è fortemente consigliato utilizzare la terza possibilità, in modo tale che gli oggetti allocati nello stack del thread vengano distrutti correttamente. Un metodo efficace per implementare questo sistema è condizionare l’esecuzione del return al valore di una variabile condivisa e dichiarata volatile, sulla quale il thread esegue il test periodicamente.
Esempio:
//Dichiarazioni globali
volatile bool ammazza_thread=false;
//Codice Thread
{
[..]
while(true)
{
if (ammazza_thread == true) return;
else
{
[..]
}
}
[..]
}
// Funzione qualsiasi del programma
[..]
ammazza_thread = true;
[..]Priorità di un thread
Il sistema operativo si occupa di gestire il multitasking, ed assegna periodicamente l’uso della CPU a thread e processi per mezzo di un suo componente detto scheduler. Ogni volta che a un thread/processo viene assegnato un suo quanto di tempo, questo ha diritto ad essere eseguito fino al termine del tempo assegnato, poi viene rimesso in coda ad attendere il suo turno.
Il flusso di esecuzione dipende fortemente dalla priorità, che in un sistema Windows è un valore numerico compreso fra 1 e 31. In ambiente multithreading, un processo contiene vari thread, la priorità effettiva del singolo thread è data dalla combinazione di due valori: priorità del processo e priorità del thread.
La priorità dei processi e dei thread è settata all’atto della creazione e può essere modificata durante l’esecuzione. In particolare, per i Thread le funzioni che gestiscono la priorità sono:
BOOL WINAPI SetPriorityClass( __in HANDLE hProcess, __in DWORD dwPriorityClass);
BOOL WINAPI SetThreadPriority( __in HANDLE hThread, __in int nPriority);Modificare le priorità rispetto ai valori di default può essere deleterio e costituisce un’operazione critica. Elevarla troppo può dare origine all’eccessivo consumo di CPU da parte del thread a scapito di operazioni critiche del sistema, abbassarla oltre il dovuto può dare origine a fenomeni di starvation, tali per cui il thread non viene mai eseguito perchè nella coda dei thread in attesa ce n’è sempre un altro con priorità maggiore che viene schedulato al suo posto.
I valori dwPriorityClass e nPriority assumono valori mnemonici che consistono in costanti standard (differenti per i processi e per i thread). Come anticipato dalle righe precedenti, per definire la priorità globale si combinano i valori per darne origine ad uno nuovo compreso fra 1 e 31.
Ecco un campione rappresentativo di queste costanti, l’elenco completo è interamente tabulato nella MSDN library alla sezione relativa alle ultime due funzioni citate: SetPriorityClass e SetThreadPriority.
| Valore costante | Significato |
| HIGH_PRIORITY_CLASS | Priorità del processo: alta |
| IDLE_PRIORITY_CLASS | Priorità del processo: minima |
| THREAD_PRIORITY_ABOVE_NORMAL | Priorità del processo: superiore al normale |
| THREAD_PRIORITY_NORMAL | Priorità del thread: normale |
| THREAD_PRIORITY_LOWEST | Priorità del thread: bassissima |
| THREAD_PRIORITY_TIME_CRITICAL | Priorità del thread: in tempo reale |
Sincronizzazione
Esistono diversi costrutti di sincronizzazione che garantiscono l’accesso sicuro alla risorsa in diverse maniere e per diversi tipi di errore. E’ compito del programmatore effettuare la scelta migliore su quali usare caso per caso, tenendo conto del contesto, dei vantaggi offerti dalla soluzione scelta e dei suoi svantaggi. In prima istanza, per evitare gli errori, è necessario che le scritture su uno stesso oggetto siano eseguite da un solo thread alla volta. Inoltre le operazioni di aggiornamento su un oggetto devono essere sempre atomiche (indivisibili), ovvero non consentono l’esecuzione di altre operazioni per tutta la durata della la loro esecuzione.
Gli errori di interferenza avvengono quando una operazione viola questo concetto. Un breve esempio può essere il seguente:
int risultato=0;
//Codice Thread
for (int i=0; i<500000; i++) risultato++;
//Fine codice threadEseguendo concorrentemente due thread caratterizzati da un codice del tipo illustrato sopra, la non atomicità dell’incremento su ‘risultato’ farà in modo che il valore finale sia quello sbagliato (provare per credere..), sebbene eseguendo sequenzialmente due volte lo stesso codice, non ci sia possibilità alcuna di errore.
Dichiarare la variabile risultato volatile non è sufficiente a risolvere i problemi, perchè la causa dell’errore è da ricercarsi nella non atomicità della variabile in questione.
Quest’ultimo concetto è fondamentale nel caso di dati mutabili. I dati immutabili invece non sono soggetti ad errori di interferenza. Si ricorda che un dato è immutabile quando l’oggetto che lo rappresenta non può essere cambiato dopo la sua creazione.
Funzioni Interlocked
Il costrutto più semplice di sincronizzazione consiste nell’utilizzo diretto di alcune funzioni speciali chiamate interlocked. Le funzioni interlocked eseguono col massimo dell’efficienza (relativamente all’ambito della programmazione concorrente) alcune azioni comuni in modo atomico come incremento, decremento e scambio. Di seguto un esempio di alcune di queste funzioni:
- InterlockedIncrement( long volatile * );
- InterlockedDecrement( long volatile * );
- InterlockedCompareExchange( long volatile *, long, long );
- InterlockedExchange( long volatile *, long );
- InterlockedExchangeAdd( long volatile *, long );
Come prova tangibile dell’utiltà delle funzioni interlocked convertiamo l’esempio precedente in qualcosa di funzionante:
//Codice Thread
for (int i=0; i<500000; i++) InterlockedIncrement(risultato);
//Fine codice threadSemafori
Un semaforo è un oggetto kernel che può essere immaginato come un particolare tipo di contatore, il quale può assumere tutti i valori interi positivi e lo zero.
Sul semaforo sono possibili due tipi fondamentali di operazioni:
- Wait: decrementa il valore del contatore se questo era positivo e va avanti, altimenti, in caso di valore nullo, aspetta finchè qualcuno non incrementa il valore del contatore.
- Release: incrementa il valore del contatore.
Inizializzare il semaforo ad 1 o ad un valore positivo può risolvere tipologie di problemi diverse:
- Utilizzo esclusivo di una risorsa.
- Concessione di risorse disponibili in quantità limitata.
Soprattutto la seconda tipologia di problemi trova spesso nei semafori la miglior soluzione. I semafori sono gestiti mediante le funzioni C++ CreateSemaphore, OpenSemaphore, WaitForSingleObject, ReleaseSemaphore.
I prototipi delle funzioni principali sono:
HANDLE WINAPI CreateSemaphore(__in_opt LPSECURITY_ATTRIBUTES
lpSemaphoreAttributes, __in LONG lInitialCount, __in LONG
lMaximumCount, __in_opt LPCTSTR lpName);
HANDLE WINAPI OpenSemaphore(__in DWORD dwDesiredAccess,
__in BOOL bInheritHandle, __in LPCTSTR lpName);
DWORD WINAPI WaitForSingleObject( __in HANDLE hHandle,
__in DWORD dwMilliseconds);
BOOL WINAPI ReleaseSemaphore( __in HANDLE hSemaphore,
__in LONG lReleaseCount, __out_opt LPLONG lpPreviousCount);Sezioni critiche
Una sezione critica è una parte di codice che può essere eseguita da un solo processo o thread alla volta. Tutte le operazioni effettuabili su una sezione critica sono implementate da librerie standard C++. Tramite chiamate dirette il programmatore ha il compito di gestire le seguenti quattro operazioni fondamentali:
- Inizializzazione
- Entrata
- Uscita
- Rilascio
Esempio di utilizzo della sezione critica:
static CRITICAL_SECTION cs;
[..]
/* Inizializza la sezione critica. */
InitializeCriticalSection(&cs);
[..]
void codiceThread()
{
/* Entra nella sezione critica: gli altri thread che
vogliono entrarci dovranno attendere */
EnterCriticalSection(&cs);
/* Codice operativo del thread*/
/* Esci dalla sezione critica */
LeaveCriticalSection(&cs);
}
[..]
/*Rilascia la risorsa acquisita*/
DeleteCriticalSection(&cs);Uno stesso thread può entrare più di una volta in una sezione critica, quando questo accade viene incrementato un contatore; sarà poi necessario rilasciarla tante volte quanti sono stati gli ingressi, e ad ogni accesso corrisponderà un decremento.
Due consigli utili:
1) Limitiamo fortemente la quantità di codice eseguito all’interno di una sezione critica. Quel codice infatti non è eseguito in concorrenza, le prestazioni diminuiscono moltissimo.
2) Se dall’interno di una sezione critica si entra in un’altra (cosa da evitare sempre se possibile) bisogna fare attenzione all’ordine in cui si effettua il rilascio. Un errore in questa fase è fonte di problemi gravissimi di tipo deadlock (attesa infinita reciproca, il processo va in blocco eterno). Questo è il modo corretto di farlo:
EnterCriticalSection(&cs1);
EnterCriticalSection(&cs2);
// Codice...
LeaveCriticalSection(&cs2);
LeaveCriticalSection(&cs1);Mutex
Offrono l’accesso in mutua esclusione ad una risorsa, alla stregua delle sezioni critiche. La differenza sta nel fatto che un mutex è un oggetto kernel. A livello operativo, se un thread che possiede il mutex termina, il mutex viene resettato. D’altra parte garantisce prestazioni fortemente peggiori rispetto all’utilizzo della semplice sezione critica.
Le funzioni che gestiscono i Mutex hanno sintassi molto simile a quella degli altri oggetti appena visti ed hanno il significato gia enunciato di creazione, ingresso e rilascio:
HANDLE WINAPI CreateMutex( __in_opt LPSECURITY_ATTRIBUTES
lpMutexAttributes, __in BOOL bInitialOwner, __in_opt LPCTSTR lpName);
HANDLE WINAPI OpenMutex(__in DWORD dwDesiredAccess,
__in BOOL bInheritHandle, __in LPCTSTR lpName);
BOOL WINAPI ReleaseMutex(__in HANDLE hMutex);Eventi
Gli eventi sono un particolare tipo di oggetto kernel che decretano con il loro stato quello dei thread in attesa. Si noti che un thread entra nello stato di attesa chiamando una funzione di Wait (esempio: WaitForSingleObject). Lo stato di un evento può assumere due soli valori:
- Segnalato: un thread in stato di attesa può finire di aspettare e continuare la sua esecuzione
- Non Segnalato: tutti gli elementi in attesa mantengono il loro stato
Gli eventi sono di tipo MANUAL_RESET se quando entrano nello stato non segnalato svegliano tutti i thread in attesa su quell’evento finchè non viene eseguito un reset manuale che forza sull’oggetto event lo stato non segnalato, di tipo AUTO_RESET se, non appena viene svegliato il primo thread, viene assegnato immediatamente lo stato non segnalato
Le funzioni che operano sugli eventi sono:
- CreateEvent: crea un nuovo evento
- OpenEvent: si collega ad un evento gia esistente
- SetEvent: l’evento passa allo stato segnalato
- ResetEvent: reset manuale, passa immediatamente allo stato non segnalato
- PulseEvent: se l’evento è di tipo MANUAL_RESET tutti i thread in attesa vengono rilasciati e l’evento passa allo stato non segnalato; se l’evento è di tipo AUTO_RESET solamente uno dei thread è rilasciato. Se nessun thread è in attesa non succede niente, la chiamata non ha effetto.
HANDLE WINAPI CreateEvent(__in_opt LPSECURITY_ATTRIBUTES
lpEventAttributes, __in BOOL bManualReset, __in BOOL
bInitialState, __in_opt LPCTSTR lpName);
HANDLE WINAPI OpenEvent(__in DWORD dwDesiredAccess,
__in BOOL bInheritHandle, __in LPCTSTR lpName);
BOOL WINAPI SetEvent(__in HANDLE hEvent);
OOL WINAPI ResetEvent(__in HANDLE hEvent);
BOOL WINAPI PulseEvent(__in HANDLE hEvent);Timer
Allo stesso modo degli Eventi, esistono oggetti kernel di tipo timer il cui stato (segnalato/non segnalato) produce gli stessi effetti, ma dipende da alcune condizioni relative all’orologio di sistema, di cui ne vengono riportate alcune significative.
- Il timer entra nello stato segnalato allo scoccare di coordinate temporali specifiche (es: il 25 dicembre 2013 alle 23:57)
- Il timer entra nello stato segnalato ad intervalli regolari (es: ogni 40 secondi)
Come nel caso degli eventi sono previsti i timer di tipo AUTO_RESET e MANUAL_RESET, il cui comportamento si mantiene lo stesso.
Le seguenti funzioni gestiscono gli oggetti di tipo Timer:
Thread Pool
la gestione manuale dei thread può essere difficilissima a causa di alcune variabili di cui il programmatore si deve prendere cura ma che non sono sempre sotto il suo controllo. Si risponda ad esempio alle seguenti domande:
- Qual’è il numero di thread ideale che ottimizza le prestazioni del sistema?
- Quanto si perde in termini di prestazioni nel creare un thread?
Per quanto concerne la prima domanda la risposta è: "dipende dal sistema". Il numero di thread ottimale dipende infatti non solo dalla qualità del codice eseguito dal thread, ma anche dall’hardware della macchina su cui si sta lavorando (quantità di RAM, numero di core della CPU ecc..). In secondo luogo creare un nuovo thread ha un costo iniziale alto, circa tre ordini di grandezza superiore rispetto alla semplice chiamata di funzione. Il sistema operativo, per aiutare il programmatore a risolvere questi due problemi supporta un oggetto kernel denominato Thread Pool, il quale consiste in una coda di thread che vengono mandati in esecuzione progressivamente, in concorrenza, con parallelismo scelto dal sistema e con risorse preallocate (ma anche con tempistica di esecuzione decisa dal sistema: si sa che il lavoro accodato sarà eseguito, ma non si hanno garanzie sul quando).
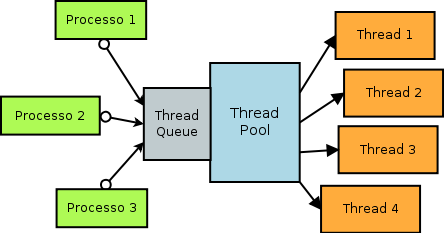
Si hanno cosi prestazioni almeno 10 volte migliori in termini di tempi di creazione del singolo Thread e un numero di thread mandati in esecuzione parallelamente, congruo alle caratteristiche della macchina su cui il programma viene eseguito. Come svantaggio si ha che l’accodamento di un lavoro al ThreadPool non è una operazione reversibile.
L’unica chiamata che cito, sufficiente ad operare a livello base con il thread pool è la seguente:
QueueUserWorkItem((LPTHREAD_START_ROUTINE)codiceThread,
(PVOID)parametro , WT_EXECUTEDEFAULT);essa accoda un thread al Thread Pool.