Nella scrittura del codice delle proprie applicazioni uno sviluppatore dovrebbe sempre seguire standard di codifica e convenzioni, al fine di implementare algoritmi efficienti ed eventualmente comprensibili anche ad altri sviluppatori. Per questo motivo, nel presente articolo, vedremo alcuni semplici accorgimenti per la scrittura di codice efficiente in C#.
Partiamo da un semplice esempio, un programmino che scorre i numeri da 1 a 1000. Scorrendo i numeri per ogni multiplo di 3 restituisce il messaggio ‘Multiplo di 3’, per ogni multiplo di 5 restituisce ‘Multiplo di 5’ e per ogni multiplo di entrambi restituisce ‘Multiplo di 3 Multiplo di 5’. Se non si verifica alcuna delle tre condizioni viene restituito semplicemente il numero corrente.
Una possibile implementazione del metodo è la seguente
public void Test()
{
for (int i = 1; i < 1001; i++)
{
if (i % 3 == 0 && i % 5 == 0)
{
Console.WriteLine("Multiplo di 3 Multiplo di 5");
}
else if (i % 3 == 0)
{
Console.WriteLine("Multiplo di 3");
}
else if (i % 5 == 0)
{
Console.WriteLine("Multiplo di 5");
}
else
{
Console.WriteLine(i);
}
}
}Ovviamente il metodo fa quello che ci siamo prefissati ma potremmo scrivere il tutto nel modo seguente
public void Test2()
{
for (int i = 1; i <= 1000; i++)
{
string output = "";
if (i % 3 == 0) { output = "Multiplo di 3"; }
if (i % 5 == 0) { output = output + " Multiplo di 5"; }
if (output == "") { output = i.ToString(); }
Console.WriteLine(output);
}
}Vi sembrano abbastanza comprensibili?
Uno dei problemi fondamentali della programmazione è dare il giusto (nel senso di comprensibile ed appropriato) nome agli elementi che compongono le applicazioni. Uno sviluppatore tipicamente si trova a dover dare un nome a proprietà, metodi, classi, file, progetti e tante altre cose. Pur essendo un’attività che richiede del tempo, si dovrebbe sempre dedicare il giusto tempo ad essa perché utilizzare i nomi giusti rende il codice più leggibile e comprensibile.
Lo stesso risultato dei due esempi precedenti possiamo ottenerlo scrivendo il seguente codice
public void EseguiTest()
{
for (int numero = 1; numero <= 1000; numero++)
{
var output = Test3(numero);
Console.WriteLine(output);
}
}
private static string Test3(int numero)
{
string output = string.Empty;
if (numero % 3 == 0)
{
output = "Multiplo di 3";
}
if (numero % 5 == 0)
{
output += " Multiplo di 5";
}
if (string.IsNullOrEmpty(output))
{
output = numero.ToString();
}
return output;
}E’ più comprensibile dei due casi precedenti?
Il codice prima di tutto deve essere scritto per le persone (intese come altri programmatori) e solo dopo per le macchine. Un codice leggibile non richiede molto tempo per essere compreso, al contrario di un codice poco chiaro. Spesso gli sviluppatori programmano senza tenere conto che il proprio codice potrà essere letto da altri per vari motivi: per correggere un errore, per effettuare modifiche, per provare ad utilizzarne parte in un progetto simile, ecc.
A parte queste motivazioni, scrivere codice leggibile serve anche in primis a chi lo scrive. Coloro che lavorano in realtà in cui ogni una o due settimane si passa all’implementazione di un progetto nuovo saprà che dopo un certo periodo di tempo i dettagli dei progetti precedenti fisiologicamente vengono in parte dimenticati.
Quindi quando si riprende un vecchio progetto trovarsi di fronte ad un codice confuso e poco leggibile farà soltanto perdere tempo prezioso, perché ci costringerà a ricostruire cosa fa quel codice. Al contrario un codice ben scritto (e ben commentato aggiungo) ci richiederà uno sforzo iniziale, ma ci permetterà di ricordare facilmente tutti i dettagli dello stesso, aumentando anche la nostra produttività.
Ma come si può valutare la leggibilità di un codice? Il primo consiglio che vi do è leggere il codice scritto da altri sviluppatori e capire cosa è chiaro e cosa non lo è in esso. Le cose che vi sembrano più comprensibili provate ad applicarle al vostro modo di scrivere codice, quelle poco chiare no. Chiaramente poi è necessaria una certa esperienza per migliorare in questo ambito, nessuno sviluppatore con esperienza scrive lo stesso codice che scriveva all’inizio della sua carriera.
Esistono anche alcuni tool che permettono di valutare la leggibilità del codice e tra questi citiamo:
- FxCop: strumento che effettua un’analisi statica del codice .NET e consente vari tipi di valutazioni.
- StyleCop: progetto open source che analizza il codice sorgente C# forzando una serie di regole di stile e consistenza. Esso può essere utilizzato anche all’interno di Visual Studio.
- JetBrains ReSharper: strumento di produttività che migliora molto l’esperienza di programmazione in Visual Studio, mettendo a disposizione tantissime utili funzionalità.
Passiamo adesso alle convenzioni, termine con cui si designa un insieme di linee guida relative ad un linguaggio di programmazione. Esse riguardano indentazione, commenti, dichiarazioni, istruzioni, assegnazione dei nomi, principi di programmazione, ecc. Agli sviluppatori è fortemente raccomandato seguire tali linee guida per migliorare la leggibilità del proprio codice e quindi facilitare la manutenzione del software.
Tra le varie convenzioni una molto importante è quella relativa all’utilizzo delle lettere maiuscole nell’assegnazione dei nomi agli elementi (si parla di capitalization, da capital letter ovvero lettera maiuscola). Una proprietà, una variabile, il nome di un metodo o di una classe dovrebbero essere scelti tenendo conto di alcune convenzioni.
In particolare si parla di Pascal Casing e Camel Casing. Nel primo caso la in un identificatore la prima lettera in assoluto e la prima lettera di ogni parola concatenata sono maiuscole, nel secondo caso la prima lettera in assoluto è minuscola e la prima lettera di ogni parola concatenata è maiuscola. Microsoft consiglia l’utilizzo del Camel per i parametri e le variabili locali e del Pascal per classi, eventi, metodi, proprietà, ecc.
Vediamo alcuni accorgimenti su capitalization e altro:
Utilizzare il Pascal per gli identificatori di classi e nomi di metodi
public class Dipendenti
{
public void EstraiDipendenti()
{
//...
}
public void CalcolaCostoDipendenti()
{
//...
}
}Utilizzare il Camel per gli argomenti di un metodo e come identificatori di variabili locali
public class CategorieDipendenti
{
public void Salva(CategorieDipendenti categoriaDipendente)
{
string codiceAzienda;
// ...
}
} Non utilizzare abbreviazioni
//Consigliato
CategorieDipendenti categoriaDipendente;
//Sconsigliato
CategorieDipendenti catDip;Non utilizzare il trattino basso (underscore) negli identificatori
//Consigliato
CategorieDipendenti categoriaDipendente;
//Sconsigliato
CategorieDipendenti categoria_Dipendente;Dichiarare tutte le variabili all’inizio di una classe, con le variabili statiche prima di tutte le altre
public class Dipendenti
{
public static string Cognome;
public static string Nome;
public string Sesso { get; set; }
public DateTime DataAssunzione { get; set; }
public Dipendenti()
{
// ...
}
}Utilizzare nomi al singolare per gli enum e non utilizzare il suffisso ‘Enum’
//Consigliato
public enum Ruolo
{
Operaio,
Amministrativo,
Dirigente
}
//Sconsigliato
public enum Ruoli
{
Operaio,
Amministrativo,
Dirigente
}
//Sconsigliato
public enum RuoloEnum
{
Operaio,
Amministrativo,
Dirigente
}Le convenzioni comportano diversi vantaggi, in particolare stabilendo dall’inizio le regole per la definizione degli identificatori è possibile concentrarsi su aspetti funzionali più importanti del codice.
Un altro consiglio per la scrittura di codice leggibile ed efficiente riguarda le dimensioni delle classi. Spesso infatti capita di vedere (o implementare) classi veramente molto estese. Questo non va bene perché classi di questo tipo cercano di effettuare troppe cose diverse. Un principio molto importante (principio di singola responsabilità) sostiene che ogni classe dovrebbe avere una singola responsabilità e tale responsabilità dovrebbe essere incapsulata nella classe.
Un esempio su questo aspetto che circola in rete è il seguente:
Si consideri un modulo che compila e stampa un report. Tale modulo può cambiare per due motivi. In primo luogo il contenuto del report può cambiare. In secondo luogo il formato del report può cambiare. Queste due cose cambiano per cause molto diverse: uno sostanziale e uno estetico. Il principio di singola responsabilità afferma che questi due aspetti del problema sono in realtà due responsabilità distinte e dovrebbero quindi essere descritte in classi o moduli separati. Sarebbe cattiva progettazione accoppiare due cose che cambiano, per motivi diversi in momenti diversi. Se vi è un cambiamento nel processo di compilazione del report, ci saranno maggiori probabilità che il codice per la stampa fallisca se si trova nella stessa classe.
Quindi in sintesi se una classe ha più di una responsabilità, queste risultano legate tra di loro e la modifica di un elemento relativo ad una delle responsabilità potrebbe avere conseguenze sul funzionamento di altre responsabilità, che invece dovrebbero essere indipendenti dalla prima.
Altro aspetto da considerare nella scrittura del codice sono i commenti. Questi sono spesso molto importanti per la comprensione del codice ma non bisogna abusarne. Bisognerebbe, ad esempio, evitare commenti su singoli metodi o piccole classi perché in questi casi il nome del metodo o della classe dovrebbero già avere un significato ben preciso se scelti bene e non dovrebbero necessitare di commenti.
Questo non significa che i commenti non siano importanti ma è consigliabile scriverli a livello di applicazione complessiva non a livello dei singoli metodi. Un codice troppo commentato probabilmente è un cattivo codice perché necessita di troppe spiegazioni per essere comprensibile da altri.
Passiamo adesso ai metodi. La maggior parte di sviluppatori con esperienza raccomanda che la lunghezza di un metodo non dovrebbe mai superare le 20-25 linee di codice. Quindi quando un metodo supera questo limite o necessita di troppi commenti per essere compreso è il momento di chiedersi se non sia meglio suddividerlo in più parti.
Visual Studio mette a disposizione una utile funzionalità denominata ‘Extract Method’ che consente di selezionare una porzione di codice ed inglobarla in un metodo esterno a quello in cui si trovava
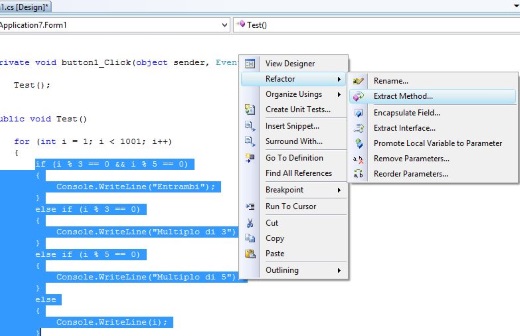
Altro aspetto da considerare è che quando si opera su metodi molto lunghi e complessi tenere traccia di tutte le variabili locali può essere complicato e dispendioso in termini temporali.
Anche il numero di parametri è importante. Quando in un metodo si arrivano ad inserire troppi parametri bisogna valutare se non sia meglio creare una classe che mette tutti questi parametri assieme e poi passare come parametro del metodo un’istanza di tale classe
//Sconsigliato
public void Spedizione(string nomeDestinatario,string cittaDestinatario,
string statoDestinatario,string codicePostaleDestinatario,
string telefonoDestinatario)
{
}
//Consigliato
public void Spedizione(Destinatario destinatario)
{
} Nel caso precedente abbiamo sostituito cinque parametri con un solo parametro corrispondente ad una classe che contiene cinque proprietà corrispondenti ai parametri del primo metodo.
Spesso mentre scriviamo codice riscontriamo dei warning ma siccome non sono bloccanti nella quasi totalità dei casi essi finiscono per essere ignorati. Un caso tipico è la dichiarazione di una variabile che poi non viene utilizzata all’interno del codice

E’ consigliabile rimuovere dal codice oltre agli errori anche i warning e per essere in qualche modo ‘costretti’ a farlo è possibile impostare Visual Studio in modo da bloccare la compilazione del nostro codice anche se sono presenti solo warning.
Basta accedere alle proprietà del progetto e selezionare la scheda Build
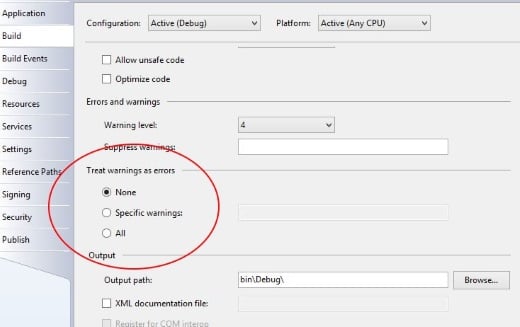
In questa scheda è presente una sezione denominata ‘Treat warnings as errors’ con il valore predefinito None. Tutto quello che dobbiamo fare è impostare il valore All e quello che in precedenza ci compariva come warning comparirà come errore

Nel presente articolo abbiamo analizzato alcuni semplici ma efficaci accorgimenti per rendere il nostro codice più efficiente e leggibile. Ovviamente è possibile adottare tanti altri accorgimenti che vanno in questa direzione e che probabilmente saranno oggetto di futuri articoli, ma mettere in pratica quelli che abbiamo qui descritto rappresenta un primo ed importante passo verso la scrittura di codice leggibile ed efficiente.