
Google DeepMind, centro di ricerca avanzato sull’intelligenza artificiale di Google, ha sviluppato e introdotto un innovativo sistema di watermark per identificare i testi generati da IA.
Questo sistema, distribuito su larga scala attraverso il modello linguistico Gemini, è stato pensato per distinguere i contenuti sintetici da quelli umani.
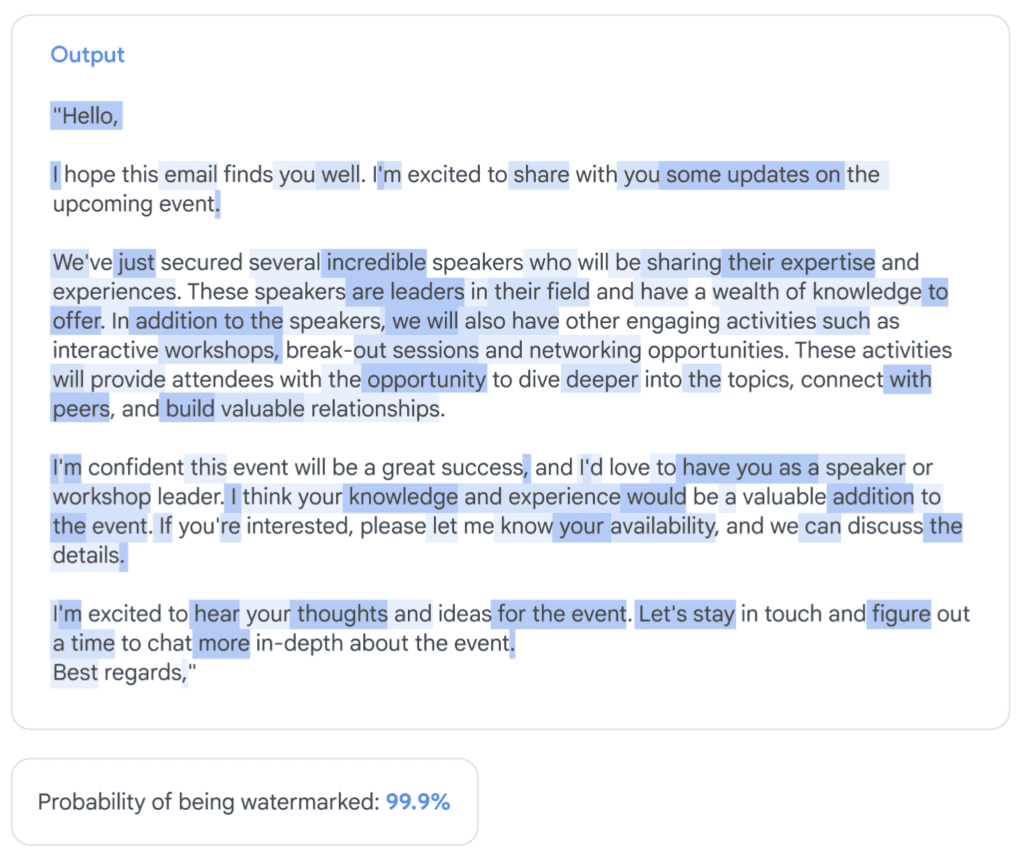
Denominato SynthID, il sistema permette di riconoscere contenuti generati dall’intelligenza artificiale tramite una marcatura invisibile criptata che può essere rilevata solo usando una specifica chiave crittografica.
Secondo quanto dichiarato dai tecnici di Google l’aggiunta del watermark non influirebbe sulla qualità del testo nè rallenterebbe la sua generazione.
Come funziona SynthID per il Testo Generato da IA
Di seguito il testo (tradotto in italiano) che compare sul sito ufficiale della tecnologia SynthID:
Un modello linguistico di grandi dimensioni (LLM) genera testo un token alla volta, dove i token possono rappresentare un singolo carattere, una parola o parte di una frase. Per produrre un testo coerente, il modello prevede il token successivo più probabile basandosi sui termini precedenti e sui punteggi di probabilità assegnati a ciascun token possibile.
Ad esempio, data la frase “I miei frutti tropicali preferiti sono __.”, il sistema potrebbe completarla con i token “mango”, “lichi”, “papaya” o “durian”, ciascuno con un proprio punteggio di probabilità. Quando sono disponibili vari token tra cui scegliere, SynthID può modificare il punteggio di probabilità di ciascun token previsto, purché ciò non comprometta la qualità, accuratezza e creatività del risultato.
Questo processo viene ripetuto in tutto il testo generato: una singola frase può contenere dieci o più punteggi di probabilità regolati, e una pagina intera può arrivare a contenerne centinaia. Il watermark finale è costituito dal modello dei punteggi assegnati sia alle scelte del modello che ai punteggi probabilistici regolati. Questa tecnica può essere applicata su un minimo di tre frasi, e l’efficacia e la robustezza di SynthID aumentano all’aumentare della lunghezza del testo.
Perché applicare un Watermark ai contenuti generati da IA?
Questa tecnologia rappresenta una delle prime applicazioni su larga scala di watermark nei chatbot, con l’obiettivo di fornire uno strumento utile per distinguere i contenuti artificiali da quelli prodotti da autori umani.
La capacità di identificare chiaramente i testi generati da IA è vista come una risorsa importante per contrastare la disinformazione e il rischio di plagio in ambito accademico, scientifico, culturale e in altri settori.
L’uso del watermark è inoltre fondamentale per proteggere i processi di addestramento degli stessi modelli linguistici: se le IA venissero addestrate su testi generati da loro stesse, si creerebbe una situazione rischiosa, in cui errori e imprecisioni si propagherebbero esponenzialmente, compromettendo l’accuratezza dei futuri modelli.
Sfide e limiti delle tecniche di Watermark dei contenuti generati da AI
Google ha reso SynthID disponibile agli sviluppatori mantenendo tuttavia segreta la chiave di rilevamento, per incoraggiare l’adozione della tecnologia anche da parte di altre aziende.
L’uso di watermark come discriminante della provenienza di un testo, tuttavia, deve essere valutato attentamente: il rischio di falsi positivi, infatti, non è trascurabile così come la possibilità che i modelli di identificazione possano essere elusi con tecniche di manipolazione o software progettati per rimuovere il watermark, che potrebbero essere sviluppati in futuro.
Più in generale, l’uso dell’intelligenza artificiale nella produzione di contenuti richiede consapevolezza e responsabilità da parte di chi la utilizza. Sebbene rappresenti un potente supporto per autori e creatori, l’IA non dovrebbe mai sostituire completamente l’apporto umano nel processo creativo. In quest’ottica, strumenti capaci di identificare con precisione i contenuti generati da IA potrebbero rivelarsi preziosi per garantire trasparenza e autenticità.