In questa lezione vedremo cos’è e come funziona lo " Sharding".
Cos’è lo "Sharding" in MongoDB
Col termine "Sharding" ci si riferisce al meccanismo di partizionamento dei dati di una collezione su diverse macchine. Non è un termine esclusivo di MongoDB, ma si tratta di una funzionalità utilizzabile anche in altri sistemi di gestione di database. Ciò che differenzia però MongoDB è la relativa semplicità con cui attivare e gestire la frammentazione dei dati. Inoltre, dal punto di vista di un’applicazione non cambia più di tanto il modo in cui vengono effettuate le interrogazioni. È come se si stessero inviando comunque le richieste ad un’istanza di mongod, così come abbiamo visto nei precedenti esempi, solo che in questo caso a rispodere è un processo diverso detto mongos che provvede a ricevere le interrogazioni del client e ad indirizzarle verso la macchina che contiene i dati.
Vedremo a breve di descrivere in maggiore dettaglio l’architettura impiegata in questi casi, ma prima occorre soffermarci un momento per capire qual è il motivo che porta ad attivare lo "Sharding" per distribuire i documenti di una collezione su macchine diverse.
Quando le dimensioni di un set di dati cresce di dimensioni a tal punto che una macchina non è più in grado di gestirlo, abbiamo a disposizione due possibili soluzioni:
- Scalabilità verticale
- Scalabilità orizzontale
La Scalabilità verticale è probabilmente la prima opzione da valutare e consiste nell’aumentare le capacità di una macchina migliorando le prestazioni e/o espandendo la capacità di archiviazione.
Il problema di questa alternativa è che ad un certo punto può risultare eccessivamente costoso continuare ad aggiornare una macchina o ancora peggio, se un database raggiunge dimensioni notevoli, può succedere che non esistano proprio in commercio dei componenti in grado di soddisfare i requisiti necessari.
In questi casi, invece di incrementare le capacità di una singola macchina, si procede a distribuire il set di dati su più macchine. Si parla allora di scalabilità orizzontale.
Architettura di uno "Sharded Cluster"
MongoDB è un sistema di gestione di database creato appositamente per la scalabilità orizzontale.
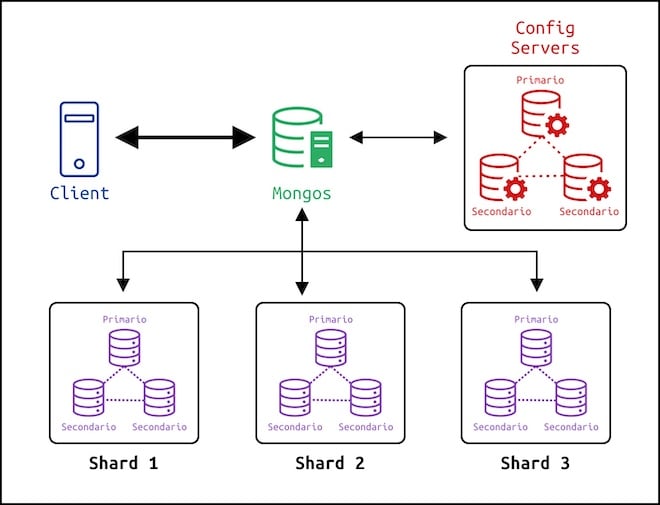
Grazie allo "Sharding" i documenti di una collezione sono raggruppati in blocchi detti chunks e vengono distribuiti su diverse macchine dette shards. Per garantire un certo livello di disponibilità dei dati e tolleranza in caso di guasti, al posto di singoli server possono essere impiegati dei Replica Set. L’insieme di questi shard forma quello che viene chiamato Sharded Cluster.
Per rendere questa complessa architettura invisibile al client, è presente un processo detto Mongos che si occupa di indirizzare le interrogazioni verso il corretto shard. Nel caso in cui i documenti fossero distribuiti in shard diversi, Mongos si occupa di inviare le query verso ciascun gruppo di server, unire le risposte ricevute nel modo corretto e di restituire poi al client il risultato finale.
Per capire dove deve essere indirizzata una query, Mongos usa dei metadati che descrivono in che modo sono stati distribuiti i blocchi di documenti nei vari shard. Queste informazioni non sono mantenute però da Mongos, al contrario la collezione dei metadati viene salvata nei server di configurazione che in ogni istante mantengono traccia di dove risiede ogni dato nel cluster.
Ciò è particolarmente importante perché i dati contenuti in ogni shard potrebbero cambiare nel tempo e potrebbero essere trasferiti da uno shard all’altro al fine di mantenere sempre una distribuzione costante delle informazioni. In caso contrario, se i documenti contenuti in uno shard crescessero in maniera incontrollata, si rischierebbe di sovraccaricare un solo "Replica Set".
Visto che il modo in cui sono distribuiti i dati può variare nel tempo, mongos interroga i server di configurazione con una certa frequenza, per sapere in ogni istante se e dove sono stati spostati dei documenti.
I server di configurazione provvedono inoltre a selezionare uno shard primario all’interno dello Sharded Cluster. Lo shard primario ha diverse peculiarità e responsabilità fra cui mantenere tutte le collezioni del database che non sono state partizionate. Infatti vedremo a breve che, una volta configurato il cluster, dovremo abilitare il processo di frammentazione di una collezione e non tutte le collezioni devono per forza essere partizionate.
Configurare uno "Sharded Cluster"
Facendo riferimento all’immagine riportata sopra riguardo l’architettura di uno "Sharded Cluster", vediamo come configurarne uno.
Per semplicità lanceremo tutte le istanze di mongod su un’unica macchina.
Prima di tutto definiamo in una nuova cartella la struttura delle sottocartelle in cui salvare i file di configurazione, i file di log, e i dati del database.
tree -FL 2 .
./
├── config-servers/
│ ├── config-server-1.conf
│ ├── config-server-2.conf
│ └── config-server-3.conf
├── db/
│ ├── config-server-1/
│ ├── config-server-2/
│ ├── config-server-3/
│ ├── mongos.log
│ ├── sh1/
│ ├── sh2/
│ └── sh3/
├── key/
│ └── repl-keyfile
├── mongos.conf
├── sh1/
│ ├── sh1-node1.conf
│ ├── sh1-node2.conf
│ └── sh1-node3.conf
├── sh2/
│ ├── sh2-node1.conf
│ ├── sh2-node2.conf
│ └── sh2-node3.conf
└── sh3/
├── sh3-node1.conf
├── sh3-node2.conf
└── sh3-node3.conf
12 directories, 15 filesNella directory base abbiamo creato una cartella key la quale contiene un file che useremo per l’autenticazione fra i membri dei "Replica Set".
Abbiamo poi 4 cartelle: sh1, sh2, sh3 e config-servers in cui abbiamo inserito i file di configurazione delle diverse istanze di mongod. Le prime 3 cartelle sono relative ad altrettanti shard ognuno dei quali consisterà di 3 istanze di mongod configurate per formare un "Replica Set". La cartella config-servers contiene invece i file di configurazione per il "Replica Set" di configurazione.
Nella cartella base troviamo poi il file mongos.conf che useremo per eseguire un’istanza di mongos la quale fornisce un’interfaccia fra il client e il cluster.
È presente infine una cartella db con delle sottocartelle in cui salveremo i dati delle varie istanze di mongod.
Vediamo allora come configurare i diversi componenti.
Passo 1: Creare un keyfile
Per creare un keyfile di 1024 caratteri pseudocasuali che useremo per l’autenticazione fra i server dei "Replica Set", eseguiamo il comando openssl nella cartella base.
openssl rand -base64 756 > key/repl-keyfileSu Linux e macOS modifichiamo i permessi per consentire esclusivamente la lettura del file al solo proprietario.
chmod 400 key/repl-keyfilePasso 2: Creare ed avviare un "Replica Set" per i server di configurazione
Partiamo con la configurazione dei server di configurazione ed editiamo quindi i file config-server-1.conf, config-server-2.conf, config-server-3.conf.
Il file config-server-1.conf è il seguente:
storage:
dbPath: /path/to/db/config-server-1
net:
bindIp: localhost
port: 28001
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/config-server-1/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-config
sharding:
clusterRole: configsvrRispetto alla precedente lezione in cui abbiamo visto come creare un "Replica Set" non c’è nulla di nuovo a parte l’opzione sharding.clusterRole pari a configsvr. Questa indica che si tratta di un’istanza di un server di configurazione di uno "Sharded Cluster".
I file config-server-2.conf e config-server-3.conf sono uguali a parte il fatto che dobbiamo modificare i percorsi di storage.dbPath e systemLog.path e dobbiamo selezionare una diversa porta visto che le istanze di mongod saranno in esecuzione sulla stessa macchina.
storage:
dbPath: /path/to/db/config-server-2
net:
bindIp: localhost
port: 28002
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/config-server-2/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-config
sharding:
clusterRole: configsvrconfig-server-3.conf:
storage:
dbPath: /path/to/db/config-server-3
net:
bindIp: localhost
port: 28003
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/config-server-3/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-config
sharding:
clusterRole: configsvrA questo punto possiamo eseguire le 3 istanze di mongod:
mongod --config config-servers/config-server-1.conf
mongod --config config-servers/config-server-2.conf
mongod --config config-servers/config-server-3.confPossiamo quindi collegarci ad uno dei server:
mongosh --port 28001Ed inizializzare il "Replica Set" con il comando rs.initiate() a cui passiamo un documento con il campo configsvr: true visto che si tratta dei server di configurazione. Il campo "_id" deve essere uguale all’opzione replication.replSetName dei file di configurazione.
> rs.initiate(
{
_id: "replSet-config",
configsvr: true,
members: [
{ _id: 0, host: "localhost:28001" },
{ _id: 1, host: "localhost:28002" },
{ _id: 2, host: "localhost:28003" }
]
}
)Fatto ciò, dovremo creare nel database admin un utente con il ruolo userAdminAnyDatabase.
> db.getSiblingDB("admin").createUser(
{
user: "adminUser",
pwd: passwordPrompt(),
roles: [
{
role: "userAdminAnyDatabase",
db: "admin"
}
]
}
)Una volta eseguito il metodo createUser() e scelta una password, possiamo autenticarci con le credenziali dell’utente adminUser.
> db.getSiblingDB("admin")
.auth("adminUser","password-scelta-per-adminUser")Creiamo poi un nuovo utente con il ruolo clusterAdmin nel database admin.
> db.getSiblingDB("admin").createUser(
{
user: "clusterGuy",
pwd: passwordPrompt(),
roles: [
{
role: "clusterAdmin",
db: "admin"
}
]
}
)Possiamo successivamente autenticarci con le credenziali del nuovo utente ed eseguire il metodo rs.isMaster() per verificare l’avvenuta configurazione del "Replica Set".
> db.getSiblingDB("admin")
.auth("clusterGuy", "cluster-guy-password")
> rs.isMaster()Passo 3: Avviare mongos
Una volta avviati i server di configurazione possiamo lanciare un’istanza di mongos per cui creiamo il file mongos.conf nella cartella base.
sharding:
configDB: replSet-config/localhost:28001,localhost:28002,localhost:28003
security:
keyFile: /path/to/key/repl-keyfile
net:
bindIp: localhost
port: 28000
systemLog:
destination: file
path: /path/to/db/mongos.log
logAppend: true
processManagement:
fork: trueIn questo caso abbiamo aggiunto l’opzione sharding.configDB per indicare qual è il "Replica Set" di configurazione da cui mongos leggerà i metadati che utilizzerà per indirizzare le query verso uno o più shard. Abbiamo specificato il nome assegnato al "Replica Set" seguito dall’indirizzo completo dei suoi 3 nodi.
È importante osservare che non è presente l’opzione storage.dbPath visto che mongos usa i dati salvati nei server di configurazione e non ha bisogno di salvare altre informazioni.
Per questo motivo mongos erediterà gli utenti creati in precedenza nel "Replica Set" di configurazione.
Eseguiamo allora un’istanza di mongos:
mongos --config mongos.confE colleghiamoci a mongos usando l’utente clusterGuy creato in precedenza nel "Replica Set" di configurazione.
mongosh --port 28000 -u "clusterGuy"Possiamo verificare la configurazione corrente dello "Sharded Cluster" con il comando sh.status(). Nell’output è presente una sezione shards in cui troviamo le informazioni sui "Replica Set" che fanno parte dello "Sharded Cluster". Al momento la sezione è vuota perché non abbiamo aggiunto ancora nessuno "shard". Vediamo quindi come procedere alla configurazione degli ultimi pezzi mancanti.
Passo 4: Creare un "Replica Set" per ciascuno "shard"
Abbiamo già avviato i server di configurazione e il processo mongos, l’ultimo passo da compiere consiste nel creare uno o più "Replica Set" che avranno il ruolo di conservare le diverse partizioni dei dati.
Nel nostro caso andremo a configurare ed avviare 3 "Replica Set", uno per ogni "shard". La procedura è identica per cui mostreremo solo come avviare un "Replica Set". Per creare i successivi basterà apportare delle modifiche ai file di configurazione per le opzioni che riguardano la porta, i percorsi del file di log e dei dati del database e il valore dell’opzione replication.replSetName che identifica il "Replica Set". Nel nostro caso useremo come valori "replSet-sh1" per il primo "Replica Set", "replSet-sh2" per il secondo gruppo di nodi e "replSet-sh3" per il terzo.
Nella cartella ./sh1 abbiamo 3 file di configurazione. Il file sh1-node1.conf è il seguente:
storage:
dbPath: /path/to/db/sh1/node1
net:
bindIp: localhost
port: 27011
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/sh1/node1/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-sh1
sharding:
clusterRole: shardsvrIn questo caso abbiamo aggiunto l’opzione sharding.clusterRole pari a shardsvr ad indicare che si tratta di uno dei nodi del "Replica Set" che compongono il cluster e provvedono a salvare i dati del database.
Il secondo file di configurazione è:
storage:
dbPath: /path/to/db/sh1/node2
net:
bindIp: localhost
port: 27012
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/sh1/node2/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-sh1
sharding:
clusterRole: shardsvrIl terzo file sh1/sh1-node3.conf è invece il seguente:
storage:
dbPath: /path/to/db/sh1/node3
net:
bindIp: localhost
port: 27013
security:
authorization: enabled
keyFile: /path/to/key/repl-keyfile
systemLog:
destination: file
path: /path/to/db/sh1/node3/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: replSet-sh1
sharding:
clusterRole: shardsvrA questo punto possiamo ripetere le stesse operazioni effettuate per il "Replica Set" di configurazione.
Avviamo i 3 nodi del "Replica Set":
mongod --config sh1/sh1-node1.conf
mongod --config sh1/sh1-node2.conf
mongod --config sh1/sh1-node3.confCi colleghiamo ad uno dei server.
mongosh --port 27011Inizializziamo il "Replica Set".
rs.initiate(
{
_id: "replSet-sh1",
members: [
{ _id: 0, host: "localhost:27011" },
{ _id: 1, host: "localhost:27012" },
{ _id: 2, host: "localhost:27013" }
]
}
)Dovremo poi creare un utente con il ruolo "userAdminAnyDatabase" e successivamente un utente con il ruolo "clusterAdmin" esattamente come abbiamo fatto in precedenza.
Dopo essersi accertati che il "Replica Set" è stato avviato correttamente con il comando rs.status() o rs.isMaster(), possiamo terminare la sessione.
Ci colleghiamo quindi a mongos con le credenziali dell’utente clusterGuy:
mongosh --port 28000 -u "clusterGuy"Ed aggiungiamo il "Replica Set" come "shard" del cluster attraverso il metodo sh.addShard() a cui passiamo come argomento una stringa che identifica il "Replica Set" e uno dei suoi nodi. Così facendo mongos sarà in grado di determinare qual è il nodo primario del "Replica Set".
sh.addShard("replSet-sh1/localhost:27011")Ripetiamo lo stesso procedimento per ciascun "Replica Set" che forma uno "shard" del "cluster".
Se abbiamo terminato la sessione, possiamo collegarci nuovamente a mongos (mongosh --port 28000 -u "clusterGuy") e lanciare il comando sh.status(). Otterremo un risultato simile a quello riportato sotto.
sh.status()
shardingVersion
{
_id: 1,
minCompatibleVersion: 5,
currentVersion: 6,
clusterId: ObjectId("6249b928abee0da8b5043c52")
}
---
shards
[
{
_id: 'replSet-sh1',
host: 'replSet-sh1/localhost:27011,localhost:27012,localhost:27013',
state: 1
},
{
_id: 'replSet-sh2',
host: 'replSet-sh2/localhost:27021,localhost:27022,localhost:27023',
state: 1
},
{
_id: 'replSet-sh3',
host: 'replSet-sh3/localhost:27031,localhost:27032,localhost:27033',
state: 1
}
]
---
active mongoses
[ { '5.0.6': 1 } ]
---
autosplit
{ 'Currently enabled': 'yes' }
---
balancer
{
'Currently enabled': 'yes'
}
---
databases
[...]Cosa si intende per "Shard Key"
Una volta configurato uno "Sharded Cluster", dovremo abilitare il meccanismo di partizionamento di una determinata collezione di un database.
Per stabilire in base a quale campo deve essere partizionata una collezione, è necessario definire un indice.
Tale indice, composto da uno o più campi, potrà poi essere usato come chiave di frammentazione (shard key), ovvero come campo in base al quale verranno raggruppati i documenti per poi essere distribuiti nei diversi "shards" del cluster. A ciascun blocco di documenti ci si riferisce con il termine chunk.
Se per esempio i documenti di una collezione presentano un campo "prezzo" che viene usato come "shard key", in base al numero di "shard" e ai valori che assume il campo, vengono creati diversi gruppi di documenti. Ogni gruppo presenta solo documenti il cui prezzo ricade in un certo intervallo avente un valore minimo incluso e un valore massimo escluso.
Ogni volta che viene inviata una richiesta a mongos per inserire un documento, viene usato il valore del campo "prezzo" per capire quale "shard" presenta il blocco di documenti (chunk) con un intervallo che contiene il valore del campo "prezzo" del documento.
In altri termini, se abbiamo 3 "shard" nel cluster e il campo "prezzo" dei documenti oscilla fra 0 e 60 euro, verso il primo "shard" verranno per esempio diretti tutti i documenti con un campo "prezzo" di valore compreso fra 0 e 20 euro (escluso), il secondo "shard" potrebbe contenere tutti i documenti il cui prezzo è compreso fra 20 euro e 40 euro, il terzo potrebbe avere i documenti con un prezzo compreso fra 40 e 60 euro. Nel caso in cui ci dovesse essere un sovraccarico di uno "shard" o si dovessero presentare valori superiori ai limiti correnti, i server di configurazione potrebbero provvedere a ridefinire gli intervalli e ridistribuire i documenti in modo appropriato.
Come per le operazioni di scrittura, anche per la lettura vale lo stesso principio, se il predicato di una query contiene la chiave di partizionamento, mongos è in grado di individuare quale "shard" contiene il documento richiesto. Così facendo la query può essere diretta solo verso il "Replica Set" che conserva il documento invece di dover inviare la query a tutti gli "shard".
Come scegliere una "Shard key"
L’operazione di partizionamento di una collezione è un’operazione permanente e non reversibile per cui la scelta della "shard key" deve essere ponderata.
Per quanto possibile, una chiave di frammentazione deve garantire una distribuzione omogenea dei documenti. Inoltre, deve essere costituita da uno o più campi su cui è stato creato un indice.
Una chiave di frammentazione ideale deve essere tale da essere inclusa nel maggior numero di query in modo che mongos possa determinare quale "shard" contiene un documento e possa indirizzare la query solo verso il "Replica Set" interessato.
MongoDB suggerisce poi tre parametri in base ai quali scegliere una "shard key":
- cardinalità
- frequenza
- valori sempre crescenti o decrescenti
La cardinalità, ovvero il numero di valori distinti che può assumere la "shard key", determina il numero massimo di blocchi (chunks) che possono essere creati. MongoDB suggerisce di scegliere una "shard key" con cardinalità elevata in modo da consentire di introdurre nuovi "shard" ed avere la possibilità di ridimensionare successivamente il cluster in maniera efficace.
La frequenza rappresenta quanto spesso un determinato valore si ripete nei dati. Idealmente dovremmo scegliere una "shard key" con bassa frequenza. Una chiave di partizionamento con alta frequenza presenta dei valori che si ripetono spesso. Ciò vuol dire che le operazioni di scrittura e lettura saranno indirizzate con maggiore frequenza verso lo stesso "shard" in cui è presente il blocco di documenti il cui intervallo include quei valori. In questo modo il cluster perde efficienza in quanto i documenti non vengono distribuiti in modo omogeneo sui diversi "shard" disponibili.
Per la stessa ragione, la "shard key" non dovrebbe contenere valori che crescono o decrescono sempre nel tempo. In questo caso infatti i documenti finirebbero sempre nello stesso "shard".
Come partizionare una collezione
Per partizionare una collezione, dobbiamo innanzitutto invocare il metodo sh.enableSharding() passando come primo argomento una stringa che identifica il database.
Vediamo come fare attraverso un esempio, ma prima importiamo uno dei database presenti su Atlas usando i comandi mongodump e mongorestore.
Se volessimo creare una copia di backup del database "sample_airbnb" in una sottocartella dump/ della directory corrente, dovremmo eseguire il comando:
mongodump --uri mongodb+srv://<username>:<password>@<sub-domain>.mongodb.net/sample_airbnb --out dump/Una volta creato un utente con il ruolo restore (o assegnato il ruolo ad un utente già presente), possiamo eseguire il comando mongorestore. Dal momento che abbiamo salvato il backup nella cartella dump/, possiamo lanciare il seguente comando in cui indichiamo come indirizzo e porta quelli di mongos:
mongorestore --host 127.0.0.1 --port 28000
--drop --nsInclude="sample_airbnb.*"
-u "restoreGuy" --authenticationDatabase "admin"Dopo aver effettuato l’accesso, possiamo abilitare il partizionamento sul database prestando attenzione ad avere i permessi giusti per farlo.
> sh.enableSharding("sample_airbnb")L’attivazione del partizionamento su un database non abilita automaticamente il partizionamento delle raccolte del database. Dovremo invece invocare il metodo sh.shardCollection() passando come primo argomento lo spazio dei nomi della raccolta da partizionare nel formato "<database>.<collezione>" e come secondo argomento un documento che indica quale deve essere la "shard key". Prima però è necessario creare un indice per il campo o i campi che vogliamo usare come chiave di partizionamento.
Per esempio, se volessimo usare il campo "name" come chiave di frammentazione, dovremmo invocare il metodo db.collection.createIndex().
db.sample_airbnb.createIndex( { "name": 1 } )E solo successivamente potremmo eseguire il metodo sh.shardCollection:
sh.shardCollection("sample_airbnb.listingsAndReviews", { "name ": 1 })Infine possiamo controllare lo stato aggiornato del cluster attraverso il metodo sh.status() in cui verrà indicato quali blocchi sono stati creati e in quale "Replica Set" sono stati distribuiti.
Interrogazioni in uno "Sharded Cluster"
Dal punto di vista del client, il partizionamento o meno di una collezione non cambia il modo in cui vengono effettuate le interrogazioni.
Tutte le query sono indirizzate a mongos che si occupa di distribuirle verso gli "shard" corretti.
Se fra i campi di una query è presente la chiave di partizionamento, mongos è in grado di determinare quale "shard" contiene i documenti richiesti e redirige la richiesta solo a quel "Replica Set". Questo tipo di interrogazioni sono chiamate "Targeted Queries" e sono più veloci ed efficienti.
Al contrario, se nel predicato di una query non è presente la "shard key" o se si effettuano interrogazioni su intervalli ampi che potrebbero riguardare diversi blocchi distribuiti su "shard" distinti, allora mongos deve indirizzare la query verso tutti gli "shard".
Queste query sono più lente e diventano meno performanti man mano che aumenta il numero di "shard".
In questo caso mongos riceve i documenti dai vari "shard" ed esegue un’operazione di unione per poi restituire il risultato al client.
Lo stesso procedimento avviene per le operazioni di ordinamento per cui dopo aver ricevuto i documenti dai diversi "shard", mongos procede ad ordinarli complessivamente prima di restituirli al client.