In questa lezione cercheremo di capire meglio come funziona Git e come fa a conservare i file nel repository. Per far ciò inizieremo ad analizzare il contenuto della cartella .git che incontreremo nuovamente quando parleremo dei Branch.
Nella precedente lezione avevamo lanciato il comando git log col quale avevamo visualizzato l’elenco dei diversi commit effettuati. L’output era un elenco in cui ogni commit conteneva delle informazioni come quelle riportate nell’immagine sottostante.
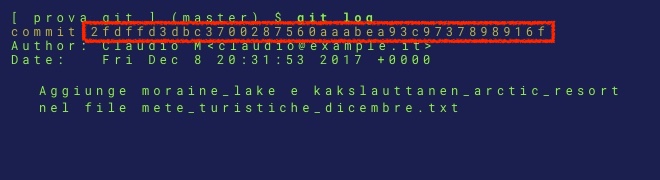
Nell’immagine abbiamo evidenziato la presenza di un numero di 40 cifre in formato esadecimale che caratterizza ogni commit. Infatti, quando effettuiamo un commit (git commit…) per salvare un’istantanea del nostro progetto nel repository, Git crea un file per quel determinato commit all’interno di una sottocartella della directory .git/objects. Ogni commit è univocamente identificato dal valore di hash generato a partire dal contenuto del file usando l’algoritmo SHA-1. (Git utilizza attualmente SHA-1, ma è possibile che in futuro vengano supportati altri algoritmi visto il recente attacco di collisione contro l’algoritmo SHA-1 portato a termine da Google) Git fornisce quindi il valore di hash generato (le 40 cifre in formato esadecimale) per consentire di recuperare il contenuto del file. Git usa la cartella .git/objects come un database all’interno del quale salva diversi tipi di oggetti fra cui gli oggetti di tipo Commit. Per ogni oggetto viene generata una chiave usando l’algoritmo SHA-1 e tale chiave permette di poter recuperare l’oggetto in qualsiasi momento. Prima di procedere, ci soffermiamo un attimo a parlare della funzione SHA-1.
Funzione di hash SHA-1
SHA-1 (Secure Hash Algorithm) è una versione della famiglia di funzioni crittografiche di hash SHA. Una funzione crittografica di hash riceve in ingresso dei dati di lunghezza arbitraria (messaggio) e produce una stringa di lunghezza fissa detta valore di hash o anche digest. Una funzione crittografica ideale, dato un certo messaggio in ingresso, genera sempre lo stesso valore di hash. Per cui anche un minimo cambiamento del messaggio produce un risultato diverso. Un’altra peculiarità è che deve esser possibile calcolare velocemente il valore di hash, ma praticamente impossibile risalire al messaggio originale partendo dal digest. Infine, a due differenti messaggi non può corrispondere lo stesso valore di hash. Se ciò accade si verifica una collisione.
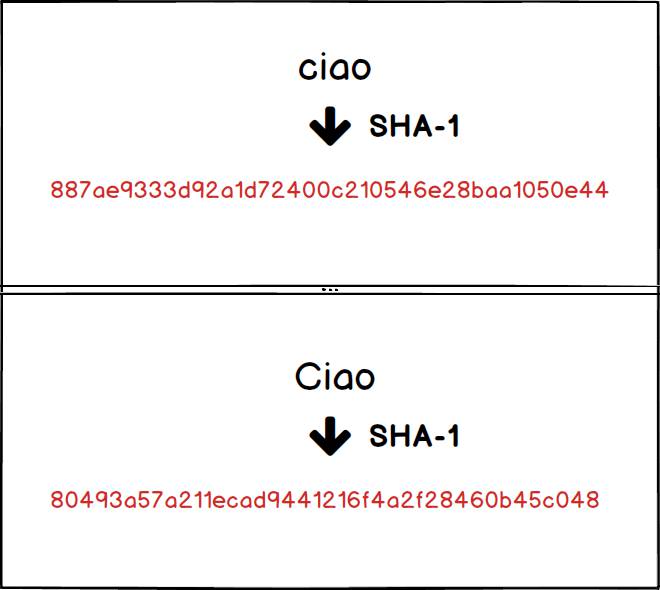
Git usa SHA-1 per generare un valore di hash per ogni oggetto salvato nella cartella .git/objects. In sostanza ogni commit è identificato da una sequenza univoca esadecimale di 40 cifre generata a partire dal contenuto del file salvato per quel commit all’interno della cartella .git/objects. Ogni commit è quindi rappresentato da un oggetto univoco e immutabile garantendo così una certa protezione contro la corruzione accidentale dei dati. Infatti, poiché il valore di hash è generato a partire dal contenuto del file, non è possibile cambiare quest’ultimo senza che venga mutato anche il valore di hash e quindi generato un nuovo e differente oggetto.
Primo contatto con la cartella.git
Ritornando a parlare di Git e del meccanismo adoperato per salvare i file nel repository, vediamo più da vicino il contenuto della cartella .git. In particolare ci soffermeremo sulla cartella .git/objects presente all’interno di qualsiasi progetto in cui si usa Git per tenere traccia dei cambiamenti dei file.
Creiamo allora una nuova directory test_git_objects, spostiamoci al suo interno e lanciamo il comando git init per inizializzare un repository. Visualizziamo quindi il contenuto della cartella .git con il seguente comando.
[ test_git_objects ] (master) $ tree .git
.git
├── HEAD
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── prepare-commit-msg.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
8 directories, 14 filesTrascuriamo per il momento tutte le cartelle ad eccezione della directory .git/objects che è il percorso in cui Git salva gli oggetti che costituiscono il repository. Inizialmente la cartella .git/objects contiene solo le due sottocartelle info e pack. Possiamo simulare il comportamento attraverso il quale Git crea degli oggetti usando il comando git hash-object che genera appunto dei nuovi oggetti che verranno salvati proprio all’interno della directory .git/objects. Vediamo allora come usare il comando git hash-object.
[ test_git_objects ] (master) $ echo 'ciao' | git hash-object --stdin
887ae9333d92a1d72400c210546e28baa1050e44Passiamo la stringa ‘ciao’ al comando git hash-object (Abbiamo usato il meccanismo delle Pipe tipico delle shell testuali e l’opzione –stdin con cui il comando git hash-object legge l’ingresso dallo standard input invece di un file) che calcola il valore di hash usando l’algoritmo SHA-1 e lo mostra a video. Eseguiamo nuovamente lo stesso comando con l’opzione -w che oltre a restituire una chiave univoca, crea un nuovo file all’interno della directory .git/objects.
[ test_git_objects ] (master) $ echo 'ciao' | git hash-object --stdin -w
887ae9333d92a1d72400c210546e28baa1050e44Se esaminiamo ora il contenuto della cartella .git/objects, notiamo che è stata creata una nuova sottocartella che ha per nome le prime due cifre (88) della chiave univoca restituita dal comando appena eseguito. Al suo interno troviamo quindi un file il cui nome è costituito dai rimanenti 38 caratteri.
[ test_git_objects ] (master) $ tree .git/objects/
.git/objects/
├── 88
│ └── 7ae9333d92a1d72400c210546e28baa1050e44
├── info
└── pack
3 directories, 1 file
[ test_git_objects ] (master) $ ls -lh .git/objects/88/
-r--r--r-- 1 claudio staff 20B 13 Dec 17:17 7ae9333d92a1d72400c210546e28baa1050e44Questo è il metodo usato da Git per salvare i file nel repository. Possiamo poi usare il comando git cat-file per visualizzare il contenuto presente nel file.
[ test_git_objects ] (master) $ git cat-file -p 887ae9333d92a1d72400c210546e28baa1050e44
ciaoUn’utile opzione del comando git cat-file è ‘-t’ che mostra a video il tipo di file salvato all’interno della cartella presente in .git/objects.
[ test_git_objects ] (master) $ git cat-file -t 887ae9333d92a1d72400c210546e28baa1050e44
blobIn questo caso ci viene comunicato che il file è di tipo blob. (abbreviazione di binary large object) Si tratta di uno dei quattro tipi di oggetti che Git salva all’interno di .git/objects. Quando per esempio invochiamo il comando git add <file.txt>, Git crea un oggetto di tipo Blob in cui viene salvato il contenuto del file. Gli oggetti di tipo Blob vengono quindi usati da Git per conservare il contenuto di un file.
Creiamo allora un file, che chiamiamo hello.txt, contenente la sola stringa ‘hello’ e usiamo il comando git add hello.txt per aggiungerlo alla Staging Area.
[ test_git_objects ] (master) $ echo hello > hello.txt
[ test_git_objects ] (master) $ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
hello.txt
nothing added to commit but untracked files present (use "git add" to track)
[ test_git_objects ] (master) $ ls .git/objects/
88 info pack
[ test_git_objects ] (master) $ git add hello.txt
[ test_git_objects ] (master) $ tree .git/objects/
.git/objects/
├── 88
│ └── 7ae9333d92a1d72400c210546e28baa1050e44
├── ce
│ └── 013625030ba8dba906f756967f9e9ca394464a
├── info
└── pack
4 directories, 2 files
[ test_git_objects ] (master) $ git cat-file -p ce013625030ba8dba906f756967f9e9ca394464a
helloCome possiamo notare, è stato creato un nuovo file di tipo Blob all’interno di .git/objects. Proviamo allora a creare un altro file ciao.txt come mostrato sotto e usiamo il comando git hash-object con l’opzione ‘-w’ per salvarlo nel database.
[ test_git_objects ] (master) $ echo ciao > ciao.txt
[ test_git_objects ] (master) $ git hash-object -w ciao.txt
887ae9333d92a1d72400c210546e28baa1050e44
[ test_git_objects ] (master) $ tree .git/objects/
.git/objects/
├── 88
│ └── 7ae9333d92a1d72400c210546e28baa1050e44
├── ce
│ └── 013625030ba8dba906f756967f9e9ca394464a
├── info
└── pack
4 directories, 2 filesIn questo caso non viene creato nessun nuovo oggetto di tipo Blob. Il motivo è che in precedenza avevamo già creato tale file a partire dalla stringa ‘ciao’ (echo ‘ciao’ | git hash-object –stdin -w) per cui Git ‘riutilizza’ il file già presente. In teoria potremmo anche eliminare il file ciao.txt e ripristinarlo a partire dall’oggetto Blob salvato nella cartella .git/objects.
[ test_git_objects ] (master) $ rm ciao.txt
[ test_git_objects ] (master) $ git cat-file 887ae9333d92a1d72400c210546e28baa1050e44 -p > ciao.txt
[ test_git_objects ] (master) $ cat ciao.txt
ciaoCome fa Git a salvare i file nel repository
Come già accennato nei precedenti articoli, Git salva le informazioni all’interno del repository come una serie di istantanee della working directory o di parte di essa. Detto in altri termini, Git memorizza nel repository le informazioni su file e cartelle che permettono di ricostruire la struttura della directory base o di ripristinare il contenuto presente in ciascun file al momento del salvataggio del commit. Ogni volta che si esegue il comando git commit, Git cattura un’istantanea dei file in quel esatto momento e salva un riferimento a quell’istantanea. Per ottenere una maggiore efficienza, se i file non sono stati modificati, Git non salva nuovamente l’intero file, ma solo un riferimento al file che ha già memorizzato. È dunque possibile immaginare il repository come una sequenza di istantanee che danno la possibilità di ‘viaggiare nel tempo’ e avere sempre a disposizione un’esatta versione di un determinato file.
Consideriamo quindi un nuovo esempio in cui creiamo una nuova directory con il seguente contenuto:
[ test_git_repo ] (master) $ tree
.
├── file_1.txt
└── folder
├── file_1.txt
└── file_2.txt
1 directory, 3 files// file_1.txt
ciao// folder/file_1.txt
hello// folder/file_2.txt
hiLanciamo prima il comando git init per inizializzare il repository.
[ test_git_repo ] (master) $ git init
Initialized empty Git repository in /Users/claudio/test_git_repo/.git/Aggiungiamo quindi tutti i file al repository.
[ test_git_repo ] (master) $ git add .
[ test_git_repo ] (master) $ git commit -m 'first commit'
[master (root-commit) c604875] first commit
3 files changed, 1 insertion(+)
create mode 100644 file_1.txt
create mode 100644 folder/file_1.txt
create mode 100644 folder/file_2.txtDopo aver creato il primo commit, Git restituisce le prime sette cifre identificative del commit stesso. Possiamo visualizzare maggiori informazioni con il comando git log.
[ test_git_repo ] (master) $ git log
commit c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
Author: Claudio M <claudio@example.com>
Date: Wed Dec 13 17:17:17 2017 +0000
first commit Lanciamo ora il comando cat-file con l’opzione ‘-t’ passando come argomento il valore di hash identificativo del primo commit.
[ test_git_repo ] (master) $ git cat-file -t c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
commitGit ci informa che l’oggetto su cui abbiamo eseguito git cat-file è di tipo Commit. Dopo gli oggetti di tipo Blob, siamo di fronte alla seconda tipologia di oggetti salvati da Git all’interno della cartella .git/objects. Lanciando il comando cat-file con l’opzione -p possiamo visualizzarne il contenuto.
[ test_git_repo ] (master) $ git cat-file -p c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
tree 8de25c05b63cfa6e2fde45174214e6ecf740b9fe
author Claudio M. <claudio@example.com> 1513185437 +0000
committer Claudio M. <claudio@example.com> 1513185437 +0000
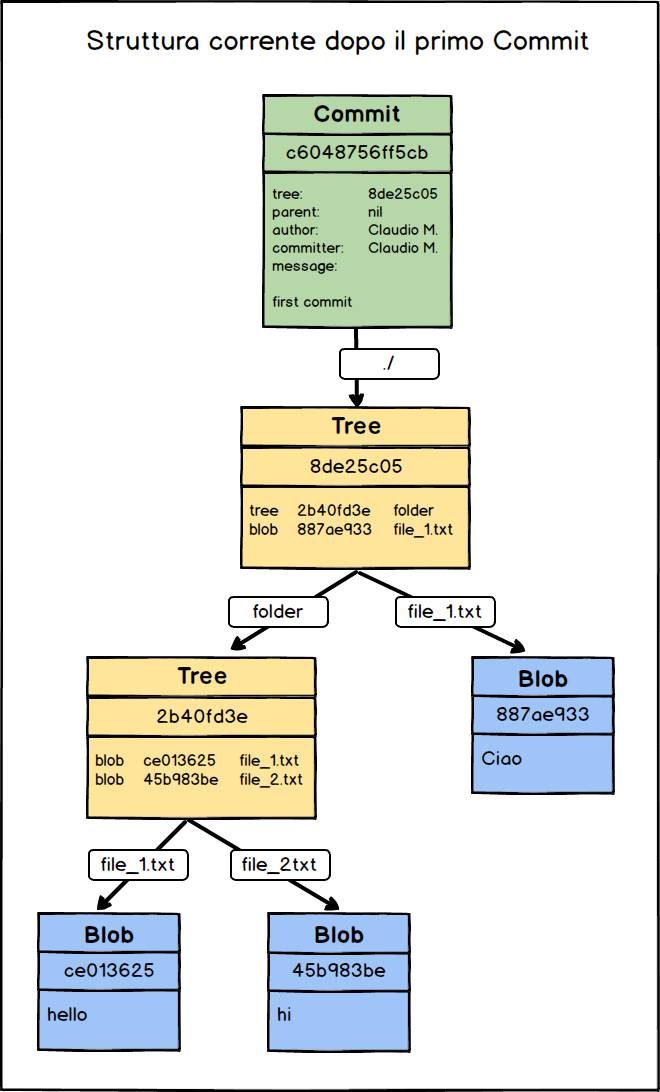
first commitAd ogni commit corrisponde quindi un file contenente le informazioni sull’autore, il committer, un riferimento a un altro oggetto di tipo Tree e uno al commit precedente. (mancante in questo caso perché è il primo commit) L’autore è la persona che ha originariamente scritto il codice. Il committer è colui che ha eseguito il commit per conto dell’autore originale. Non è detto che i due coincidano sempre. L’oggetto di tipo Tree è un altro oggetto mantenuto nella directory .git/objects. Si tratta di un file che mantiene al suo interno un elenco in cui su ogni riga sono presenti le informazioni relative a un oggetto di tipo Blob o a un altro oggetto Tree. Semplificando, possiamo dire che Git usa i file di tipo Blob per salvare il contenuto dei file e gli oggetti di tipo Tree per rappresentare la struttura delle cartelle. Eseguiamo il comando git cat-file usando il valore di hash relativo all’oggetto di tipo Tree presente nel commit.
[ test_git_repo ] (master) $ git cat-file -p 8de25c05b63cfa6e2fde45174214e6ecf740b9fe
100644 blob 887ae9333d92a1d72400c210546e28baa1050e44 file_1.txt
040000 tree 2b40fd3e05095cfa9e3618b99b65f5dba644452b folderPossiamo ripetere la precedente operazione e constatare che l’oggetto Tree relativo alla directory folder contiene le informazioni sui due file Blob usati per salvare il contenuto dei due file file_1.txt e file_2.txt.
# Possiamo usare i primi caratteri del valore di hash
# invece di digitare tutte le cifre
# Solitamente bastano 8 o 10 caratteri
[ test_git_repo ] (master) $ git cat-file -p 2b40fd3e
100644 blob ce013625030ba8dba906f756967f9e9ca394464a file_1.txt
100644 blob 45b983be36b73c0788dc9cbcb76cbb80fc7bb057 file_2.txtVediamo quindi qual è la struttura corrente degli oggetti salvati da Git attraverso un’immagine.
All’interno della directory base, modifichiamo ora il file file_1.txt e aggiungiamo un nuovo file che chiameremo file_0.txt.
// file_1.txt
file_1// file_0.txt
file_0Quindi, dopo aver eseguito il comando git status, eseguiamo un nuovo commit.
[ test_git_repo ] (master) $ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: file_1.txt
Untracked files:
(use "git add <file>..." to include in what will be committed)
file_0.txt
no changes added to commit (use "git add" and/or "git commit -a")
# aggiungiamo i file alla staging area
[ test_git_repo ] (master) $ git add .
# eseguiamo un nuovo commit
[ test_git_repo ] (master) $ git commit -m 'Aggiunge il file_0.txt e aggiorna file_1.txt'
[master 5629806] Aggiunge il file_0.txt e aggiorna file_1.txt
2 files changed, 2 insertions(+), 1 deletion(-)
create mode 100644 file_0.txtPossiamo lanciare nuovamente il comando git log e osservare che sono presenti due commit. Copiamo quindi il valore di hash relativo all’ultimo commit e visualizziamo nuovamente con un’immagine qual è la nuova struttura del repository.
[ test_git_repo ] (master) $ git log
commit 562980633630afe3b9f55ed26e97ce466dda3953
Author: Claudio M <claudio@example.com>
Date: Wed Dec 13 17:34:51 2017 +0000
Aggiunge il file_0.txt e aggiorna file_1.txt
commit c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
Author: Claudio M <claudio@example.com>
Date: Wed Dec 13 17:17:17 2017 +0000
first commit
# ispezioniamo il secondo commit
[ test_git_repo ] (master) $ git cat-file -p 56298063363
tree 84a6b2c966a8e0ff3d1729f9464b61ce55f44e53
parent c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
author Claudio M <claudio@example.com> 1513186491 +0000
committer Claudio M <claudio@example.com> 1513186491 +0000
Aggiunge il file_0.txt e aggiorna file_1.txt
# visualizziamo il contenuto dell'oggetto tree 84a6b
[ test_git_repo ] (master) $ git cat-file -p 84a6b
100644 blob da3b618df6318571857b9912fc8aa5d6bafbf192 file_0.txt
100644 blob b02de46733580a2d82931639b0f2dedef1a43fa5 file_1.txt
040000 tree 2b40fd3e05095cfa9e3618b99b65f5dba644452b folder
La struttura dati usata da Git prende il nome di Merkle DAG (Directed acyclic graph – grafo aciclico orientato). Se volete approfondire l’argomento potete leggere questo interessante articolo sui Merkle Tree.
Git Tag e Annotated Tag
Parliamo ora dei Tag che possono essere di due diverse tipologie: tag semplici (Lightweight Tag) e Annotated Tag.

Per quanto riguarda i tag semplici, si tratta di semplici etichette associate a uno specifico commit che possiamo creare con il seguente comando.
[ test_git_repo ] (master) $ git tag tag_semplice Gli Annotated tag sono invece dei veri e propri oggetti, salvati da Git all’interno della cartella .git/objects, che possiamo creare usando l’opzione ‘-a’. Possiamo anche associare un messaggio che verrà memorizzato all’interno del nuovo oggetto creato.
[ test_git_repo ] (master) $ git tag -a annotated_tag -m 'Messaggio associato al tag'È possibile elencare tutti i tag creati con il seguente comando:
[ test_git_repo ] (master) $ git tag
annotated_tag
tag_semplicePossiamo usare nuovamente il comando git cat-file anche con i tag passando come argomento il nome del tag o un valore di hash.
[ test_git_repo ] (master) $ git cat-file -p tag_semplice
tree 84a6b2c966a8e0ff3d1729f9464b61ce55f44e53
parent c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
author Claudio M <claudio@example.com> 1513186491 +0000
committer Claudio M <claudio@example.com> 1513186491 +0000
Aggiunge il file_0.txt e aggiorna file_1.txtCome detto, nel caso dei tag semplici, si tratta di semplici puntatori a un commit. Possiamo osservare che l’output del comando appena eseguito è identico a quello già ottenuto in precedenza nel caso dell’ultimo commit del repository.
Gli annotated tag sono invece dei veri e propri oggetti che contengono al loro interno delle informazioni come quelle mostrate in basso.
[ test_git_repo ] (master) $ git cat-file -p annotated_tag
object 562980633630afe3b9f55ed26e97ce466dda3953
type commit
tag annotated_tag
tagger Claudio M <claudio@example.com> 1513187494 +0000
Messaggio associato al tagÈ possibile eliminare un qualsiasi tag con il seguente comando.
[ test_git_repo ] (master) $ git tag -d nome_tagGit mantiene tutte le informazioni relative ai tag all’interno della cartella .git/refs/tags/. Al suo interno è presente un file per ciascun tag.
[ test_git_repo ] (master) $ ls -1F .git/refs/tags
annotated_tag
tag_sempliceIn ognuno dei file è conservato un valore di hash che fa riferimento o a un commit, nel caso dei tag semplici, o a un oggetto di tipo Annotated tag.
[ test_git_repo ] (master) $ git cat-file -p $(cat .git/refs/tags/annotated_tag)
object 562980633630afe3b9f55ed26e97ce466dda3953
type commit
tag annotated_tag
tagger Claudio M <claudio@example.com> 1513187494 +0000
Messaggio associato al tag
[ test_git_repo ] (master) $ git cat-file -p $(cat .git/refs/tags/tag_semplice)
tree 84a6b2c966a8e0ff3d1729f9464b61ce55f44e53
parent c6048756ff5cbb61bfabb6f95d1c559d9dbbf768
author Claudio M <claudio@example.com> 1513186491 +0000
committer Claudio M <claudio@example.com> 1513186491 +0000
Aggiunge il file_0.txt e aggiorna file_1.txtRicapitolando sono quattro i tipi di oggetti che Git salva all’interno della cartella .git/objects:
- Commit
- Tree
- Blob
- Annotated Tag
Introduzione al branch Master e al riferimento HEAD
Prima di concludere questa lezione, parliamo di un altro concetto fondamentale in Git. Facciamo riferimento ancora una volta al contenuto della cartella .git. Negli esempi visti in precedenza, il prompt dei comandi presentava fra parentesi tonde il nome del branch corrente (master). Cerchiamo di capire brevemente di cosa si tratta. Nel momento in cui effettuiamo il primo commit, Git conserva un puntatore a quel commit all’interno del file .git/refs/heads/master (Vedremo in uno dei prossimi articoli che Git salva all’interno di.git/refs/heads dei file per i diversi branch creati). Master è quindi il nome del branch creato di default da Git. Si tratta di un puntatore a un commit e man mano che creiamo dei nuovi commit, il puntatore si sposta e punta all’ultimo commit creato.

Dopo aver creato il secondo commit, viene aggiornato anche il file .git/refs/heads/master e il branch master punta nuovamente all’ultimo commit.
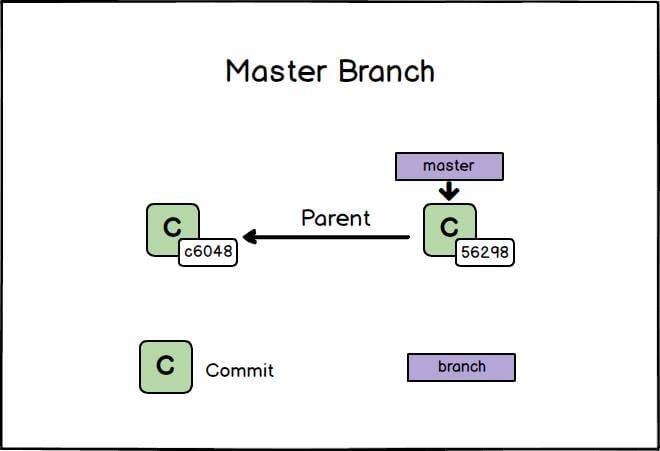
Possiamo verificare il tutto, visualizzando il contenuto del file .git/refs/heads/master che contiene al suo interno il valore di hash identificativo dell’ultimo commit creato.
[ test_git_repo ] (master) $ cat .git/refs/heads/master
562980633630afe3b9f55ed26e97ce466dda3953
# Il comando seguente corrisponde a git log --pretty=oneline --decorate=short
[ test_git_repo ] (master) $ git log --oneline --decorate
5629806 (HEAD -> master, tag: tag_semplice, tag: annotated_tag) Aggiunge il file_0.txt e aggiorna file_1.txt
c604875 first commitAbbiamo usato l’opzione –oneline per mostrare le informazioni dei commit su una singola linea e l’opzione –decorate per aggiungere all’output le informazioni relative ai nomi dei branch e dei tag i cui dettagli sono salvati nella directory .git/refs/. Possiamo altresì notare che viene mostrato un riferimento denominato HEAD che punta al branch corrente master. HEAD è un riferimento simbolico che in condizioni normali punta al branch corrente. Visto in altro modo, HEAD punta al genitore (parent) del prossimo commit. Git salva le informazioni su HEAD all’interno del file .git/HEAD. Parleremo nuovamente dell’argomento quando tratteremo i Branch in uno dei prossimi articoli.
[ test_git_repo ] (master) $ cat .git/HEAD
ref: refs/heads/master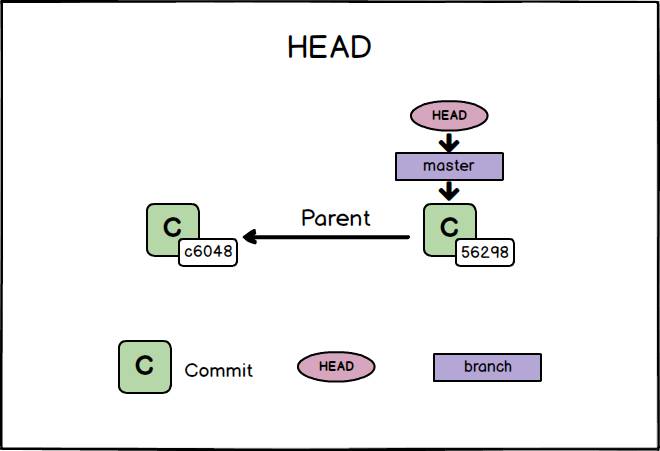
Conclusioni
In questa lezione abbiamo illustrato come fa Git a salvare i file all’interno del repository e conservare al suo interno le diverse versioni. Attraverso l’uso dell’algoritmo di hash SHA-1, viene generato un valore di hash per ogni oggetto salvato nelle sottocartelle della directory .git/objects, a partire dal suo contenuto. In questo modo Git attua un certo livello di protezione contro la perdita o la modifica involontaria di dati dal momento che le informazioni inserite in un oggetto non possono essere modificate se non cambiando il valore di hash e generando quindi un nuovo e differente oggetto. Nel prossimo mostreremo qualche altro esempio in cui vedremo come lavorare con dei file già esistenti e quale comandi mette a disposizione Git per rinominare, cancellare un file o annullare delle modifiche.