Nelle precedenti lezioni abbiamo visto come usare MQL (MongoDB Query Language) per interrogare i database. L’argomento di questa lezione sarà invece l’Aggregation Framework. Faremo spesso riferimento alle collezioni del database di esempio che abbiamo importato in MongoDB Atlas. Se non l’aveste ancora fatto, è consigliato leggere la terza lezione di questa guida in cui spieghiamo come creare un account su MongoDB Atlas.
Aggregation Framework
L’Aggregation Framework consente di analizzare, processare e trasformare i documenti di una collezione attraverso un meccanismo che prende il nome di Aggregation Pipeline. Per capire di cosa si tratta e come funziona, possiamo paragonarlo al nastro trasportatore di una catena di montaggio.
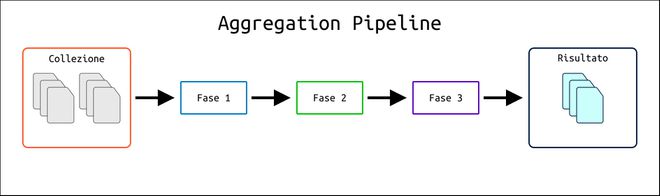
In pratica, i documenti di una collezione attraversano varie fasi. In ciascuna di queste fasi vengono effettuate delle azioni sui documenti che possono essere delle semplici trasformazioni, modifica dei valori o operazioni di selezione e raggruppamento. Ogni fase di questo processo prende in ingresso i documenti che hanno superato lo stadio precedente e dopo aver completato ulteriori operazioni passa i documenti alla fase successiva.
Il metodo db.collection.aggregate()
Per l’Aggregation Framework useremo un solo metodo: db.collection.aggregate(pipeline [, options]) che riceve in ingresso 2 argomenti. Il secondo argomento è un documento opzionale con ulteriori opzioni per personalizzare il comportamento del metodo aggregate(). Il primo argomento è invece un array in cui ogni elemento è un documento che descrive quali azioni devono essere eseguite in una determinata fase. L’array contiene quindi tutta la sequenza di operazioni attraverso le quali dovranno passare i documenti. Il metodo db.collection.aggregate() completerà dunque le diverse fasi della pipeline partendo dal primo elemento dell’array.
db.collection.aggregate(pipeline)L’operatore $match
Vediamo un esempio usando la collezione sample_restaurants.restaurants che abbiamo importato su MongoDB Atlas nelle prime lezioni.
Supponiamo di voler selezionare i ristoranti che si trovano a Brooklyn e offrono piatti della cucina messicana o italiana.
Sicuramente possiamo eseguire la stessa operazione attraverso il metodo db.collection.find(), ma ora vediamo come usare il metodo db.collection.aggregate().
Per filtrare i documenti in base a determinati criteri dovremo usare l’operatore $match.
La sintassi per questo operatore è la seguente.
{ $match: { <query> } }Creiamo allora un array pipeline che passiamo come unico argomento del metodo db.collection.aggregate().
> var pipeline = [
{
$match: {
borough: "Brooklyn",
cuisine: { $in: ['Italian', 'Mexican']}
}
}
]
> db.restaurants.aggregate(pipeline)In questo caso abbiamo una sola fase. I documenti vengono prelevati dalla collezione restaurants e, un documento alla volta, si verifica se soddisfano le condizioni espresse dall’operatore $match. In caso contrario il documento viene scartato, altrimenti il documento passa alla fase successiva. Nel nostro esempio non abbiamo altre fasi e quindi i documenti che soddisfano i criteri di selezione vengono restituiti nel risultato finale.
Possiamo eseguire la stessa query anche in MongoDB Compass o Atlas in cui è presente un’apposita sezione dedicata agli strumenti di aggregazione.
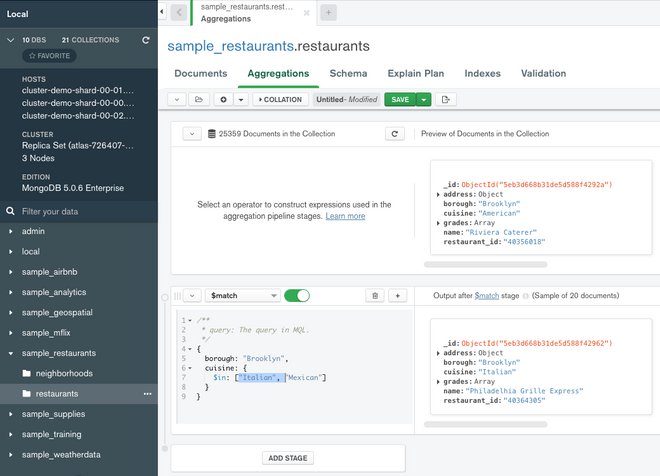
L’interfaccia è abbastanza intuitiva. Possiamo aggiungere una o più fasi e riordinarle a nostro piacimento. Per ciascuna fase dovremo poi selezionare un operatore. Una delle funzionalità più interessanti è la possibilità di visualizzare un’anteprima di quale sarà l’output di ciascuna fase.
Tornando a parlare dell’operatore $match è bene evidenziare che:
- è opportuno usare l’operatore
$matchall’inizio della pipeline o comunque appena possibile perché in questo modo vengono filtrati i documenti e alla fase successiva passano solo quelli che soddisfano i criteri espressi in$match. - se si usa
$matchcome primo operatore, la query può usufruire di eventuali indici sui campi e, come abbiamo avuto modo di osservare nella lezione sugli indici, possiamo ottenere un significativo miglioramento in termini di velocità e consumo di risorse.
L’operatore $count
Continuiamo il nostro viaggio alla scoperta degli operatori dell’Aggregation Framework e parliamo di $count che crea un documento contenente il numero di documenti ricevuti in ingresso. Il documento generato in questa fase viene poi passato a quella successiva.
In questo caso la sintassi è la seguente.
{ $count: <string> }Il valore di $count è una stringa che rappresenta il campo da inserire nel documento di output a cui sarà assegnato proprio il numero di documenti.
Vediamo un esempio e cerchiamo quanti sono i ristoranti italiani di Brooklyn che abbiano almeno un documento nell’array grades con punteggio superiore a 50 (campo ‘score’ di un elemento dell’array ‘grades’).
Per far ciò usiamo proprio l’operatore $count e siccome definiamo le varie fasi in un array pipeline dobbiamo solo aggiornare quest’ultimo e poi limitarci ad invocare sempre db.restaurants.aggregate(pipeline).
> var pipeline = [
{
$match: {
borough: "Brooklyn",
cuisine: "Italian",
grades: {
$elemMatch: {score: {$gt: 50}}
}
}
},
{
$count: "numero totale ristoranti"
}
]
> db.restaurants.aggregate(pipeline)Come risultato otteniamo:
{"numero totale ristoranti": 2}Gli operatori $limit e $skip
Per implementare un sistema di paginazione $limit e $sort sono due operatori che possono risultare estremamente utili.
Come per le query viste nelle lezioni precedenti, $skip è l’operatore equivalente dell’Aggregation Framework per escludere un certo numero di documenti. In particolare se N è il valore assegnato a $skip, vengono tralasciati i primi N documenti e solo i restanti passano alla fase successiva della pipeline.
Al contrario $limit limita il numero di documenti passati alla fase successiva della pipeline.
Vediamoli in azione con un esempio e cerchiamo i ristoranti del Bronx che vendono yogurt e gelati, selezioniamo solo 10 documenti dopo aver escluso i primi 20.
Come al solito definiamo le varie fasi della ‘pipeline’ attraverso un array che poi passiamo al metodo db.restaurants.aggregate(pipeline).
> var pipeline = [
{
$match: {
borough: 'Bronx',
cuisine: 'Ice Cream, Gelato, Yogurt, Ices'
}
},
{ $skip: 20 },
{ $limit: 10}
]
> db.restaurants.aggregate(pipeline)L’operatore $sort
L’operatore $sort ordina i documenti ricevuti e li restituisce in ordine ascendente o discendente.
La sintassi è riportata sotto e per indicare in che modo devono essere ordinati i documenti, assegniamo ad un campo il valore 1 (ordine crescente) o -1 (ordine decrescente).
{
$sort: {
<campo1>: <verso-di-ordinamento>,
<campo2>: <verso-di-ordinamento>
...
}
}Come indicato nella documentazione, bisogna prestare attenzione ai casi in cui si esegua l’ordinamento su campi che possono contenere dei duplicati perché i documenti potrebbero non essere restituiti sempre nello stesso ordine. Per ottenere un ordinamento coerente è consigliato includere sempre almeno un campo che presenti valori univoci. Il modo più semplice consiste nell’includere il campo ‘_id’ che in MongoDB deve essere sempre univoco.
Vediamo allora come ottenere l’elenco in ordine crescente dei ristoranti italiani di Manhattan con almeno un punteggio superiore a 30. Vogliamo scartare i primi 10 ristoranti e limitare il risultato a soli 20 ristoranti.
> var pipeline = [
{
$match: {
borough: "Manhattan",
cuisine: "Italian",
grades: {
$elemMatch: {score: {$gt: 30}}
}
}
},
{
$sort: {name: 1}
},
{
$skip: 10
},
{
$limit: 20
}
]
> db.restaurants.aggregate(pipeline)In questo caso vengono prelevati i documenti dalla collezione restaurants. Ciascun documento attraversa il primo stadio della pipeline e solo quelli che corrispondono ai criteri espressi dall’operatore $match passano alla fase successiva in cui vengono ordinati in ordine crescente in base al nome del ristorante. I documenti ordinati vengono inviati all’operatore $skip che scarta i primi 10 e inoltra i restanti a $limit che è l’ultimo operatore della pipeline. Dopo aver selezionato i primi 20 documenti fra quelli rimasti, questi vengono inseriti nel risultato finale.
L’operatore $group
L’operatore $group censente di raggruppare i documenti d’ingresso in base all’espressione ‘_id’ specificata. Per ciascun raggruppamento viene generato un documento distinto identificato dallo stesso campo ‘_id’. I documenti ottenuti possono anche avere dei campi extra contenenti i valori di alcuni accumulatori come $count che conta il numero totale di documenti di un gruppo o $avg che calcola la media dei valori di un certo campo numerico.
L’operatore $group offre un gran numero di accumulatori per cui per una descrizione esaustiva è consigliato consultare la documentazione.
In questa lezione ci limitiamo a vedere un esempio. Vogliamo sapere quanti ristoranti ci sono a Brooklyn per ogni tipo di cucina. La lista ottenuta deve essere ordinata in senso decrescente in base al numero di ristoranti
> var pipeline = [
{
$match: {
borough: "Brooklyn",
}
},
{
$group: {
_id: "$cuisine",
numero_ristoranti: { $count: {} }
}
},
{
$sort: {numero_ristoranti: -1}
}
]
> db.restaurants.aggregate(pipeline)Soffermiamoci un momento ad analizzare l’ultimo esempio. Prima di tutto evidenziamo che nella prima fase del processo usiamo l’operatore $match per selezionare i soli ristoranti di Brooklyn. Utilizziamo poi l’operatore $group. Siccome vogliamo raggruppare i ristoranti in base al tipo di cucina, indichiamo che il campo ‘_id’ deve essere pari al valore del campo ‘cuisine’ (notate che abbiamo applicato il prefisso ‘$’ prima del nome del campo a sottolineare che vogliamo accedere al valore del campo ‘cuisine’). Aggiungiamo poi un campo ‘numero_ristoranti’ a cui assegniamo il numero totale di ristoranti per quel tipo di cucina. L’operatore $count ha una sintassi un po’ diversa quando viene usato nel contesto di $group. Dovremo semplicemente assegnare un documento vuoto a $count. Nell’ultima fase ordiniamo i documenti in senso decrescente in base al numero di ristoranti di ciascun tipo di cucina. Il risultato parziale che comprende i primi 5 tipi di cucine per numero di ristoranti è riportato sotto.
{ _id: 'American', numero_ristoranti: 1273 }
{ _id: 'Chinese', numero_ristoranti: 763 }
{ _id: 'Caribbean', numero_ristoranti: 314 }
{ _id: 'Pizza', numero_ristoranti: 296 }
{ _id: 'Café/Coffee/Tea', numero_ristoranti: 289 }L’operatore $project
L’operatore $project passa i documenti contenenti i soli campi specificati alla fase successiva. Quelli indicati possono essere dei campi già esistenti nei documenti o dei nuovi campi da calcolare e aggiungere a quelli già presenti.
All’operatore $project assegniamo un documento in cui indichiamo quali campi devono essere inclusi o esclusi nei documenti prima di passare alla fase successiva della pipeline. Al nome dei campi da includere assegniamo il valore 1, per indicare che un campo deve essere rimosso usiamo il valore 0.
Per esempio possiamo cercare i ristoranti di cucina messicana del Bronx, ma, invece di restituire l’intero documento, selezioniamo i soli campi ‘name’, ‘cuisine’ e ‘borough’. Dato che il campo ‘_id’ viene sempre incorporato nel documento finale, dobbiamo indicare esplicitamente di rimuoverlo.
> var pipeline = [
{ $match: { cuisine: 'Mexican', borough: 'Bronx'} },
{ $project: { _id: 0, name: 1, cuisine: 1, borough: 1}}
]
> db.restaurants.aggregate(pipeline)Ma $project non si limita solo ad includere o rimuovere dei campi già esistenti, possiamo anche aggiungerne dei nuovi e calcolare i loro valori attraverso delle espressioni che utilizzano anche dei campi già esistenti.
Nel prossimo esempio useremo la collezione listingsAndReviews del database sample_airbnb. Vediamo come selezionare le proprietà nella città di Barcellona con almeno 2 stanze e un prezzo inferiore a 50 euro. Nei documenti finali vogliamo includere i campi ‘name’, ‘address’,’property_type’, ‘bedrooms’, ‘price’ e aggiungere un campo ‘recommended’ pari a true se il valore di ‘review_scores.review_scores_rating’ è maggiore di 90, false in caso contrario.
Nella prima fase usiamo l’operatore $match per filtrare i documenti e far passare alla fase successiva, in cui utilizziamo $project, solo quelli che rispettano i criteri scelti (Per il campo address.street usiamo un’espressione regolare).
> var pipeline = [
{
$match: {
price: { $lt: 50},
bedrooms: { $gte: 2},
"address.street": /^Barcelona/
}
},
{
$project: {
_id: 0,
price: 1,
bedrooms: 1,
property_type: 1,
address: 1,
recommended: {
$gt: ["$review_scores.review_scores_rating", 90]
}
}
}
]Per calcolare il valore del nuovo campo ‘recommended’, che aggiungiamo ai documenti da restituire, usiamo l’operatore $gt a cui passiamo un array. $gt confronta il valore del primo elemento dell’array con il secondo e restituisce true se il primo elemento è maggiore del secondo, false in caso contrario. Ancora una volta è bene notare che per il primo elemento dell’array abbiamo utilizzato il prefisso ‘$’ che consente di accedere al valore del campo ‘review_scores.review_scores_rating’.
Se volessimo filtrare i documenti in base al campo recommended e selezionare solo quelli in cui quest’ultimo è uguale a true, potremmo aggiungere un altro stadio alla pipeline e utilizzare nuovamente l’operatore $match.
Infatti occorre sottolineare che nulla ci vieta di usare lo stesso operatore in più fasi.
> var pipeline = [
{
$match: {
price: { $lt: 50},
bedrooms: { $gte: 2},
"address.street": /^Barcelona/ }
},
{
$project: {
_id: 0,
price: 1,
bedrooms: 1,
property_type: 1,
address: 1,
recommended: {
$gt: ["$review_scores.review_scores_rating", 90]
}
}
},
{ $match: { recommended: true }}
]
> db.listingsAndReviews.aggregate(pipeline)L’operatore $project ha però dei limiti e dei difetti. Innanzitutto, ad eccezione del campo ‘_id’, in una singola fase non è possibile indicare contemporaneamente quali campi includere o escludere. Facendo riferimento all’esempio precedente, se cambiassimo il valore di ‘price’ (price: 0) indicando che vogliamo rimuoverlo dal documento, l’esecuzione del metodo db.collection.aggregate fallirebbe.
Inoltre se vogliamo aggiungere un nuovo campo come abbiamo fatto per ‘recommended’, siamo costretti ad elencare anche tutti i campi da includere nei documenti che passiamo alla fase successiva. Se un documento contiene numerosi campi e vogliamo mantenerli tutti, dovremo elencarli uno per uno nel documento che assegniamo all’operatore $project.
Per risolvere quest’ultimo problema, è stato introdotto l’operatore $addFields.
L’operatore $addFields
L’operatore $addFields consente di aggiungere dei nuovi campi ad un documento ricevuto in ingresso mantenendo tutti gli altri campi già presenti.
Riprendendo l’esempio precedente, se volessimo limitarci ad aggiungere il campo ‘recommended’, potremmo modificare l’array ‘pipeline’ come mostrato sotto.
> var pipeline = [
{
$match: {
price: { $lt: 50},
bedrooms: { $gte: 2},
"address.street": /^Barcelona/
}
},
{
$addFields: {
recommended: {
$gt: ["$review_scores.review_scores_rating", 90]
}
}
},
{ $match: { recommended: true }}
]
> db.listingsAndReviews.aggregate(pipeline)Così facendo i documenti mantengono tutti i campi, ma viene aggiunto anche ‘recommended’.
Gli operatori $map e $reduce
I due operatori $map e $reduce sono come gli omonimi metodi del linguaggio Javascript e consentono di trasformare e processare gli elementi di un array. Sono due operatori indipendenti, ma spesso vengono utilizzati insieme.
Cominciamo a parlare di $map che permette di applicare una certa espressione ad ogni elemento di un array restituendo poi un nuovo array con gli elementi modificati.
La sintassi è più complessa di quella degli altri operatori visti finora per cui soffermiamoci un attimo per descriverla in dettaglio.
{
$map: {
input: <expression>,
as: <string>,
in: <expression>
}
}All’operatore $map assegniamo un documento con tre campi:
inputè un espressione che restituisce un Array, spesso ci limitiamo ad usare l’operatore ‘$’ per accedere al valore di un campo di tipo Array. Si tratta sostanzialmente dell’array a cui applicare l’operatore$map.asè un campo opzionale. Rappresenta il nome della variabile con cui ci riferiamo a ciascun elemento dell’array durante ogni iterazione. Se$mapfosse una funzione di un linguaggio di programmazione, potremmo pensare al valore di questo campo come ad un argomento che passeremmo alla funzione. Tale argomento si riferirebbe di volta in volta ad un elemento dell’array che verrebbe processato dalla funzione nel corso di ogni iterazione. Se non viene specificato, viene usato il valore predefinitothisper riferirsi di volta in volta all’elemento corrente che sta per essere processato.inè proprio l’espressione che viene applicata ad ogni elemento dell’array. In tale espressione abbiamo accesso alla variabile definita attraverso il campoas. Per accedere al valore di tale variabile dovremo usare il prefisso ‘$$’.
Cerchiamo allora di capire meglio come funziona l’operatore $map attraverso un esempio.
Consideriamo sempre la collezione sample_restaurants.restaurants. Ciascun documento presenta un campo grades che è un Array come quello riportato sotto.
{
borough: 'Brooklyn',
cuisine: 'Italian',
grades: [
{ date: 2014-02-25T00:00:00.000Z, grade: 'A', score: 12 },
{ date: 2013-06-27T00:00:00.000Z, grade: 'A', score: 7 },
{ date: 2012-12-03T00:00:00.000Z, grade: 'A', score: 10 },
{ date: 2011-11-09T00:00:00.000Z, grade: 'A', score: 12 }
],
name: 'Philadelhia Grille Express'
}Vogliamo selezionare i documenti relativi ai ristoranti italiani di Brooklyn ed aggiungere un nuovo campo ‘gradesAndScores’ che deve essere un Array di stringhe del tipo ‘<grade> – <scoreMultipliedBy2>’, per esempio se il valore del campo ‘grades.score’ è pari a 5, vogliamo ottenere come risultato ‘A – 10’.
> var pipeline = [
{ $match: { borough: 'Brooklyn', cuisine: 'Italian'} },
{
$addFields: {
gradesAndScores: {
$map: {
input: "$grades",
as: "currentGrade",
in: {
$concat: [
"$$currentGrade.grade",
" - ",
{
$toString: {
$multiply: ["$$currentGrade.score", 2]
}
}
]
}
}
}
}
}
]
> db.restaurants.aggregate(pipeline)Analizziamo attentamente l’esempio precedente ed in particolare il valore della variabile pipeline.
Il primo stadio si limita a selezionare i documenti relativi ai soli ristoranti italiani di Brooklyn.
Nella seconda fase, ai documenti ricevuti in ingresso aggiungiamo un campo ‘gradesAndScores’ attraverso l’operatore $addFields. Siccome vogliamo ottenere un campo di tipo Array partendo dai valori dell’altro campo ‘grades’ già presente nei documenti, usiamo l’operatore $map per processare i singoli elementi dell’array uno alla volta.
In base a quanto detto prima, il campo ‘input’ dell’operatore $map deve essere pari al valore del campo ‘grades’ di un documento. Per accedere al valore del campo basta usare il prefisso ‘$’. In questo modo indichiamo che stiamo per applicare l’operatore $map all’array contenuto nel campo grades dei documenti.
Come valore del campo ‘as’ abbiamo scelto ‘currentGrade’. Questo sarà il nome della variabile che ci permette di accedere di volta in volta al singolo elemento dell’array ‘grades’ che viene processato dall’operatore $map.
Infine il campo ‘in’ di $map definisce quale deve essere il valore di ciascun elemento dell’array ‘gradesAndScores’. Nel caso specifico usiamo $concat che come valore deve avere un Array di stringhe da concatenare. Il primo elemento dell’array è il valore del campo ‘grade’ dell’elemento corrente dell’array ‘grades’ del documento ricevuto in ingresso. Visto che all’elemento corrente ci riferiamo con la variabile locale ‘currentGrade’ definita nel campo ‘as’, possiamo accedere al suo valore con il prefisso ‘$$’. Per cui "$$currentGrade.grade" sarà pari al valore del campo "grade" dell’elemento dell’array "grades" che viene di volta in volta processato da $map. Facendo riferimento all’esempio riportato sopra, alla prima iterazione $map processa il documento { date: 2014-02-25T00:00:00.000Z, grade: 'A', score: 12 } per cui "$$currentGrade" si riferisce proprio al contenuto dell’intero documento, "$$currentGrade.grade" è pari alla stringa 'A', "$$currentGrade.score" è uguale a 12. Come terzo elemento dell’array assegnato a $concat abbiamo usato un documento in cui moltiplichiamo il valore "$$currentGrade.score" per 2 e, siccome $concat accetta solo stringhe, convertiamo il risultato in una stringa con l’operatore $toString.
Eseguendo il metodo db.restaurants.aggregate(pipeline) otteniamo dei documenti come quello riportato sotto.
{
borough: 'Brooklyn',
cuisine: 'Italian',
grades: [
{ date: 2014-02-25T00:00:00.000Z, grade: 'A', score: 12 },
{ date: 2013-06-27T00:00:00.000Z, grade: 'A', score: 7 },
{ date: 2012-12-03T00:00:00.000Z, grade: 'A', score: 10 },
{ date: 2011-11-09T00:00:00.000Z, grade: 'A', score: 12 }
],
gradesAndScores: ['A - 24', 'A - 14', 'A - 20', 'A - 24']
name: 'Philadelhia Grille Express'
}L’operatore $reduce consente invece di applicare una certa espressione a ciascun elemento di un array e combinare il valore di ogni elemento per ottenere un singolo valore finale. Quindi, mentre $map riceve un array e restituisce un nuovo array dopo avere processato ciascun valore di quello in ingresso. $reduce riceve sempre un array, ma processa i vari elementi in modo da ottenere un risultato finale che può anche non essere un array.
La sintassi è la seguente:
{
$reduce: {
input: <array>,
initialValue: <expression>,
in: <expression>
}
}Anche in questo caso dovremo specificare 3 campi:
inputè come l’omonimo campo di$maped è l’array su cui applicare l’operatore$reduce.initialValueè il valore iniziale dell’accumulatore che viene settato prima di iniziare a processare il primo elemento dell’array.inè un’espressione che$reduceapplica a ciascun elemento dell’array di input. All’interno di questa espressione abbiamo accesso a due variabili speciali. La prima èvalueche si riferisce all’accumulatore che conterrà il valore finale di ogni iterazione. La seconda èthische fa riferimento all’elemento corrente che viene processato dall’operatore.
Vediamo un esempio facendo riferimento alla collezione del database ‘sample_airbnb.listingsAndReviews’ che contiene anche un campo ‘amenities’ di tipo array con la lista dei servizi offerti da ciascuna proprietà.
{
name: 'Lorikeet blue',
amenities: [ 'Wifi', 'Pets allowed', 'Essentials' ],
}Supponiamo allora di voler cercare i documenti relativi alle proprietà situate in Portogallo con un prezzo inferiore a 50 Euro e con un campo ‘amenities’ che contenga meno di 5 servizi. Per questi documenti vogliamo aggiungere un campo ‘amenities_as_string’ che è una stringa contenente la lista di servizi separati da virgola. I documenti finali devono avere solo i campi ‘name’, ‘address.country’, ‘price’, ‘amenities’ e ‘amenities_as_string’.
var pipeline = [
{
$match: {
"address.country": "Portugal",
price: { $lt: 50 } ,
$expr: { $lt: [{$size: "$amenities"}, 5] }
}
},
{
$addFields: {
amenities_as_string: {
$reduce: {
input: "$amenities",
initialValue: '',
in: {
$concat: ["$$value", ", " ,"$$this"]
}
}
}
}
},
{
$project: {
_id: 0,
name: 1,
price: 1,
"address.country": 1,
amenities: 1,
amenities_as_string: {
$substr: [ "$amenities_as_string", 2, -1]
}
}
}
]Trascuriamo il primo stadio in cui usiamo l’operatore $match in quanto non presenta nulla di nuovo rispetto a quanto abbiamo visto finora.
Nel secondo stadio aggiungiamo un nuovo campo amenities_as_string il cui valore è calcolato attraverso l’operatore $reduce.
{
$addFields: {
amenities_as_string: {
$reduce: {
input: "$amenities",
initialValue: '',
in: {
$concat: ["$$value", ", " ,"$$this"]
}
}
}
}
}All’operatore $reduce passiamo come input il valore del campo ‘amenities’ dei documenti che hanno raggiunto questa fase della pipeline. Usiamo un valore iniziale (initialValue: '' ) pari ad una stringa vuota. Per ogni elemento dell’array ‘amenities’, accediamo al suo valore tramite ‘$$this’. Appendiamo quindi il valore dell’elemento corrente a quello dell’accumulatore a cui possiamo accedere tramite la variabile speciale ‘value’.
Facciamo riferimento al frammento di documento riportato sopra con un campo ‘amenities’ pari a [ 'Wifi', 'Pets allowed', 'Essentials' ] ed analizziamo in che modo opera $reduce:
- Alla prima iterazione
initialValueè pari a ”,$$valuecontiene ”,$$thisè uguale a ‘Wifi’, il valore dell’accumulatore che sarà disponibile nell’iterazione successiva attraverso la variabile ‘value’ è: ‘, Wifi’. - Alla seconda iterazione l’accumulatore
$$valuecontiene ‘, Wifi’,$$thisè uguale a ‘Pets allowed’, il valore dell’accumulatore che sarà disponibile nell’iterazione successiva è ‘, Wifi, Pets allowed’. - Alla terza iterazione
$$valuecontiene ‘, Wifi, Pets allowed’,$$thisè uguale a ‘Essentials’, il valore dell’accumulatore che sarà assegnato al campo ‘amenities_as_string’ è: ‘, Wifi, Pets allowed, Essentials’.
Visto che al termine dello stadio in cui ha operato $reduce, ‘amenities_as_string’ presenta come primi due caratteri ‘, ‘, nella fase successiva della pipeline, in cui selezioniamo i campi dei documenti da restituire, utilizziamo l’operatore $substr per rimuovere i primi 2 caratteri (virgola e spazio) superflui.
La sintassi dell’operatore $substr è la seguente:
{ $substr: [ <string>, <start>, <length> ] }Il parametro ‘start’ rappresenta l’indice a partire dal quale deve essere ricavata la nuova stringa, ‘length’ indica quanti caratteri devono essere copiati nella nuova stringa a partire da ‘start’. Se ‘length’ è un valore negativo, $substr restituisce una sottostringa che inizia dall’indice specificato da start ed include il resto della stringa.
L’operatore $unwind
L’operatore $unwind scompone un campo di tipo Array dei documenti in ingresso generando tanti documenti quanti sono gli elementi dell’array. Ogni documento creato ha gli stessi campi di quello in ingresso ad eccezione del campo di tipo array che viene rimpiazzato da uno degli elementi che conteneva.
La sintassi è la seguente:
{ $unwind: <percorso-del-campo-di-tipo-array> }Per esempio riconsideriamo il seguente frammento di documento.
{
name: 'Lorikeet blue',
amenities: [ 'Wifi', 'Pets allowed', 'Essentials' ],
}Se questo è il solo documento su cui applichiamo l’operatore $unwind ({ $unwind: "$amenities"}) al campo ‘amenities’, verranno generati 3 documenti distinti al posto di uno come quelli riportati sotto. Il campo ‘amenities’ mantiene il suo nome, ma non sarà più un array, al contrario sarà una semplice stringa.
{
name: 'Lorikeet blue',
amenities: 'Wifi'
}
{
name: 'Lorikeet blue',
amenities: 'Pets allowed'
}
{
name: 'Lorikeet blue',
amenities: 'Essentials'
}Vediamo un esempio facendo riferimento alla collezione ‘sample_restaurants.restaurants’.
{ _id: ObjectId("5eb3d668b31de5d588f4463e"),
address: {
building: '7319',
coord: [ -74.02193489999999, 40.6304357 ],
street: '5 Avenue',
zipcode: '11209' },
borough: 'Brooklyn',
cuisine: 'German',
grades: [
{ date: 2014-12-05T00:00:00.000Z, grade: 'A', score: 11 },
{ date: 2014-06-05T00:00:00.000Z, grade: 'A', score: 7 },
{ date: 2013-11-07T00:00:00.000Z, grade: 'A', score: 13 },
{ date: 2013-02-14T00:00:00.000Z, grade: 'B', score: 19 },
{ date: 2012-06-07T00:00:00.000Z, grade: 'A', score: 12 }
],
name: 'Schnitzel Haus',
restaurant_id: '41266395' }Vogliamo ottenere il punteggio medio (media dei valori di ‘grades.score’) dei ristoranti di cucina tedesca presenti a Brooklyn. Lo stesso risultato si potrebbe ottenere usando l’operatore $reduce, ma in questo caso utilizzeremo invece $unwind.
> var pipeline = [
{ $match: { borough: 'Brooklyn', cuisine: 'German'} },
{ $unwind: "$grades" },
{ $group: { _id: '$name', avgScore: { $avg: "$grades.score"}}}
]
> db.restaurants.aggregate(pipeline)Nell’esempio riportato sopra, selezioniamo i soli ristoranti che soddisfano i criteri dell’operatore $match. Ciascun documento presenta un campo ‘grades’ di tipo Array. Applicando l’operatore $unwind, per ciascun documento in ingresso generiamo tanti documenti quanti sono gli elementi dell’array ‘grades’. Per esempio per il ristorante 'Schnitzel Haus' generiamo 5 documenti in cui però il campo ‘grades’ non è più un array, ma sarà uguale a uno dei documenti che erano presenti nell’array originale. Nell’ultimo stadio raggruppiamo i documenti relativi a ciascun ristorante e calcoliamo la media dei valori dei campi ‘grades.score’.
Otteniamo quindi i seguenti documenti.
{ _id: 'Berlyn', avgScore: 18.2 }
{ _id: 'Black Forst Brooklyn', avgScore: 7 }
{ _id: 'Brooklyn Buschenschank', avgScore: 28.25 }
{ _id: 'Radegast Hall & Biergarten', avgScore: 10.333333333333334 }
{ _id: 'Schnitzel Haus', avgScore: 12.4 }
{ _id: 'Koelner Bier Halle', avgScore: 14.666666666666666 }L’operatore $lookup
L’operatore $lookup esegue il LEFT JOIN e consente quindi di "unire" i documenti di due diverse collezioni in base ad una certa condizione. Ad ogni documento di input, l’operatore $lookup aggiunge un nuovo campo di tipo Array i cui elementi sono i documenti dell’altra collezione collegati al documento di input in base ad una determinata condizione. L’operatore $lookup passa poi i documenti finali ottenuti alla fase successiva.
La sintassi per unire dei documenti in base ad una condizione di uguaglianza è la seguente.
{
$lookup: {
from: <collezione-esterna-da-cui-prelevare-i-documenti-da-unire>,
localField: <campo-dei-documenti-su-cui-effettuare-join>,
foreignField: <campo-dei-documenti-della-collezione-indicata-nel-campo-from>,
as: <nome-del-campo-array-dei-documenti-finali>
}
}Dal momento che $lookup è un operatore da usare in una delle fasi della pipeline. La collezione che invoca il metodo aggregate è quella su cui viene applicato l’operatore.
Il campo from indica invece il nome di un’altra collezione del database da cui prelevare i documenti da unire a quelli della collezione corrente.
localField si riferisce ad un campo dei documenti della collezione su cui è applicato l’operatore $lookup.
foreignField è il campo dei documenti della collezione esterna il cui nome è stato specificato tramite il campo from
Il campo as definisce il nome del campo di tipo Array da aggiungere ai documenti finali. In questo Array finiscono i documenti della collezione ‘from‘ che hanno un campo foreignField pari al campo localField della collezione su cui è applicato l’operatore $lookup.
Vediamo un esempio e consideriamo il database sample_analytics. Prendiamo in esame due delle collezioni in esso presenti, ovvero accounts e transactions.
La collezione accounts presenta dei documenti come quello riportato sotto.
{ _id: ObjectId("5ca4bbc7a2dd94ee5816238c"),
account_id: 371138,
limit: 9000,
products: [ 'Derivatives', 'InvestmentStock' ]
}I documenti della collezione transactions seguono invece lo schema seguente.
{ _id: ObjectId("5ca4bbc1a2dd94ee58161cb1"),
account_id: 371138,
transaction_count: 66,
bucket_start_date: 1969-02-04T00:00:00.000Z,
bucket_end_date: 2017-01-03T00:00:00.000Z,
transactions: [...]
}Applicando l’operatore $lookup alla collezione accounts, possiamo associare a ciascun account i documenti relativi alle sue transazioni.
Per far ciò indicheremo la collezione ‘transactions’ come valore del campo ‘from’ dell’operatore $lookup. localField si riferirà invece al campo ‘account_id’ della collezione ‘accounts’. Allo stesso tempo foreignField sarà sempre uguale ad ‘account_id’, ma in questo caso si riferirà al campo della collezione ‘transactions’.
Per semplificare il risultato consideriamo il solo account numero 627788.
> var pipeline = [
{ $match: {account_id: 627788}},
{ $lookup: {
from: 'transactions',
localField: 'account_id',
foreignField: 'account_id',
as: 'accountTransactionsDetails'
}}
]
> db.accounts.aggregate(pipeline)Il risultato ottenuto sarà come quello riportato sotto.
{
_id: ObjectId("5ca4bbc7a2dd94ee58162812"),
account_id: 627788,
limit: 10000,
products: [
'Brokerage',
'InvestmentStock',
'CurrencyService',
'Commodity'
],
accountTransactionsDetails: [
{ _id: ObjectId("5ca4bbc1a2dd94ee58162211"),
account_id: 627788,
transaction_count: 54,
bucket_start_date: 1964-06-27T00:00:00.000Z,
bucket_end_date: 2017-01-02T00:00:00.000Z,
transactions: [...]
},
{ _id: ObjectId("5ca4bbc1a2dd94ee58162320"),
account_id: 627788,
transaction_count: 22,
bucket_start_date: 1965-02-06T00:00:00.000Z,
bucket_end_date: 2017-01-05T00:00:00.000Z,
transactions: [...]
}
]
}Se per un certo account non esistesse alcun documento nella collezione ‘transactions’, il campo ‘accountTransactionsDetails’ del documento finale sarebbe un array vuoto.
Nella prossima lezione…
Nella prossima lezione vedremo come strutturare un database e come organizzare al meglio le collezioni sfruttando le caratteristiche di MongoDB.