In questa lezione parleremo di altri due comandi che possono essere utilizzati per ripristinare lo stato della Working Area o della Staging Area o per annullare delle modifiche nel repository. Vedremo come usare i comandi git reset e git revert. Bisogna prestare particolare attezione all’uso del comando git reset perché in alcuni casi specifici può causare delle modifiche dello stato delle aree di lavoro da cui è complicato, se non impossibile, tornare indietro. Ciò può causare la perdita di dati e rendere difficile il recupero di eventuali file o directory cancellate.
Il comando git reset
Iniziamo a parlare del comando git reset di cui vedremo due possibili modalità d’uso.
Prima forma del comando git reset
Una prima forma si comporta in maniera simile al comando git checkout quando a quest’ultimo passiamo come argomento il percorso di uno o più file. La sostanziale differenza è che in questo caso vengono aggiornati i rispettivi file della Staging Area.

git reset [-q] [<tree-ish>] [--] <percorso-file>...Nel comando in alto, l’opzione -q serve ad indicare che vogliamo vengano riportati solo eventuali errori. Possiamo passare il percorso di uno o più file che intendiamo ripristinare nella Staging Area. Anche se opzionale, è consigliato precedere tali percorsi da ‘–‘ (doppio dash) per evidenziare che si tratta di file ed evitare eventuali ambiguità con il nome di un branch. Un ultimo argomento opzionale che, nel caso non sia indicato, viene sostituito da HEAD è tree-ish. Con tale termine si fa riferimento a un identificatore che può essere un commit, un tag, un oggetto di tipo Tree o un qualsiasi riferimento che conduca alla fine a un oggetto di tipo Tree. Come abbiamo visto, nel caso degli oggetti di tipo commit, era presente al loro interno un riferimento a un oggetto di tipo Tree. Nel caso venga usato l’identificativo di un commit come argomento, viene prelevato il riferimento all’oggetto di tipo Tree in esso contenuto.
Seconda forma del comando git reset
git reset [--soft | --mixed | --hard] [-q] [<commit>]La seconda forma del comando git reset che analizziamo in questa lezione modifica il valore del commit referenziato da HEAD. Detto in altri termini, sposta HEAD in modo che punti al commit passato come argomento. A seconda dell’opzione usata ([–soft | –mixed | –hard]), sono coinvole in diverso modo nell’operazione: il repository, la staging area o la working directory. Se non viene specificato nessun <commit>, viene usato HEAD come valore predefinito.
Vediamo quindi quali sono le principali differenze fra le tre possibili opzioni principali.
Git reset con opzione –mixed
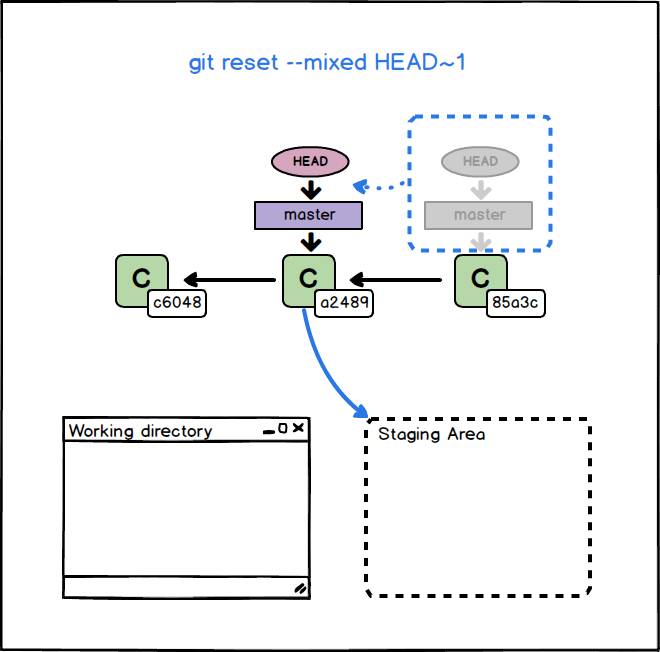
L’opzione –mixed è quella di default. Viene spostato il branch corrente in modo da puntare al commit passato come argomento. La working area non subisce nessun cambiamento. La Staging Area, al contrario, viene modificata in modo da rispecchiare la struttura dell’oggetto Tree ‘contenuto’ nel nuovo commit. Lanciando il comando git status dopo il comando git reset –mixed <commit>, noteremo che la Staging Area contiene tutti i file presenti nel <commit>, pronti per essere aggiunti nuovamente al repository in un altro commit. È come se avessimo aggiunto i file presenti nella specifica versione del <commit> alla staging area.
# All'inizio configurazione_pc.txt il file è vuoto
$ touch configurazione_pc.txt
$ git add .
$ git commit -m 'first commit'
$ echo 'AMD Ryzen 3 1200' > configurazione_pc.txt
$ git add .
$ git commit -m 'aggiunge il processore al file configurazione_pc.txt'
$ git log --oneline
93d0a54 (HEAD -> master) aggiunge il processore al file configurazione_pc.txt
4bf36ef first commit
$ git reset HEAD~1
Unstaged changes after reset:
M configurazione_pc.txt
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: configurazione_pc.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ cat configurazione_pc.txt
AMD Ryzen 3 1200Git reset con opzione –hard
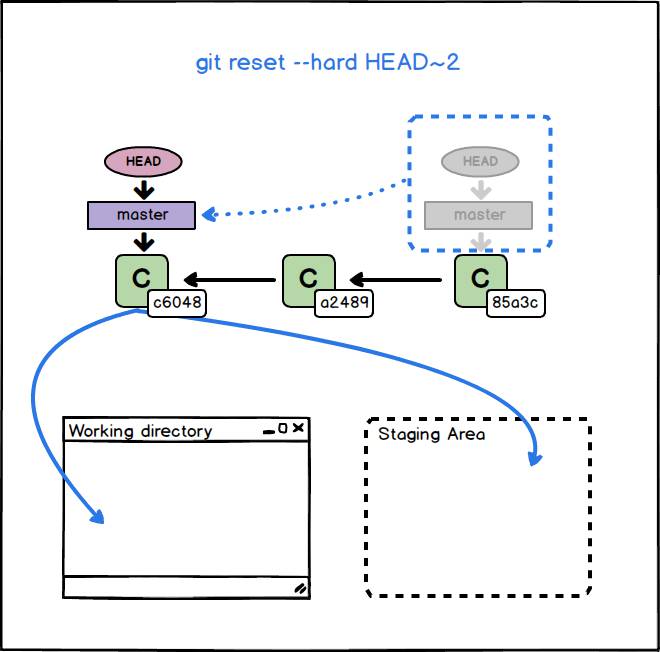
L’opzione –hard è quella più rischiosa e distruttiva delle tre. Il branch corrente viene spostato in modo da puntare al nuovo <commit>. Contemporaneamente viene modificato il contenuto della Staging Area e della Working Directory in modo da rispecchiare la struttura dell’oggetto Tree ‘contenuto’ nel <commit>. Eventuali modifiche presenti nella working area vengono perse. Allo stesso modo file nuovi, non presenti in <commit>, vengono cancellati.
Git reset con opzione –soft
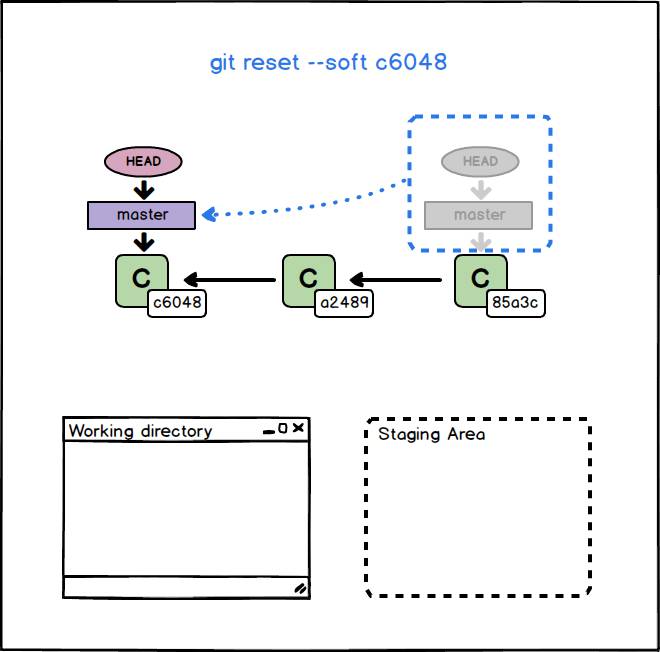
Con l’opzione –soft viene spostato il branch corrente in modo da puntare al commit passato come argomento. Si tratta dell’opzione più semplice e meno distruttiva delle tre dal momento che viene interessato solo il repository e ci si limita a spostare il branch corrente.
Ripristinare lo stato delle aree di lavoro con git reflog
Il comando git reset può essere distruttivo e causare delle modifiche per cui risulta difficile il ripristino di una delle aree di lavoro ad uno stato precedente. Facciamo un semplice esempio in cui aggiungiamo un file ed eseguiamo il primo commit, poi inseriamo del testo nel file ed eseguiamo un secondo commit.
$ git init
$ touch configurazione_pc.txt
$ git add .
$ git commit -m 'first commit'
$ echo 'AMD Ryzen 3 1200' > configurazione_pc.txt
$ git commit -am 'aggiunge un processore al file configurazione_pc.txt'
$ git log --oneline
c016b5f (HEAD -> master) aggiunge un processore al file configurazione_pc.txt
8140745 first commitSupponiamo di lanciare per qualche motivo il seguente comando:
$ git reset --hard HEAD~
HEAD is now at 8140745 first commit
$ git log --oneline
8140745 (HEAD -> master) first commit
$ git status
On branch master
nothing to commit, working tree cleanCome risulta dall’output del comando git log, è stato eliminato un commit. Anche il file configurazione_pc.txt presente nella working directory è stato riportato allo stato iniziale ed è ora vuoto. Le informazioni contenute nel file configurazione_pc.txt sembrerebbero perse per sempre. A questo punto possiamo provare due possibili strade per cercare di ripristinare il contenuto del file configurazione_pc.txt. Se abbiamo salvato o scritto da qualche parte l’identificatore del commit eliminato (nel nostro caso c016b5f), possiamo lanciare il seguente comando:
$ git reset --hard <commit_eliminato>In caso non dovessimo avere più accesso all’identificatore del commit, un’altra strada che possiamo tentare è quella di lanciare il comando git reflog che mostra un elenco delle ultime modifiche subite da HEAD e da altri riferimenti all’interno del repository.
$ git reflog
git reflog
8140745 (HEAD -> master) HEAD@{0}: reset: moving to HEAD~
c016b5f HEAD@{1}: commit: aggiunge un processore al file configurazione_pc.txt
8140745 (HEAD -> master) HEAD@{2}: commit (initial): first commitCome possiamo notare, sono stati registrati tutti i movimenti di HEAD all’interno del repository.
Lanciamo allora il seguente comando per ripristinare il commit che sembrava perso per sempre.
$ git reset --hard HEAD@{1}
HEAD is now at c016b5f aggiunge un processore al file configurazione_pc.txt
$ git log --oneline
c016b5f (HEAD -> master) aggiunge un processore al file configurazione_pc.txt
8140745 first commit
$ cat configurazione_pc.txt
AMD Ryzen 3 1200Bisogna evidenziare che siamo riusciti a ripristinare il file configurazione_pc.txt a partire da un commit che era stato eliminato dal repository. Solo grazie alle informazioni contenute in precedenza nel repository, siamo riusciti a recuperare i dati che sembravano persi. Se ci fossero state delle modifiche nella working area non salvate nel repository al momento dell’esecuzione del comando git reset –hard, probabilmente non saremmo riusciti a recuperarle e sarebbero andate perse per sempre.
Il comando git revert
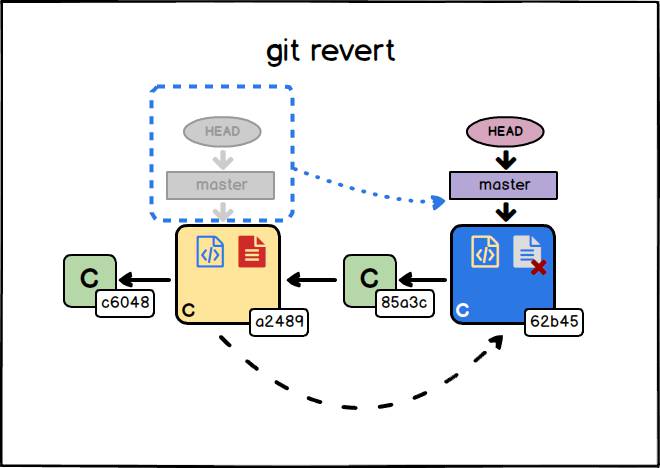
# comando git revert
git revert <commit_da_invertire>Il comando git revert è un altro comando che può essere usato per annullare delle operazioni. Al contrario del comando git reset, viene creato un nuovo commit che inverte le modifiche introdotte nel <commit_da_invertire>. Il nuovo commit creato, avrà come genitore il commit a cui punta HEAD prima dell’esecuzione del comando git revert. Il branch corrente viene quindi spostato in modo da puntare al commit appena creato. In quest’ultimo vengono invertite le modifiche introdotte dal <commit_da_invertire>. Con riferimento all’immagine sopra, se nel commit a2489 è stata aggiunta una riga al file blu ed è stato creato il file rosso, nel commit 62b45, che lo inverte, viene eliminato il file rosso e viene rimossa la riga aggiunta nel commit a2489.
Vediamo un semplice esempio.
$ git int
$ touch file1.txt
$ git add .
$ git commit -m 'first commit'
[master (root-commit) 3c57c2c] first commit
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 file1.txt
$ echo ciao > file1.txt
$ touch file2.txt
$ git add .
$ git commit -m 'modifica file1.txt e aggiunge file2.txt'
[master 06fcb03] modifica file1.txt e aggiunge file2.txt
2 files changed, 1 insertion(+)
create mode 100644 file2.txt
$ touch file3.txt
$ git add .
$ git commit -m 'aggiunge file3.txt'
[master 75497b1] aggiunge file3.txt
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 file3.txt
$ git log --oneline
75497b1 (HEAD -> master) aggiunge file3.txt
06fcb03 modifica file1.txt e aggiunge file2.txt
3c57c2c first commit
$ ls
file1.txt file2.txt file3.txt
$ cat file1.txt
ciao
$ git revert HEAD~
# processo git revert in corso...Lanciato il comando git revert con argomento il commit che precede quello referenziato da HEAD tramite il branch master, Git mostrerà l’editor predefinito e ci chiederà di modificare il messaggio del nuovo commit. Lasciamo invariato il file e salviamo il tutto.
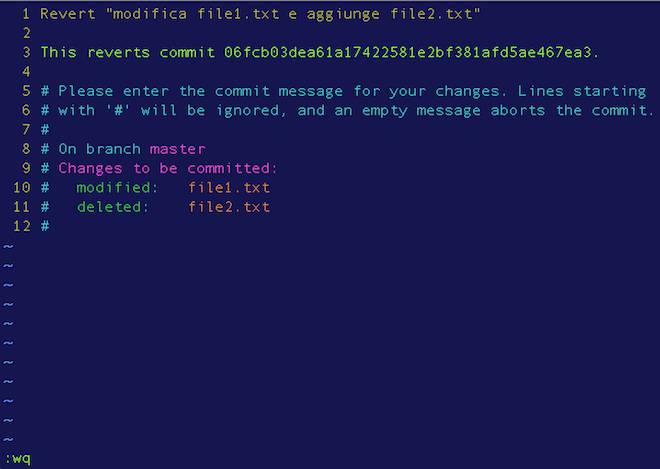
$ git revert HEAD~
[master 7e26535] Revert "modifica file1.txt e aggiunge file2.txt"
2 files changed, 1 deletion(-)
delete mode 100644 file2.txt
$ git log --oneline
7e26535 (HEAD -> master) Revert "modifica file1.txt e aggiunge file2.txt"
75497b1 aggiunge file3.txt
06fcb03 modifica file1.txt e aggiunge file2.txt
3c57c2c first commit
$ ls
file1.txt file3.txt
# file1.txt a questo punto è vuoto. L'unica riga in esso presente è stata cancellata.
$ cat file1.txtConclusioni
In questa lezione abbiamo visto come usare i comandi git reset e git revert in diverse situazioni. Il comando git reset può risultare distruttivo e comunque cambiare la struttura del repository. Per questo motivo è consigliato usarlo solo per annullare delle modifiche su branch locali che non verranno usati da altri membri di un team. Per branch condivisi è preferibile usare il comando git revert che non rimuove alcun commit dal repository, ma mantiene il commit che si desidera rimuovere creando un nuovo commit che inverte le modifiche introdotte dal commit indesiderato. Nella prossima lezione vedremo come usare il comando git bisect per individuare, attraverso ricerca binaria, un commit che ha introdotto qualche bug o altro problema in un progetto.