In questa lezione andremo alla scoperta dei "Replica Set" di MongoDB.
Cos’è un "Replica Set"?
Con il termine "Replica Set" si intende un insieme di istanze di mongod configurate per mantenere lo stessa copia di dati. Tali processi si occupano quindi di replicare le informazioni contenute in un database per garantire un certo livello di resistenza in caso di guasti.
Non bisogna però confondere la replica dei dati, che è il motivo per il quale viene creato un "Replica Set", con la distribuzione dei documenti su più macchine (Sharding) che sarà l’argomento della prossima lezione.
Nel caso di un "Replica Set" avremo un nodo primario Primary Node che riceve tutte le operazioni di scrittura e si occupa di replicarle in modo asincrono sui nodi secondari. In ogni istante i nodi secondari avranno una copia più o meno aggiornata di tutti i dati.
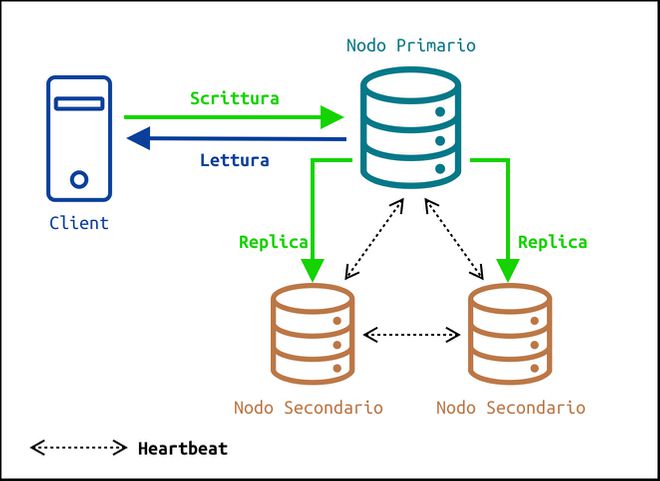
Il meccanismo di replica si basa sull’uso di una collezione speciale che prende il nome di Operations Log o Oplog.
Le operazioni di scrittura completate sul nodo primario vengono registrate nell’oplog di quest’ultimo in modo da poter essere replicate su altri nodi.
I nodi secondari ricevono poi una copia dell’operazioni mancanti in modo asincrono, le applicano ai dati da loro mantenuti e aggiornano la loro copia dell’oplog al fine di sapere in ogni momento qual è lo stato corrente del database.
Nel caso dello Sharding, invece, una collezione viene suddivisa e i suoi documenti vengono distribuiti su macchine diverse. MongoDB utilizza poi un sistema di indirizzamento per fare in modo che le interrogazioni del client vengano dirette verso il nodo che mantiene le informazioni.
In un "Replica Set" è presente un solo nodo primario ed una serie di nodi secondari. È possibile avere fino a 50 membri, ma i nodi che possono partecipare all’elezione del primario possono essere massimo 7.
La possibilità di avere un numero così elevato di nodi può essere utile per la distribuzione geografica dei dati consentendo di replicare copie dei dati su dei server che sono più vicini agli utenti.
Se il nodo primario non dovesse essere raggiungibile, i server secondari procedono all’elezione di un nuovo nodo primario scegliendo il candidato fra i membri rimasti che sono disponibili a ricoprire il ruolo.
Infatti i nodi secondari possono essere settati in modo da non poter mai diventare primari. Le ragioni sono molteplici, per esempio un nodo può essere utilizzato solo per effettuare un backup dei dati.
È il caso dei nodi nascosti (Hidden Nodes) che possono anche essere configurati per eseguire le operazioni di replica con un certo ritardo. In questo caso si parla di Delayed Nodes.
Avere dei nodi di questo tipo consente di aggiungere un certo grado di resilienza contro possibili episodi di corruzione dei dati a livello di applicazione. Per esempio, se abbiamo un nodo in ritardo di 3 ore e vengono eliminati per sbaglio dei documenti di una collezione, abbiamo 3 ore di tempo per recuperare i dati dal nodo che mantiene una copia non aggiornata senza dover eseguire il ripristino da precedenti backup.
In alcune configurazioni possono poi esistere dei nodi che ricoprono il ruolo di arbitro (Arbiter Node) e che non mantengono dati, ma partecipano all’elezione del nodo primario.
Configurare un Replica Set
Vediamo allora come configurare un "Replica Set" in locale anche se sarebbe ideale avere un processo di mongod in esecuzione su una macchina diversa.
Nella sua configurazione più semplice un "Replica Set" contiene 3 nodi, un nodo primario e due nodi secondari.
Nel nostro esempio useremo dei file per configurare tre istanze di mongod. Inizialmente saranno tre processi indipendenti finché non li collegheremo fra loro per comporre un "Replica Set".
In una nuova cartella creiamo allora tre file di configurazione node1.conf, node2.conf e node3.conf inizialmente vuoti. Creiamo poi due cartelle db e key. Nella cartella db aggiungiamo tre nuove cartelle node1, node2, node3, mentre nella cartella key creiamo un file replSet-keyfile che useremo nei tre file di configurazione per abilitare l’autenticazione interna fra i membri del "Replica Set" attraverso keyfile.
La struttura della cartella di lavoro da cui partiamo è quindi la seguente:
tree -L 2 .
.
├── db
│ ├── node1
│ ├── node2
│ └── node3
├── node1.conf
├── node2.conf
├── node3.conf
└── key
└── replSet-keyfile
5 directories, 4 filesCreare un keyfile per l’autenticazione interna dei nodi del "Replica Set"
Per prima cosa creiamo il file replSet-keyfile tramite openssl rand per generare una stringa di 1024 caratteri pseudo-casuali.
openssl rand -base64 756 > key/rplSet-keyfileSe non è già presente è necessario prima installare openssl sul nostro sistema operativo utilizzando un gestore di pacchetti.
Una volta creato il nuovo file, su Linux e macOs dovremo modificare i permessi per consentire la lettura solo al proprietario del file.
chmod 400 key/rplSet-keyfileModificare i file di configurazione *.conf
Dopo aver creato il file che useremo per l’autenticazione interna, possiamo definire la configurazione delle istanze andando a modificare i file con estensione .conf.
Il contenuto del file node1.conf è il seguente:
systemLog:
destination: file
path: full/path/to/mongodb/db/node1/mongod.log
logAppend: true
storage:
dbPath: full/path/to/mongodb/db/node1
net:
bindIp: 127.0.0.1
port: 27021
security:
authorization: enabled
keyFile: full/path/to/mongodb/key/replSet-keyfile
processManagement:
fork: true
replication:
replSetName: replSet-exampleDovremo indicare il percorso completo della cartella node1, del file di log mongod.log e del keyfile replSet-keyfile.
Per l’autenticazione interna dei nodi del "Replica Set" abbiamo usato il file replSet-keyfile creato in precedenza. Nel nostro esempio condividiamo lo stesso file per tutte le istanze visto che sono in esecuzione sulla stessa macchina. Se fossero lanciate su macchine diverse, dovremmo provvedere a copiare il keyfile su ciascun computer.
Abbiamo poi indicato l’indirizzo IP e la porta su cui resterà in ascolto la prima istanza di mongod. Tramite l’opzione security abilitiamo il controllo degli accessi e l’autenticazione interna fra server attraverso il file replSet-keyfile. Visto che vogliamo eseguire il processo in background assegniamo il valore true a processManagement.fork. Infine settiamo il nome del "Replica Set" di cui fa parte l’istanza di mongod attraverso replication.replSetName. Dovremo indicare lo stesso nome per tutti i 3 file di configurazione.
Di seguito riportiamo il contenuto dei file node2.conf e node3.conf in cui cambiato solo il percorso del file di log, della cartella storage.dbPath e la porta del server.
systemLog:
destination: file
path: full/path/to/mongodb/db/node2/mongod.log
logAppend: true
storage:
dbPath: full/path/to/mongodb/db/node2
net:
bindIp: 127.0.0.1
port: 27022
security:
authorization: enabled
keyFile: full/path/to/mongodb/key/replSet-keyfile
processManagement:
fork: true
replication:
replSetName: replSet-examplesystemLog:
destination: file
path: full/path/to/mongodb/db/node3/mongod.log
logAppend: true
storage:
dbPath: full/path/to/mongodb/db/node3
net:
bindIp: 127.0.0.1
port: 27023
security:
authorization: enabled
keyFile: full/path/to/mongodb/key/replSet-keyfile
processManagement:
fork: true
replication:
replSetName: replSet-exampleAvviare i 3 server indipendentemente
Una volta creato il keyfile ed editato i file di configurazione prestando attenzione che tutti i percorsi specificati siano già presenti, possiamo lanciare le tre istanze indipendentemente una dall’altra.
mongod --config path/to/node1.conf
about to fork child process, waiting until server is ready for connections.
forked process: 4046
child process started successfully, parent exitingmongod --config path/to/node2.conf
about to fork child process, waiting until server is ready for connections.
forked process: 4144
child process started successfully, parent exitingmongod --config path/to/node3.conf
about to fork child process, waiting until server is ready for connections.
forked process: 4187
child process started successfully, parent exitingA questo punto le tre istanze di mongod sono in esecuzione indipendentemente e non hanno ancora alcun modo per comunicare fra di loro.
Il prossimo passo sarà quello di collegarsi ad uno dei server per inizializzare il "Replica Set".
Collegarsi direttamente ad uno dei 3 server
Selezioniamo un nodo qualsiasi (nel nostro caso abbiamo scelto il primo nodo) e colleghiamoci specificando indirizzo IP e porta:
mongosh --host 127.0.0.1 --port 27021Una volta eseguito l’accesso, occorre eseguire il metodo rs.initiate() per inizializzare il "Replica Set". Tale metodo può ricevere anche un documento con la configurazione relativa a tutti nodi del "Replica Set", ma al momento possiamo anche invocarlo senza alcuna configurazione per poi aggiungere gli altri nodi in un secondo momento.
> rs.initiate()Creare i nuovi utenti ed effettuare l’accesso
Dopo aver inizializzato il "Replica Set", avendo attivato il meccanismo di gestione degli accessi, è necessario creare un nuovo utente con il ruolo userAdminAnyDatabase nel database admin.
> use admin
> db.createUser(
{
user: "adminUser",
pwd: passwordPrompt(),
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)A questo punto possiamo autenticarci con le credenziali del nuovo utente in due modi. O chiudiamo la sessione ed eseguiamo nuovamente l’accesso.
mongosh --host 127.0.0.1 --port 27021 -u "adminUser"Oppure invochiamo il seguente metodo senza terminare la sessione corrente.
db.getSiblingDB("admin").auth("adminUser", passwordPrompt())Possiamo ricevere conferma che l’accesso sia avvenuto in maniera corretta eseguendo il metodo db.runCommand() il quale indica quali sono gli utenti attualmente autenticati.
db.runCommand({connectionStatus: 1})Una volta effettuato l’accesso, l’utente adminUser può creare un nuovo utente nel database admin con il ruolo clusterAdmin che permette di eseguire una serie di operazioni di configurazione e gestione sui nodi del "Replica Set".
db.createUser(
{
"user": "ClusterGuy",
"pwd": passwordPrompt(),
roles: [ { role: "clusterAdmin", db: "admin" } ]
}
)Possiamo quindi terminare la sessione con il comando exit.
Collegarsi al "Replica Set"
Una volta creato l’utente ClusterGuy, possiamo usare le sue credenziali per accedere al "Replica Set". Dal momento che vogliamo collegarci al "Replica Set" e non ad un singolo nodo, dobbiamo specificare come valore dell’opzione –host l’indirizzo completo del nome del Replica Set. Così facendo, la shell cercherà di collegarsi al "Replica Set" ed userà il nodo indicato per determinare qual è il server primario verso il quale sarà poi stabilita la connessione.
mongosh --host "replSet-example/127.0.0.1:27021"
-u "ClusterGuy"
--authenticationDatabase "admin"Una volta completato l’accesso, possiamo controllare qual è lo stato corrente del "Replica Set" attraverso il seguente comando:
rs.status()Fra le tante informazioni presenti troviamo il campo members con l’elenco dei membri del "Replica Set". Al momento abbiamo un solo nodo, per cui vediamo come aggiungere gli altri.
Possiamo aggiungere degli altri nodi al "Replica Set" col comando rs.add() e passando come primo argomento un documento o una stringa che identifica il nodo.
Dal momento che le altre due istanze sono già in esecuzione sullo stesso computer, possiamo aggiungerle al "Replica Set" indicando indirizzo di loopback e porta.
> rs.add("127.0.0.1:27022")
> rs.add("127.0.0.1:27023")Se ora eseguiamo nuovamente il comando rs.status(), ci accorgiamo che nel campo members sono presenti anche gli altri due nodi.
Un altro comando utile è rs.isMaster() che restituisce un documento relativo ai nodi del "Replica Set". Sono anche presenti tre campi ismaster, secondary e primary che contengono delle informazioni in merito al nodo primario corrente. Se lanciamo il metodo rs.isMaster() sul nodo primario, il valore di secondary è pari a false, mentre primary è pari all’indirizzo completo del nodo.
rs.isMaster()
{
topologyVersion: {},
hosts: [
'localhost:27021',
'localhost:27022',
'127.0.0.1:27023'
],
setName: 'replSet-example',
setVersion: 5,
ismaster: true,
secondary: false,
primary: 'localhost:27021',
me: 'localhost:27021',
electionId: ObjectId("7fffffff0000000000000006"),
lastWrite: {},
maxBsonObjectSize: 16777216,
maxMessageSizeBytes: 48000000,
maxWriteBatchSize: 100000,
connectionId: 31,
minWireVersion: 0,
maxWireVersion: 13,
readOnly: false,
ok: 1,
'$clusterTime': {},
isWritablePrimary: true
}Failover e meccanismo di elezione
Per verificare che gli altri siano attivi e raggiungibili, i membri di un "Replica Set" inviano periodicamente fra loro dei pacchetti di dati (Heartbeat). La frequenza di questi pacchetti può essere determinata o configurata attraverso il metodo rs.conf().
rs.conf()
{
_id: 'replSet-example',
version: 5,
term: 6,
members: [
{
_id: 0,
host: 'localhost:27021',
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 1,
tags: {},
secondaryDelaySecs: Long("0"),
votes: 1
},
{
_id: 1,
host: 'localhost:27022',
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 1,
tags: {},
secondaryDelaySecs: Long("0"),
votes: 1
},
{
_id: 2,
host: '127.0.0.1:27023',
arbiterOnly: false,
buildIndexes: true,
hidden: false,
priority: 1,
tags: {},
secondaryDelaySecs: Long("0"),
votes: 1
}
],
protocolVersion: Long("1"),
writeConcernMajorityJournalDefault: true,
settings: {
chainingAllowed: true,
heartbeatIntervalMillis: 2000,
heartbeatTimeoutSecs: 10,
electionTimeoutMillis: 10000,
catchUpTimeoutMillis: -1,
catchUpTakeoverDelayMillis: 30000,
getLastErrorModes: {},
getLastErrorDefaults: { w: 1, wtimeout: 0 },
replicaSetId: ObjectId("6242e0d4c38ef89b65184231")
}
}Infatti nel documento restituito da rs.config() è presente un campo settings in cui troviamo la proprietà heartbeatIntervalMillis che indica proprio la frequenza con cui vengono inviati i segnali agli altri membri.
Se uno di questi non risponde entro heartbeatTimeoutSecs (valore predefinito 10 secondi), viene contrassegnato come inaccessibile.
Fra i nodi di un "Replica Set", il primario svolge un ruolo fondamentale e se è questo nodo ad essere inaccessibile, un client non può completare operazioni di scrittura verso il "Replica Set".
Per determinare quale nodo deve ricoprire la carica di primario, i membri di un "Replica Set" avviano un processo di elezione.
Un’elezione viene avviata in risposta ad una serie di eventi come:
- guasto, manutenzione o aggiornamento del nodo primario
- aggiunta di un nuovo nodo o cambio di topologia del "Replica Set"
- inizializzazione del "Replica Set"
- esecuzione del metodo
rs.stepDown()sul nodo primario - se i nodi secondari non riescono a raggiungere più il nodo primario per un periodo superiore ad
electionTimeoutMillis(vedi documento restituito dars.config()). In quest’ultimo caso si parla di Automatic Failover.
Nelle situazioni in cui si procede ad una nuova elezione del nodo primario, uno dei secondari può avviare la procedura proponendosi come nuovo nodo primario. Come possiamo vedere dal documento restituito dal metodo rs.config(), ogni nodo è caratterizzato da un campo priority che indica il grado di probabilità di essere eletto durante un’elezione. Il valore predefinito è 1, ma può essere modificato. Tutti i nodi con un valore superiore a 0 possono diventare nodi primari ed, aumentando il valore del campo priority, incrementano le possibilità di vincere l’elezione. I nodi con priorità 0 non possono essere eletti, ma hanno diritto di votare.
In caso di elezione, se un nodo secondario ha priorità superiore a 0 e presenta una versione aggiornata del database, può richiedere di essere eletto. Vota quindi per se stesso e chiede supporto agli altri nodi per la sua candidatura al fine di ottenere la maggioranza di voti.
Ogni "Replica Set" dovrebbe avere sempre un numero dispari di nodi votanti. Supponiamo infatti di avere tre nodi votanti, se due nodi presentano contemporaneamente la loro candidatura, basterà il terzo nodo per decretare a maggioranza un vincitore fra i due.
Nel caso di un numero pari di membri votanti, se due secondari si presentassero contemporaneamente per diventare il nodo primario, ci sarebbe la possibilità per ciascuno di ricevere lo stesso numero di voti dai nodi rimanenti. In questo caso si avrebbe un pareggio e sarebbe necessario ripetere l’elezione finché non verrebbe decretato un vincitore. Il problema con la ripetizione delle elezioni è che le applicazioni che richiedono di scrivere dei dati devono attendere che venga scelto un nodo primario. Un numero pari di nodi aumenta la probabilità che un’elezione debba essere ripetuta e per questo viene suggerito di mantenere un numero di elettori dispari.
Inoltre nel caso in cui ci fosse una partizione della rete e si formassero due gruppi separati con lo stesso numero di nodi, non sarebbe possibile procedere all’elezione perché nessun nodo dei due gruppi potrebbe ottenere la maggioranza di voti.
Per forzare un’elezione possiamo comunque eseguire il metodo rs.stepDown().
Se lanciamo prima il metodo rs.isMaster(), possiamo annotare qual è il nodo primario corrente. Una volta eseguito il metodo rs.stepDown(), cambia il prompt indicando che il nodo a cui eravamo collegati non è più il primario. Se eseguiamo nuovamente rs.isMaster(), visualizziamo un documento aggiornato in cui possiamo vedere qual è stato eletto come nuovo nodo primario.
"Write Concern"
L’introduzione di un "Replica Set" non cambia molto il modo in cui un client interagisce con il database.
In un "Replica Set" però il nodo primario si occupa di propagare le operazioni di scrittura verso server secondari. Così facendo, viene garantito un maggior livello di resistenza in caso di guasto di un server ed aumenta la probabilità di poter accedere comunque ai dati.
Quando un client effettua delle operazioni di scrittura può anche indicare il livello di conferma per poter ritenere l’operazione completata dal suo punto di vista. L’opzione da usare nei diversi metodi di scrittura e modifica prende il nome di writeConcern.
Consideriamo per esempio il metodo db.collection.insertOne(). Oltre al primo argomento che rappresenta il documento da inserire in una collezione, possiamo passare un secondo argomento con un campo writeConcern.
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)Al campo writeConcern assegniamo un documento come quello riportato sotto in cui abbiamo specificato due delle possibili opzioni di configurazione.
{ w : "majority", wtimeout : 100 }Trascuriamo per il momento wtimeout e concentriamoci invece sul campo w attraverso il quale indichiamo il numero di nodi del "Replica Set" che devono confermare l’avvenuta propagazione dell’operazione di scrittura affinché il client possa considerarla conclusa.
Maggiore è il numero di nodi che confermano una scrittura, maggiore è la probabilità che la scrittura sia duratura anche in caso di guasto.
Tuttavia un grado superiore di conferma implica che le operazioni di scrittura richiedino più tempo poiché è necessario attendere la risposta di un numero maggiore di nodi.
Al campo w possiamo assegnare un numero maggiore o uguale a zero o la stringa majority.
Se per esempio w è pari a 0, l’applicazione non attende alcuna conferma. In questo caso un’operazione di scrittura potrebbe avere esito positivo o negativo, ma non c’è modo di confermarlo. Viene solo accertato che sia stato possibile collegarsi al nodo primario e non sono si siano verificati errori durante la trasmissione dei dati.
Il livello predefinito però è w:1. Ciò significa che senza indicare esplicitamente il livello di conferma, un client attende di ricevere un riscontro da parte del nodo primario che confermi di aver ricevuto un’operazione di scrittura.
Ciò però non significa per forza che il nodo primario sia stato in grado di propagare la scrittura ai membri secondari. Vuol dire invece che dal punto di vista dell’applicazione è sufficiente che il nodo primario abbia confermato l’operazione, ma non vi è alcuna garanzia (e l’applicazione non lo richede nemmeno) che l’operazione sia stata propagata ai nodi secondari correttamente.
Livelli di conferma maggiori di 1 (writeConcern.w > 1) richiedono che almeno un nodo secondario confermi una certa operazione di scrittura. In questo modo aumentiamo il livello di durabilità di un’operazione di scrittura che però richiede più tempo per ottenere la conferma di propagazione da parte di un numero maggiore di nodi.
Un livello di conferma pari a "majority" significa che è necessario attendere che la maggioranza dei nodi (numero di nodi diviso 2 ed arrotondato all’intero superiore) confermi la propagazione di un’operazione. In un "Replica Set" di tre nodi vuol dire che il nodo primario ed uno dei secondari devono dare riscontro della ricezione dell’operazione. In questo caso quindi l’applicazione resta in attesa che il nodo primario confermi che almeno uno dei nodi secondari abbia ricevuto l’operazione di scrittura.
Se un livello di conferma maggiore aumenta da un lato la durabilità delle operazioni di scrittura, dall’altro può causare delle attese significative a carico del client prima di ricevere conferma da parte del "Replica Set". Nel caso in cui dei nodi non fossero raggiungibili e non si riuscisse ad ottenere il livello di conferma richiesto, un’operazione di scrittura verrebbe sospesa in modo indefinito.
In questi casi può essere utile usare l’opzione wtimeout espressa in millisecondi che è valida solo per livelli di conferma superiori a 1 (w: 1). Se un’operazione di scrittura non ottiene il riscontro richiesto entro il numero di millisecondi espresso da wtimeout, viene restituito un errore. Ciò non significa comunque che l’operazione di scrittura è fallita. Vuol dire invece che entro il tempo espresso da wtimeout non è stato possibile ricevere il grado di conferma atteso dall’operazione.
Preferenze di lettura
Le operazioni di lettura sono rivolte sempre verso il nodo primario del "Replica Set" a meno che non si indichi esplicitamente il contrario.
db.restaurants.find({cuisine: 'Italian'}).readPref('secondary')Nella shell possiamo specificare una diversa preferenza attraverso il metodo cursor.readPref() a cui passiamo un argomento di tipo stringa corrispondente a uno dei 5 metodi di lettura supportati.
- primary è il valore predefinito. In questo caso tutte le richieste sono dirette verso il nodo primario.
- primaryPreferred dirige le operazioni di lettura verso il nodo primario, ma nel caso in cui non fosse disponibile verrebbe contattato un nodo secondario
- secondary indica che è sufficiente contattare un nodo secondario per la lettura dei dati
- secondaryPreferred segnala che per le operazioni di lettura si preferisce inviare le richieste ad un nodo secondario, ma se non ci sono nodi secondari disponibili viene contattato il nodo primario.
- nearest vuol dire che le operazioni di lettura devono essere dirette verso il nodo con la latenza di rete minima, indipendentemente dal tipo di nodo. Questa opzione può essere utile se si preferisce minimizzare il tempo di ricezione di una risposta da parte del server e non è particolarmente importante ottenere dei dati necessariamente aggiornati.
Per preferenze di lettura diverse da primary, è necessario considerare il possibile rischio che i dati ottenuti non siano aggiornati. Ciò può verificarsi se un nodo secondario non ha ancora completato il processo di replica delle operazioni del nodo primario.
Nella prossima lezione…
Dopo aver parlato del meccanismo di replica per garantire l’accesso ai dati anche in caso di guasto di uno o più server, nella prossima lezione vedremo un’altra funzionalità chiave di MongoDB. Illustreremo infatti quali sono gli strumenti disponibili per frammentare (Sharding) e distribuire i documenti di una collezione su più macchine. In questo modo potremo aumentare le capacità di un sistema attraverso un’espansione orizzontale su più macchine (Horizontal Scaling) invece di incrementare le risorse di uno o più server (Vertical Scaling).