SQL Server è un sistema di gestione di database (DBMS – DataBase Management System) che si colloca in un mercato in cui si trova a competere con diversi altri DBMS ed in particolare con Oracle e Sybase.
Oracle è un DBMS largamente utilizzato e non si può negare che rappresenti un ottimo prodotto con cui lavorare, sebbene sia più complesso da installare e amministrare rispetto a SQL Server. Si tratta di una soluzione scelta da compagnie di grandi dimensioni per le sue caratteristiche di scalabilità, per le prestazioni e perchè fornisce una grande flessibilità riguardo agli strumenti addizionali che si possono utilizzare. Tuttavia esso dal punto di vista dei programmatori non si presenta così semplice da utilizzare come SQL Server, che fornisce strumenti ad hoc per la progettazione di strutture di database complete.
Sybase è molto simile a SQL Server ma presenta un grosso limite: l’assenza di un’interfaccia grafica che permetta agli utenti di interagire con il database. Questo DBMS solitamente viene utilizzato su macchine Unix, è veloce e robusto ma non fornisce il ricco linguaggio di programmazione e le funzionalità avanzate di SQL Server.
Ogni database ha la propria sintassi e i tre DBMS citati utilizzano la stessa, conosciuta con il nome di ANSI-92. Questo significa che la sintassi per interrogare i dati e per svolgere le altre operazioni è uguale nei tre sistemi, ma ciascun database ha una propria sintassi speciale per effettuare operazioni avanzate.
SQL Server sembra essere la soluzione giusta sia per realtà di grandi dimensioni, sia per ambiti più ristretti perchè a costi minori rispetto ad Oracle fornisce una soluzione molto scalabile e performante. Inoltre, come vedremo, SQL Server è molto semplice da installare e viene fornito in diverse versioni a seconda delle funzionalità che si desidera utilizzare.
Il DBMS di casa Microsoft è stato lanciato nel 1988 e ha subito diversi miglioramenti e restyling nel corso degli anni fino a giungere alla versione 2008, oggetto della presente guida. Le modifiche più significative in realtà sono state introdotte con SQL Server 2005, in cui varie aree sono state riprogettate e migliorate rispetto alle versioni precedenti e in cui è stata realizzata l’integrazione con le funzionalità del .NET Framework.
L’obiettivo di SQL Server 2008 è quello di gestire tutte le forme possibili di dati. Esso si basa sull’infrastruttura di SQL Server 2005 ma offre nuovi tipi di dati, nuove funzionalità e la possibilità di utilizzare il Language Integrated Query, conosciuto con il nome di LINQ. Esso permette inoltre di operare su dati in formato XML e tante altre funzionalità molto interessanti che analizzeremo nel corso della guida.
SQL Server 2008 è disponibile nelle seguenti versioni:
- SQL Server 2008 Enterprise – Piattaforma integrata per la gestione dati e la business intelligence, in grado di fornire scalabilità, applicazioni di data warehousing, sicurezza, analisi e report avanzati. Con questa edizione è possibile effettuare processi transazionali online su larga scala.
- SQL Server 2008 Standard – Piattaforma di gestione dati e business intelligence dotata di facilità d’uso e di gestione per eseguire applicazioni relative tipicamente ai singoli dipartimenti aziendali.
- SQL Server 2008 Workgroup – Piattaforma di gestione dati e creazione report che offre funzionalità di gestione e sincronizzazione remota sicure per l’esecuzione di applicazioni di filiale. Questa edizione include caratteristiche chiave del database ed è facilmente aggiornabile all’edizione Standard o Enteprise.
- SQL Server 2008 Web – Appositamente progettata per gli ambienti dedicati ai servizi web ad elevata disponibilità eseguibili su Windows Server. SQL Server 2008 Web fornisce qualsiasi tipo di supporto per tutte le applicazioni web.
- SQL Server 2008 Developer – Permette agli sviluppatori di realizzare e testare qualsiasi tipo di applicazione con SQL Server. Questa edizione comprende tutte le funzionalità di SQL Server Enterprise, ma la licenza è limitata solo allo sviluppo, al test e alle demo. Le applicazioni e i database sviluppati su questa edizione possono essere facilmente aggiornati alla versione Enterprise.
- SQL Server 2008 Express – Edizione gratuita di SQL Server per imparare a costruire applicazioni desktop o per piccoli server.
- SQL Server Compact 3.5 – Versione gratuita ideale per costruire applicazioni stand-alone e occasionalmente connesse per dispositivi mobili, desktop e client web. SQL Server Compact è supportato da tutte le piattaforme Windows, inclusi i sistemi operativi Windows XP e Windows Vista, e da tutti i Pocket PC e gli smartphone.
Per quanto riguarda i requisiti hardware Microsoft raccomanda per SQL Server 2008 un processore da almeno un 1GHz per le versioni a 32 bit e da 1.6GHz per le versioni a 64 bit. Almeno 512 MB di memoria RAM, anche se la quantità di memoria influenza molto le prestazioni e quindi sarebbe meglio averne a disposizione almeno 1GB (soprattutto per utilizzare la versione Enterprise di SQL Server). E’ inoltre opportuno avere a disposizione un hard disk da almeno 80 GB, mentre per quanto riguarda il sistema operativo per il lato client è possibile utilizzare Windows 7, Vista o XP, mentre per il lato server Windows Server 2003 (con service pack 2) o Windows Server 2008.
Sistemi di database
Un sistema di database è un insieme di diversi componenti tra cui:
- Programmi per la gestione di database
- Componenti client
- Uno o più server di database
- Diversi database
Un programma per la gestione di un database (DBMS – DataBase Management System), come SQL Server, è un software tecnicamente specifico che viene progettato ed implementato da compagnie specializzate nel settore. Di contro un componente client è un software generico che permette agli utenti di consultare i dati presenti su un database.
I server di database servono per la gestione dai dati contenuti in vari database e ogni componente client comunica con essi inviando opportune query che vengono processate ed il cui risultato viene inviato come risposta al client.
Un database invece può essere visto da due prospettive differenti. La prima è quella dell’utente che lo vede come una collezione di dati correlati; la seconda è quella del sistema di gestione di database (DBMS) che lo vede semplicemente come una serie di byte, tipicamente memorizzati su un disco rigido.
E’ fondamentale che un sistema di database fornisca alcune caratteristiche e meccanismi fondamentali:
- Varietà di interfacce utente
- Indipendenza fisica dei dati
- Indipendenza logica dei dati
- Ottimizzazione delle query
- Integrità dei dati
- Controllo di concorrenza
- Funzionalità di backup e ripristino
- Funzionalità di sicurezza
La maggior parte di tali caratteristiche e funzionalità sono assicurate dal DBMS utilizzato.
Varietà di interfacce utente
Molti database sono progettati per essere utilizzati da diversi tipi di utenti con vari livelli di conoscenza. Per tale ragione un DBMS dovrebbe offrire diverse interfacce utente a diversi target di utenti.
Indipendenza fisica dei dati
Indipendenza fisica dei dati significa che le applicazioni che operano sui dati di un database non dipendono dalla struttura fisica dei dati memorizzati. Questa importante caratteristica permette di effettuare modifiche ai dati senza dover modificare i programmi applicativi che si interfacciano con gli stessi. Per esempio se i dati memorizzati all’interno del database prima sono ordinati secondo un certo criterio e poi tale criterio viene variato, tale modifica fisica non influisce né sulle applicazioni esistenti, né sullo schema del database stesso.
Indipendenza logica dei dati
Indipendenza logica dei dati significa che è possibile effettuare modifiche alla struttura logica di un database senza dover effettuare alcuna modifica ai programmi che operano sul database stesso.
Ottimizzazione delle query
Ogni DBMS contiene un componente chiamato ottimizzatore (optimizer) che considera diverse strategie di esecuzione per l’interrogazione dei dati e poi seleziona quella più efficiente. La strategia selezionata è chiamata piano di esecuzione (execution plan) della query.
Integrità dei dati
Uno degli obiettivi fondamentali di un DBMS è quello di identificare dati logicamente inconsistenti (ad esempio la data 30 febbraio) ed impedire la relativa memorizzazione su un database. Questo obiettivo può essere assicurato dai programmi applicativi o dal DBMS stesso.
Controllo di concorrenza
Un database può essere interrogato e modificato da diverse applicazioni nello stesso momento e per tale motivo un DBMS deve avere qualche tipo di meccanismo di controllo per assicurare che le diverse applicazioni che tentano di modificare gli stessi dati lo facciano in un modo controllato.
Funzionalità di backup e ripristino
Un DBMS deve avere un sistema in grado di effettuare il ripristino dei database in caso di errori hardware o software.
Funzionalità di sicurezza
La sicurezza di un database si basa su due concetti fondamentali: autenticazione e autorizzazione. L’autenticazione è il processo di validazione delle credenziali degli utenti per prevenire utilizzi non consentiti del sistema. Tipicamente tale obiettivo viene raggiunto utilizzando username e password. L’autorizzazione è il processo successivo all’autenticazione e consiste nell’individuazione delle risorse che un determinato utente può utilizzare dopo essersi autenticato.
Panoramica di SQL Server 2008
L’obiettivo di Microsoft con il rilascio di SQL Server 2008 è quello di facilitare e migliorare il lavoro degli amministratori di database e dei programmatori di applicazioni che si interfacciano con tali sistemi. Per raggiungere questo obiettivo la versione 2008 del DBMS (Data Base Management System) offre una grande varietà di nuove caratteristiche e funzionalità.

In particolare gli amministratori di database che utilizzano già SQL Server 2005 troveranno nella versione 2008 tutti gli strumenti che utilizzano quotidianamente nel proprio lavoro e noteranno che molti di essi sono stati arricchiti e migliorati.
E possibile suddividere le novità principali in varie categorie: gestione, scalabilità, prestazioni, sicurezza, sviluppo.
Gestione
La prima caratteristica da citare nell’ambito della gestione dei database è la gestione delle policy (Policy Management). Le policy sono insiemi di regole che possono essere stabilite su un server per fare in modo che tutte le workstation collegate siano gestite allo stesso modo e presentino le stesse caratteristiche. Tale gestione permette dunque di creare ed eseguire diverse regole di configurazione su uno o più server di database. Tramite tali regole l’amministratore del database può stabilire che la configurazione standard dei settaggi venga applicata e mantenuta su ciascuno dei server e dei database coinvolti.
Altra funzionalità da citare è la cosiddetta Multiple Server Interaction and Configuration Servers, che permette di eseguire nello stesso momento interrogazioni su dati residenti su diversi server. E’ possibile registrare i diversi server nel Management Studio di SQL Server ed inserirli in uno stesso gruppo. Quando poi si rende necessario applicare una policy o eseguire una query su tutti i server del gruppo basta cliccare con il tasto destro del mouse sul gruppo ed effettuare l’operazione desiderata. Questa funzionalità può essere configurata per restituire un insieme di risultati per ogni server oppure per unire tutti i risultati in un unico insieme.
Un’altra interessante nuova funzionalità di gestione è il Data Collector. Spesso gli amministratori di database infatti hanno la necessità di raccogliere dati di gestione da un diverso numero di server. Il Data Collector è un meccanismo che facilità questa attività e permette di utilizzare il SQL Server Agent e Integration Services per creare un frame work che raccolga e memorizzi i dati di interesse, fornendo anche funzionalità di gestione degli errori.
Scalabilità
Nel corso degli anni le dimensioni di un database tendono a crescere in modo considerevole e sono necessari strumenti per gestire questo aspetto. Per tale motivo SQL Server 2008 introduce alcune nuove caratteristiche che semplificano queste operazioni ed in particolare mette a disposizione una funzionalità di compressione predefinita dei file dei database e dei file relativi ai transaction log. Anche SQL Server 2005 permetteva la compressione dei dati in un file di sola lettura, utilizzando la modalità di compressione di Windows, ma nella versione 2008 è possibile anche scegliere il livello di compressione (a livello di riga o di pagina). Questi tipi di compressione riducono la quantità di spazio richiesto e la quantità di memoria necessaria a manternere i dati, con i relativi ovvi benefici. SQL Server 2008 introduce anche la compressione a livello di backup.
Un altro strumento molto utile è il cosiddetto Resource Governor (gestore delle risorse). Questa funzionalità serve a gestire il carico di lavoro e l’utilizzo delle risorse di sistema da parte di SQL Server, consentendo di specificare limiti sulla quantità di CPU e memoria che le richieste dell’applicazione in ingresso possono utilizzare. Questo si traduce in un utilizzo più efficiente delle risorse del sistema.
Prestazioni
Grazie a diverse nuove caratteristiche di SQL Server 2008 è possibile controllare e monitorare in modo molto preciso le prestazioni dei database e delle applicazioni che si interfacciano con essi. Quando vengono eseguite un gran numero di transazioni al secondo i blocchi, necessari durante l’esecuzione delle stesse, potrebbero avere un impatto negativo sulle prestazioni delle applicazioni che operano sullo stesso database. SQL Server è progettato proprio per ridurre il numero totale di blocchi generati dai vari processi e lavora su un meccanismo di partizionamento delle tabelle.
Sicurezza
SQL Server 2005 ha introdotto la sicurezza dei dati tramite l’utilizzo della crittografia ma con SQL Server 2008 tale aspetto è stato migliorato con l’introduzione di due nuove caratteristiche: Extensible Key Management e Transparent Data Encryption.
Il primo strumento fornisce opportuni meccanismi per memorizzare in modo sicuro le chiavi utilizzate nell’infrastruttura di crittografia. Il secondo offre una maggiore flessibilità nella crittografia dei dati, rendendo la crittografia una proprietà del database e non soltanto il risultato di una funzione, facilitando il lavoro degli amministratori quando essi vogliono effettuare la crittografia a livello di dati.
Sviluppo
SQL Server 2008 naturalmente fornisce una grande varietà di nuove caratteristiche volte a migliorare e facilitare il lavoro dei programmatori di database che vanno da miglioramenti del linguaggio T-SQL a nuovi componenti per creare ed utilizzare query.
Una prima cosa da sottolineare è che è stato migliorato il supporto a LINQ creando un nuovo provider LINQ to SQL che permette di effettuare interrogazioni LINQ direttamente sulle tabelle del database.
Sono stati introdotti vari miglioramenti al linguaggio T-SQL. Un esempio è la nuova istruzione MERGE che permette ai programmatori di verificare l’esistenza dei dati prima di inserirli in tabella. Tramite questa istruzione non è più necessario creare join complessi per verificare l’esistenza dei dati al fine di effettuare un aggiornamento degli stessi o un nuovo inserimento.
A livello di tipi di dati sono stati separati i tipi date e time con l’introduzione di due nuovi tipi di dati e sono stati introdotti due nuovi tipi di dati spaziali: geography e geometry. Quest’ultimi consentono di memorizzare direttamente su database informazioni spaziali.
Un altro nuovo tipo di dati è il filestream, introdotto per risolvere il problema della memorizzazione e dell’utilizzo di oggetti binari di dimensioni consistenti, come documenti e file multimediali. In passato infatti il metodo utilizzato era quello di memorizzare i file esternamente al database e mantenere nel database un puntatore ad essi. In questo modo però quando i file venivano spostati era necessario aggiornare anche il puntatore relativo. Con il nuovo tipo filestream i file possono ancora essere memorizzati all’esterno del database ma essi vengono considerati parte dello stesso.
Chiaramente in questa introduzione ci siamo soffermati soltanto su alcune novità e nel corso della presente guida verranno esaminate più in dettaglio le caratteristiche salienti di SQL Server 2008.
Installazione
Vediamo adesso di analizzare a grandi linee i passaggi necessari per portare a termine l’installazione di SQL Server 2008.
Per prima cosa occorre assicurarsi di essersi autenticati sulla macchina su cui di sta operando con un’utenza che gode dei privilegi di amministratore, poichè durante l’installazione verranno creati diversi file e cartelle.
All’inizio dell’installazione viene richiesta l’installazione del .NET Framework 3.5 (se non precedentemente installato sulla macchina) che SQL Server 2008 utilizza per vari scopi e che permette ai programmatori di scrivere codice in uno qualunque dei linguaggio .NET e utilizzare tale codice per interagire con SQL Server.
La prima finestra del wizard di installazione è la SQL Server Installation Center
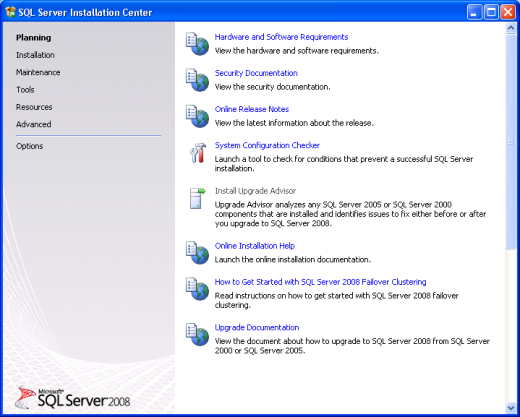
Questa schermata consente di gestire diversi aspetti di SQL Server ma per gli scopi della presente lezione ci soffermeremo sul processo di installazione. Clicchiamo dunque sul link Installation a sinistra e selezioniamo nella finestra successiva l’opzione New SQL Server stand-alone installation

Viene effettuata una breve scansione del sistema prima della richiesta di inserire il codice prodotto e di accettare la licenza d’uso.
A questo punto viene proposta la finestra Feature Selection in cui è necessario selezionare i componenti da installare
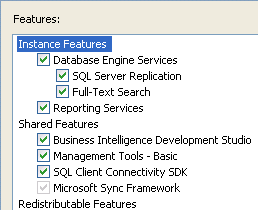
Si può scegliere di installare tutti gli strumenti disponibili oppure di selezionare esclusivamente quelli che si conosce in anticipo che verranno utilizzati e proseguire nel processo di installazione (sarà comunque possibile installare successivamente gli altri).
Una cosa importante da sottolineare è che è possibile installare più volte SQL Server su una macchina e ciò è molto utile quando si dispone di un server abbastanza potente che dispone di risorse sufficienti a supportare due o tre diverse applicazioni in esecuzione che richiedono di avere ognuna i propri database SQL.
Ogni installazione è denominata istanza e ciascuna di esse deve avere un nome univoco. Spesso ad esempio nelle grandi aziende si decide di creare un’istanza di SQL Server per lo sviluppo delle applicazioni e un’altra per il testing.
Nel nostro caso non abbiamo la necessità di installare più istanze e quindi selezioniamo l’opzione Default instance nella finestra Instance Configuration
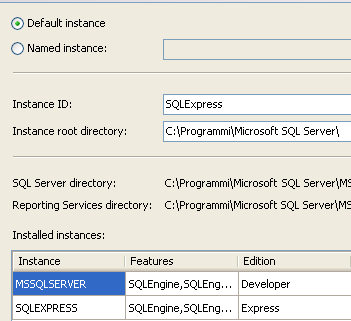
Proseguendo nell’installazione giungiamo alla sezione Database Engine Configuration in cui dobbiamo scegliere la modalità di autenticazione (Authentication Mode)
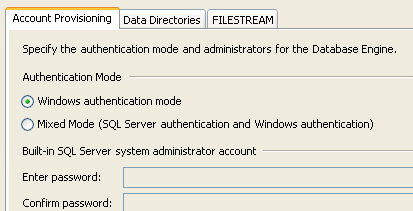
E’ possibile scegliere tra due opzioni di autenticazione: Windows authentication mode e Mixed mode. La prima determina l’utilizzo dell’autenticazione di Windows per la gestione dei login a SQL Server (ed è quella che utilizzeremo nel presente esempio); la seconda permette di utilizzare sia l’autenticazione di Windows sia quella di SQL Server. Sempre nella stessa schermata è necessario definire un account di amministrazione, da utilizzare in caso di emergenze.
Potete notare come nella finestra Database Engine Configuration siano presenti tre tab in alto. Il primo è quello relativo alle impostazioni di autenticazione (Account Provisioning) che abbiamo appena visto. Clicchiamo sul tab Data Directories tramite cui è possibile impostare i percorsi in cui SQL Server memorizza tutti i sui dati (possiamo lasciare i percorsi proposti)
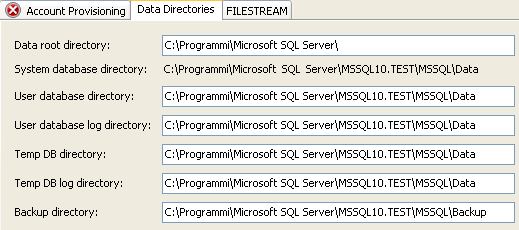
Lasciamo le impostazioni di default in questa e nelle schermate successive e proseguiamo fino alla fine della procedura di installazione. A questo punto ci verrà presentata una finestra di riepilogo delle scelte fatte e non ci resta che cliccare su Install.
SQL Server Management Studio
Dopo aver installato correttamente SQL Server 2008 è il momento di iniziare ad esplorare le aree che rendono questo prodotto facile da utilizzare e molto efficace.
Una componente findamentale di SQL Server è SQL Server Management Studio (SSMS), un’interfaccia utente da utilizzare per sviluppare ed effettuare la manutenzione dei nostri database. Si tratta di uno strumento intuitivo e facile da utilizzare che permette di lavorare in modo veloce e produttivo.
SQL Server consiste in un processo di Windows separato, pertanto se aprite il Task Manager e date un occhiata ai processi attivi troverete, tra gli altri, sqlservr.exe. Tale processo viene eseguito come servizio, monitorato da Windows stesso, e ad esso vengono riservate le opportune quantità di memoria e capacità di elaborazione del processore. Chiaramente in base al carico sul server SQL Server modifica le sue richieste in funzione delle risorse disponibili.
Siccome SQL Server viene eseguito come un servizio esso non ha interfacce collegate per l’interazione con gli utenti e per tale motivo è necessario uno strumento separato che permetta di comunicare comandi e funzioni da un utente al servizio di SQL Server, il quale poi eseguirà le richieste sul sottostante database. Tale strumento, come avrete intuito, è proprio SSMS e per tale motivo andiamo ad analizzarlo più in dettaglio.
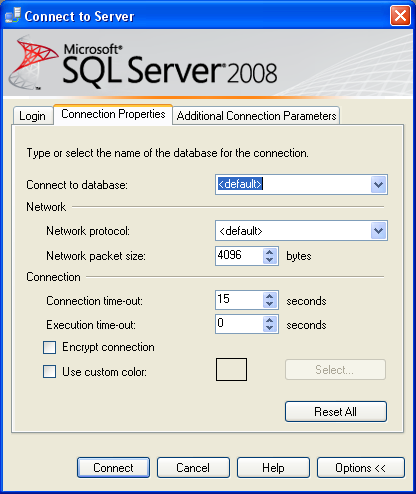
Per avviare SSMS dal menù Start selezionate la cartella di installazione di SQL Server 2008 e cliccate su SQL Server Management Studio. Viene proposta la finestra Connect to Server (e se non viene proposta automaticamente cliccate dal menù File sull’opzione Connect Object Explorer)

In tale finestra occorre specificare: il tipo di server (lasciate il valore Database Engine); il nome del server (espandete il menù a tendina e cliccando sull’opzione Browse for more dovrebbe comparire il nome della macchina su cui avete installato SQL Server, selezionate questa oppure uno degli altri server eventualmente disponibili); il tipo di autenticazione, che dipende dall’opzione scelta in fase di installazione (se si è scelto di installare con l’opzione Windows Authentication questa sarà l’unica opzione disponibile, altrimenti sarà possibile selezionare anche il tipo SQL Server Authentication inserendo le opportune informazioni di login).
Cliccando sul tasto Options è inoltre possibile andare ad impostare altre proprietà della connessione, tra cui anche quella per scegliere se criptare la connessione (Encrypt connection)
Dopo avere fatto le opportune scelte clicchiamo su Connect ed entriamo in SSMS. Chi ha familiarità con Visual Studio .NET troverà un layout grafico molto simile ad esso
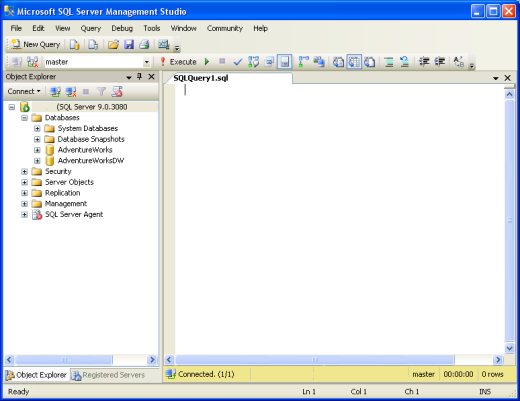
Nel mio caso io mi sono connesso all’istanza di SQL Server che gira sul mio computer locale, chiaramente ognuno di voi si connetterà alla propria. Nella finestra di sinistra in basso potete vedere due opzioni: Object Explorer e Registered Servers. Cliccate sulla seconda e andiamo ad analizzarne le funzionalità.
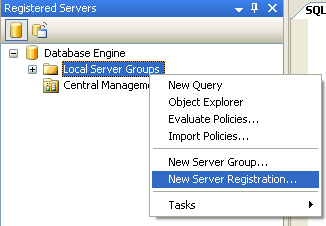
L’area Registered Servers mostra tutti i server SQL Server che vengono registrati nel SSMS. All’inizio chiaramente vedrete solo il server che avete appena registrato. Per registrare un nuovo server basta cliccare con il tasto destro del mouse sul nodo Local Server Groups e scegliere l’opzione New Server Registration
La finestra di registrazione di un nuovo server è molto simile a quella di connessione che abbiamo visto all’inizio, basta inserire i dati correttamente e cliccare su Save. L’unica differenza è la presenza della sezione Registered Server, tramite cui è possibile dare un nome diverso ai server registrati.
Passiamo ora alla sezione Object Explorer
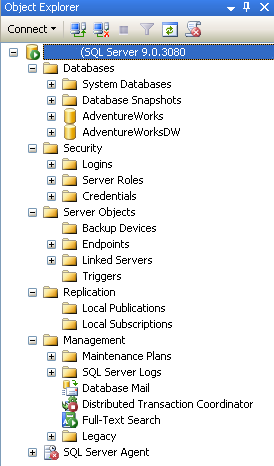
Come potete vedere sono presenti diversi nodi:
- Databases – Contiene i database sia di sistema che di utente ai quale si è connessi
- Security – Contiene la lista dei login degli utenti che possono connettersi a SQL Server
- Server Objects – Contiene oggetti come periferiche di backup e fornisce la lista dei linked server (server remoti connessi al nostro)
- Replication – Mostra i dettagli relativi alla riproduzione dei dati dal database sul server ad un altro database sullo stesso server o su un altro
- Management – Permette di gestire i piani di manutenzione (maintenance plans), di gestire le policy, di gestire i log e i messaggi di errore
- SQL Server Agent – Permette di pianificare ed eseguire attività specifiche in determinati momenti, riportando i dettagli sia in caso di successo che di fallimento delle stesse
Chiaramente in questa lezione diamo solo un accenno a queste aree e molte di esse verranno approfondite nel corso della guida.
Osservando la barra dei menù di SQL Server 2008 un menù interessante da approfondire è il View, che determina la visualizzazione di diverse aree di SSMS
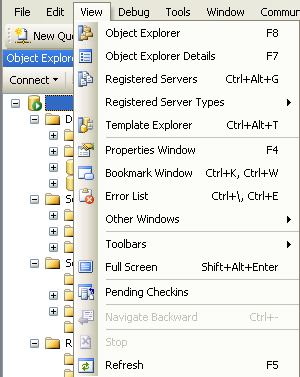
In tale menù la prima e la terza voce sono relative alle due aree che abbiamo visto prima, mentre cliccando sulla seconda viene proposta una pagina di riepilogo relativa al nodo selezionato nella finestra Object Explorer.
La maggior parte delle altre opzioni determinano la visualizzazione di finestra specifiche:
- Template Explorer – Contenente esempi di codice T-SQL
- Property Windows – Mostra le proprietà di un oggetto
- Error List – Mostra gli errori riscontrati nel codice presente nell’editor
- Toolbars – Permette di impostare diverse barre degli strumenti
Vedremo in dettaglio il funzionamento di queste e di altre aree nel prosieguo della guida.
Elementi di un database e database di sistema
La progettazione di un database non è semplice e richiede molta attenzione. In questa lezione cercheremo di analizzare le procedure relative a tale area che hanno come obiettivi soprattutto quello di rendere più efficiente la ricerca delle informazioni e quello di ridurre le duplicazioni delle stesse.
Un database è un contenitore di oggetti che memorizzano dati e permettono di effettuare ricerche su di essi in modo sicuro. Un database di SQL Server 2008 tipicamente contiene i seguenti oggetti:
- Tabelle
- Colonne e righe all’interno delle tabelle
- Procedure (stored procedure)
- Indici
- Viste
- Funzioni
Vediamoli nel dettaglio:
Tabelle
Le tabelle sono gli oggetti che contengono i dati di un database. Le tabelle definite dagli utenti sono dette user tables. Esistono anche le tabelle di sistema (system tables), che contengono molte utili informazioni, e le tabelle tempranee (temporary tables).
Colonne e righe
Le colonne provvedono alla definizione di ogni singolo elemento di informazione all’interno della definizione di una tabella. Esse sono simili alle colonne di un foglio Excel ma a differenza di quest’ultime, in cui ciascuna cella può contenere un tipo differente di dati, una colonna all’interno di una tabella di SQL Server è limitata da un solo tipo di dati e dalla quantità di informazioni che essa può contenere. Una riga (o record) è semplicemente costituita da una cella per ogni colonna presente nella tabella e rappresenta una singola unità di informazione.
Procedure
Quando è necessario manipolare grandi quantità di dati o eseguire ripetutamente sugli stessi alcune operazioni è conveniente memorizzare il codice di tali attività nelle cosiddette stored procedure (SP). Una SP contiene una o più istruzioni T-SQL, che vengono compilate e rese pronte da utilizzare quando richiesto. Tali procedure sono permanentemente memorizzate nel database e pronte per l’uso in qualsiasi momento.
Indici
Gli indici possono essere visti come liste predefinite di informazioni che servono al database per sapere come i dati sono fisicamente memorizzati e ordinati, al fine di rendere le ricerche più veloci ed efficienti. Un indice consiste di una o più colonne della tabella per la quale viene definito.
Viste
Le viste sono una sorta di tabelle virtuali che possono contenere informazioni derivanti da diverse tabelle (opportunamente legate tra di loro).
Funzioni
Una funzione è simile ad una stored procedure ma essa opera su una riga alla volta dell’insieme di righe che si trova ad elaborare. Solitamente si utilizza una stored procedure per attività che devono restituire un output e una funzione se si desidera conoscere i dettagli di ciascuna transazione di una determinata attività.
Durante l’installazione di SQL Server vengono installati anche alcuni database predefiniti, quelli di sistema (master, tempdb, model e msdb) e due database di esempio che contengono dati relativi ad una compagnia che produce biciclette (AdventureWorks e AdventureWorksDW).
Il database master è il cuore di SQL Server e nel caso in cui si danneggiasse probabilmente SQL Server non funzionerebbe più correttamente. Esso contiene diverse informazioni fondamentali: tutti i login ed i ruoli relativi agli utenti; tutte le impostazioni di sistema (come ad esempio il linguaggio di default); i nomi e le informazioni relative a tutti i database all’interno del server; la posizione dei database; le modalità di utilizzo della cache; i linguaggi di disponibili; i messaggi d’errore di sistema; ecc.
Il database tempdb è un database temporaneo la cui durata corrisponde alla durata di una sessione di SQL Server. Esso viene creato all’avvio di SQL Server e viene eliminato quando esso viene terminato. Un utilizzo molto comune di tale database è quello di memorizzare in esso i dati derivanti da un’interrogazione particolare per riutilizzarli in un secondo momento (tramite le tabelle temporanee).
Solitamente quando si crea un nuovo database si desidera che esso abbia un insieme di impostazioni predefinite e tali informazioni possono essere inserite e gestite tramite il database model, che rappresenta una sorta di modello per gli altri database.
Il database msdb è un altro elemento fondamentale di SQL Server e fornisce le informazioni necessarie all’esecuzione automatica di attività (job) definite tramite il SQL Server Agent. Quest’ultimo è un servizio di Windows che esegue tutti i job schedulati. Altri processi molto importanti che utilizzano in database msdb sono quelli di backup e restore.
Linee guida per la progettazione di un database
Quando ci si trova a dover progettare un database è necessario prendere alcune decisioni fondamentali come:
- Definire la tipologia del database: transazionale o analitico
- Definire il tipo di informazioni che esso dovrà gestire
- Definire i componenti del database (tabelle, relazioni, chiavi, ecc.)
Il primo passo è quello di stabilire se il nostro sistema sarà di tipo OLTP (Online Transaction Processing) o di tipo OLAP (Online Analytical Processing). Vediamo di capire la differenza tra questi due tipi di sistema.
OLTP
Un sistema OLTP permette di effettuare aggiornamenti dei dati istantaneamente e tipicamente si interfaccia con applicazioni utente che operano direttamente sui dati, permettendo agli utenti di rendere definitive tutte le modifiche che essi apportano. I sistemi OLTP richiedono diversi accorgimenti per assicurare prestazioni, affidabilità ed integrità dei dati e per tale motivo non è importante soltanto la progettazione del database, ma anche l’individuazione della locazione fisica dei dati. Molti di questi sistemi sono utilizzati continuativamente e quindi la grande frequenza di modifiche ai dati richiede un’attenta pianificazione ed esecuzione dell’attività di backup. Inoltre poichè la velocità delle operazioni è un obiettivo fondamentale in tali sistemi, tipicamente in essi è presente un numero di indici molto più grande che nei sistemi OLAP.
OLAP
A differenza dei sistemi OLTP un sistema OLAP è progettato in base al requisito che i dati presenti in esso vengano aggiornati non molto frequentemente. Tali aggiornamenti possono essere pianificati per essere eseguiti quando stabilito dall’amministratore del sistema: di notte, ogni settimana, ogni mese e così via. Come suggerisce il termine analytical, questi sistemi sono utilizzati per effettuare analisi sui dati esistenti e non per aggiornare i dati stessi, quindi non è necessario effettuare frequenti operazioni di backup. In essi inoltre sono presenti molti meno indici rispetto ai sistemi OLTP. I sistemi OLAP sono anche conosciuti con il nome di data warehouse (letteralmente deposito di dati), anche se quest’ultimi sono solo una parte di un sistema OLAP.
Una delle prime cose da fare quando si progetta un database è stabilire che tipo di informazioni verranno gestite dallo stesso. Individuate tali informazioni si passa alla definizione delle tabelle relative (vedremo prossimamente come effettuare tale operazione).
Nella prima fase di progettazione di un database le tabelle sono essenzialmente entità separate non correlate tra loro. Tipicamente esse hanno alcuni nomi di colonne corrispondenti (si pensi ad una tabella AnagraficaDipendenti con un IdDipendente e una tabella PresenzeDipendenti che contiene ovviamente anche la colonna IdDipendente) ma non c’è niente che le colleghi tra loro.
Per legare tra loro tali tabelle è necessario definire le cosiddette chiavi e relazioni, fondamentali per evitare che modifiche ad una determinata tabella causino la non validità dei dati contenuti in un’altra tabella e quindi danneggino la cosiddetta integrità dei dati.
Una chiave è un modo per identificare univocamente una riga in una tabella di un database e le chiavi sono molto utili per la creazione delle relazioni tra tabelle. La chiave può essere definita su una sola colonna o su più colonne allo stesso tempo e può essere di tre tipi: primaria, esterna (o di integrità referenziale) e alternativa.
La chiave primaria è quella più importante. Le colonne che formano la chiave primaria devono contenere valori univoci, ovvero ciascun valore della chiave primaria deve restituire un solo record della tabella. Chiaramente tale chiave non può essere definita su colonne che ammettono valori NULL e può essere utilizzata per collegare i dati di tabelle diverse (tramite operazioni di JOIN).
La chiave esterna viene invece tipicamente definita tra un insieme di colonne di una tabella figlia e la chiave primaria di una tabella padre (master table), in modo che ad ogni riga della tabella padre corrispondano zero o più righe della tabella figlia.
Per esempio tornando alle tabelle citate in precedenza, AnagraficaDipendenti e PresenzeDipendenti, è possibile creare una relazione tra di esse tramite la colonna IdDipendente, che è la chiave primaria della tabella di anagrafica.
Come detto in precedenza non è possibile definire su una tabella più di una chiave primaria, tuttavia è possibile definire un altro tipo di chiave molto simile alla primaria, la chiave alternativa. In pratica non ci sono differenze logiche tra i due tipi di chiave e la chiave alternativa deve contenere valori univoci.
Passiamo adesso ad esaminare i diversi tipi di relazioni. Come accennato in precedenza, una relazione è un legame logico tra due tabelle. Quando definiamo una relazione logica informiamo SQL Server che stiamo legando la chiave primaria di una tabella alla chiave esterna di un’altra, sono quindi necessarie due chiavi.
Una relazione può essere utilizzata per assicurare l’integrità dei dati. Se ad esempio due tabelle sono legate da una relazione non è logicamente corretto eliminare una riga della tabella padre senza eliminare le corrispondenti righe della tabella figlia. In caso contrario si verrebbe a creare la situazione in cui la tabella figlia contiene righe orfane, che non corrispondono ad alcuna riga della tabella padre. Ciò vale anche per l’inserimento di nuove righe: non deve essere possibile inserire righe in una tabella figlia senza aver prima inserito la corrispondente riga nella tabella padre.
Le relazioni possono essere di tre tipi:
- Uno a uno
- Uno a molti
- Molti a molti
Relazione uno a uno
Questo tipo di relazione non è molto comune all’interno di un database perchè tipicamente non esiste alcun motivo per cui un record di una tabella debba corrispondere ad un solo record di un’altra tabella (si potrebbe creare un’unica tabella contenente le colonne delle due tabelle di origine). L’unico scenario in cui questo tipo di relazione trova giustificazione è quello in cui si desidera suddividere una tabella di grandi dimensioni in tabelle più piccole (soprattutto per motivi prestazionali) e quindi ha senso definire un vincolo di tipo uno a uno tra tutte le tabelle derivate.
Relazione uno a molti
E’ il tipo di relazione più diffuso. In una relazione di questo tipo una riga di una tabella padre è logicamente collegata a zero, una o più righe di una tabella figlia. Ad esempio un record della tabella AnagraficaDipendenti può essere logicamente legato a n record della tabella presenze dipendenti, ognuno dei quali riporta i dati delle presenze del dipendente per ogni giorno di lavoro.
Relazione molti a molti
In questo tipo di relazione zero, una o più righe di una tabella padre sono collegate a zero o più righe di una tabella figlia.
Un altro concetto molto importante nella progettazione di un database è quello di normalizzazione. Con questo termine viene indicata la pratica di ridurre la ridondanza dei dati all’interno delle tabelle. Quest’ operazione viene spesso effettuata suddividendo i dati su più tabelle in modo gerarchico e favorisce prestazioni migliori delle query, rendendo più efficiente il database.
Sicurezza
La sicurezza di un database è un elemento fondamentale quanto la progettazione, la creazione e le prestazioni dello stesso. Se nel nostro database non vengono assicurate le opportune misure di sicurezza chiunque può accedere ai dati e modificarli a proprio piacimento a danno del proprietario degli stessi.
La sicurezza in SQL Server può essere assicurata in diversi modi:
- Attraverso l’autenticazione di Windows
- Restringendo l’accesso degli utenti ai dati tramite viste
- Creando utenze, login e ruoli che abbiano espliciti livelli di accesso
- Applicando tecniche di crittografia a database, log e file
Nelle lezioni precedenti abbiamo già visto la differenza tra autenticazione di Windows e autenticazione di SQL Server quindi nella presente lezione andremo oltre soffermandoci su: Login, Ruoli e Schemi.
Login
L’unico modo di connettersi a SQL Server è tramite credenziali di login. Quando un database viene creato inizialmente soltanto il proprietario dello stesso possiede i diritti per effettuare qualsiasi operazione su di esso. E’ una pratica comune quella di creare un gruppo di Windows e porre gli account di Windows in tale gruppo per poi aggiungerlo a SQL Server.
Per creare una nuova login basta cliccare con il tasto destro del mouse sul nodo Logins nella finestra Object Explorer e scegliere l’opzione New Login

Si aprirà la seguente finestra
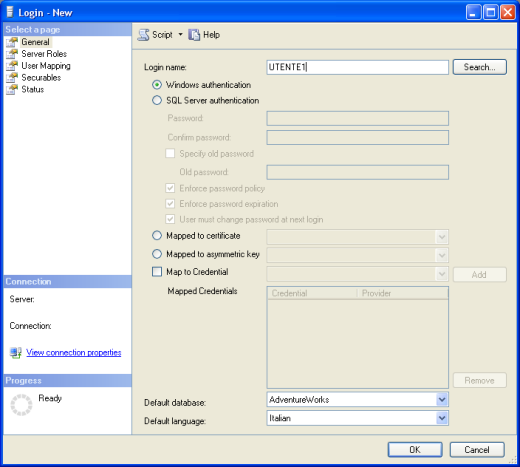
in cui occorre inserire il nome utente (login name), scegliere il tipo di autenticazione e, se lo si desidera, selezionare il database ed il linguaggio di default. Cliccando sul tasto Search in alto a destra si aprirà una finestra che permette di cercare utenze o gruppi di Windows e quindi impostare le credenziali di login per essi.
A questo punto occorre selezionare i database ai quali l’utente che si sta creando potrà accedere e per fare questo clicchiamo sulla sinistra della finestra precedente sulla voce Users Mapping, si aprirà la seguente pagina
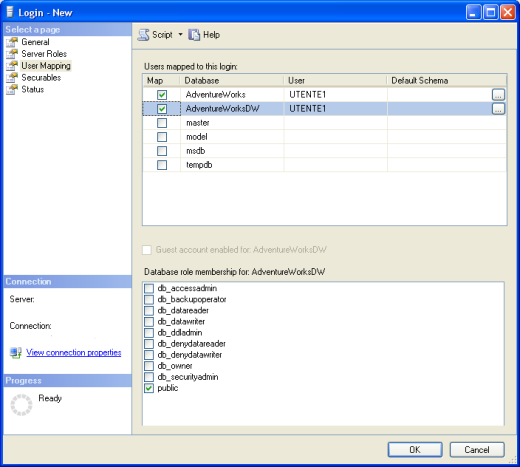
in cui come potete notare ho selezionato per l’utente UTENZA1 i database AdventureWorks e AdventureWorksDW.
Ruoli
A questo punto abbiamo creato un’utenza in grado di collegarsi con il server su cui risiedono i database. Il prossimo passo è quello di creare l’utenza per il database e per fare ciò dobbiamo prima parlare dei ruoli.
All’interno di SQL Server esistono tre differenti tipi di ruoli: ruoli a livello server, ruoli a livello database e ruoli a livello applicazione.
I ruoli a livello server sono predefiniti e consentono di autorizzare certe operazioni e negarne altre. Un amministratore di sistema può assegnare tali ruoli a ciascun utente del server e per vedere quali sono basta espandere il nodo Server Roles, che si trova sotto il nodo Logins
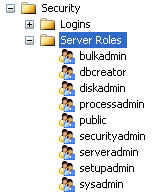
Ciascuno di questi ruoli permette di effettuare determinate operazioni e il ruolo sysadmin è quello che permette di effettuare qualsiasi operazione. Per aggiungere un’utenza ad un determinato ruolo basta cliccare con il tasto destro del mouse sul ruolo corrispondente e scegliere l’opzione Properties. Si aprirà una finestra in cui è possibile aggiungere le utenze desiderate.
Nel mio caso scelgo di assegnare ad UTENTE1 il ruolo sysadmin
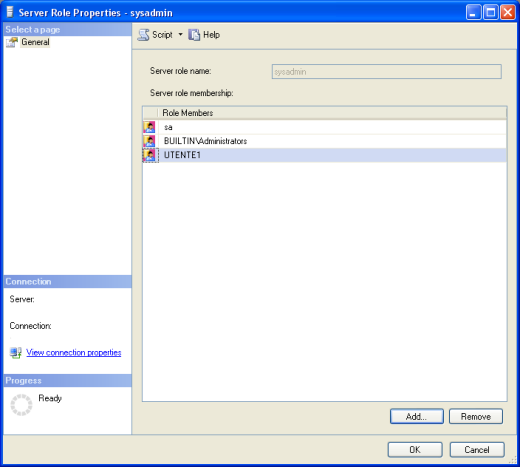
I ruoli a livello di database invece riguardano le azioni che è possibile effettuare sui database stessi. Se andate a riguardare l’immagine della procedura di creazione in cui abbiamo selezionato i database a cui può accedere UTENTE1 noterete in basso l’elenco dei ruoli a livello di database che è possibile impostare. Analogamente a sysadmin a livello di server il ruolo che gode di tutti i privilegi è db_owner.
Generalmente i database vengono creati per interagire con applicazioni perché non tutti i database interagiscono soltanto con un’applicazione. Un ruolo a livello di applicazione non coinvolge utenti ma viene utilizzato quando si desidera stabilire cosa un’applicazione può fare e cosa non può fare all’interno di un database.
Per creare un nuovo ruolo di questo tipo (ma anche a livello di database) basta espandere nella finestra Object Explorer il nodo Roles che si trova all’interno del nodo Security del database in oggetto e cliccare con il tasto destro su Application Roles, selezionando New Application Role. Si aprirà la seguente finestra

tramite cui impostare le opzioni desiderate.
Schemi
Uno schema è essenzialmente un modo di creare un gruppo ed inserire al suo interno oggetti che possono essere utilizzati per garantire o revocare permessi. Prima di SQL Server 2005 ogni oggetto di un database apparteneva ad un account utente, con evidenti problemi legati alla gestione di tali account. A partire da SQL Server 2005 gli oggetti appartengono invece a schemi e diversi utenti possono essere assegnati ad uno stesso schema.
Creare un database
Andiamo adesso a creare il nostro semplice database di prova. Per fare questo è possibile procedere in due modi: utilizzando l’interfaccia grafica di SQL Server Management Studio o scrivendo manualmente codice T-SQL.
Dati gli scopi della presente guida vedremo come procedere in modalità grafica, sebbene entrambi siano validi approcci da utilizzare in contesti differenti. Chiaramente per chi non abbia familiarità con le istruzioni T-SQL la scelta dell’interfaccia grafica di SSMS è obbligata.
Dopo aver avviato SSMS ed esserci collegati al nostro server espandiamo nella finestra Object Explorer il nodo Databases e visualizziamo i database predefiniti, tra cui AdventureWorks
Prima di creare un database dobbiamo avere chiare le seguenti informazioni:
- Il nome da assegnare al database
- La locazione del database
- Il nome dei file utilizzati per memorizzare le informazioni contenute nel database
Clicchiamo con il tasto destro del mouse sul nodo Databases e scegliamo l’opzione New Database
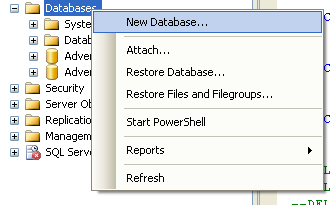
Si aprirà a questo punto la pagina General della finestra New Database
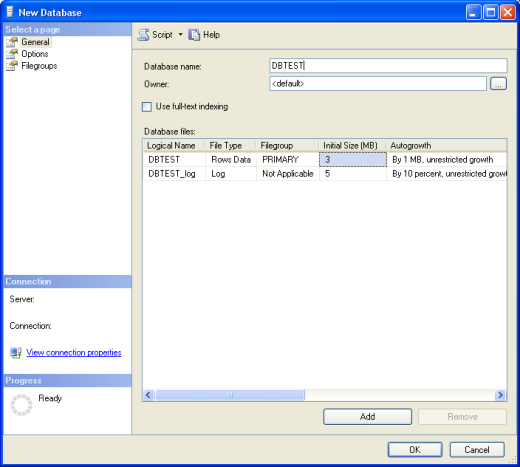
Inseriamo il nome del database (nel mio caso DBTEST) e i nomi dei file relativi al database e ignoriamo per il momento l’opzione Use full.text indexing. Sotto il nome del database potete vedere il campo owner (proprietario) il quale può essere valorizzato con qualsiasi login che abbia l’autorità per creare un database.
Il file di database e viene memorizzato sul disco con estensione .MDF (ad esempio DBTEST.mdf). MDF sta per Master Data File (file di dati principale) ed ogni database deve avere almeno un file di questo tipo. E’ anche possibile avere un Secondary Data File con estensione .NDF. Quest’ultimo tipo di file è utile se si desidera suddividere le tabelle e gli indici di un database su dischi diversi, chiaramente al prezzo di un peggioramento delle prestazioni del database. Per creare un file secondario basta cliccare sul tasto Add nella finestra New Database e nella nuova riga selezionare come valore della colonna Filegroup SECONDARY.
Altre tre colonne relative ai file sono Initial Size, Autogrowth e Path. La prima indica le dimensioni iniziali del database (quando cioè è vuoto); la seconda se SQL Server debba gestire automaticamente e come la crescita delle dimensioni del database; la terza serve ad impostare il percorso del file. Vi consiglio di lasciare in tutti questi campi i valori proposti.
A questo punto clicchiamo nella finestra a sinistra sulla pagina Options
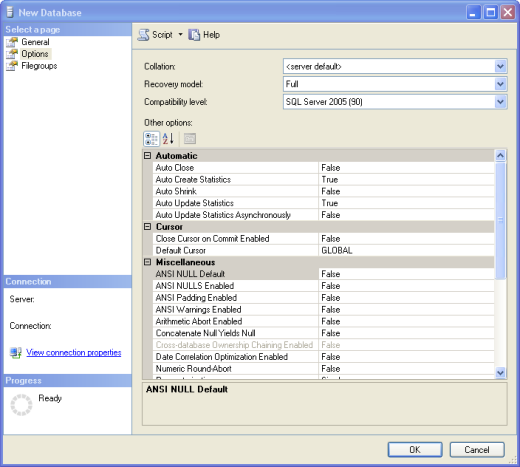
Il primo campo da valorizzare nella pagina Options è Collation. Le collation determinano non solo il set di caratteri in uso (dipendente dalla lingua) ma anche il comportamento nella ricerca e negli ordinamenti dei caratteri maiuscoli e minuscoli (ovvero se "A" deve essere uguale ad "a") ed alle lettere accentate (ad esempio se "è" deve essere uguale ad "é" e a "e"). Queste proprietà determinano se il set di caratteri è case sensitive e/o accent sensitive.
Proseguendo dobbiamo impostare il Recovery Model per il quale sono disponibili tre opzioni: Full, Bulk-Logged e Simple. Per un approfondimento su questa tematica vi invito a leggere un articolo molto interessante al seguente link.
La proprietà Compatibility Level permette di creare database compatibili con versioni precedenti di SQL Server, al prezzo di sacrificare qualche funzionalità.
Seguono tutta una serie di altre opzioni (Other options) delle quali mi soffermo sulle prime tre (vedremo alcune delle altre più avanti):
- Auto Close – Indica se il database deve essere chiuso quando l’ultimo utente si disconnette
- Auto Create Statistics – Determina se devono essere generate statistiche quando i dati vengono interrogati
- Auto Shrink – Permette di abilitare la gestione automatica delle dimensioni del database e dei transaction log
Finalmente possiamo cliccare su OK. Per prima cosa SQL Server verifica che il nome che abbiamo scelto non appartenga già ad un altro database (e in questo caso occorre ovviamente cambiarlo). Dopo aver validato il nome viene effettuato un controllo di sicurezza per verificare che l’utente che sta creando il database possiede i permessi per farlo. Il passo successivo è la creazione dei file dei dati sul disco e se tale operazione va a buon fine il database è pronto per l’uso.
Nell’ Object Explorer troveremo a questo punto anche il nostro database
Se vogliamo dare un’occhiata al codice T-SQL che SQL Server ha generato ed eseguito automaticamente basta cliccare con il tasto destro del mouse sul nostro database e selezionare l’opzione Script Database as -> CREATE to -> New Query Editor Window
si aprirà una finestra che conterrà il seguente codice (o qualcosa di molto simile)
USE [master]
GO
/****** Object: Database [DBTEST]
Script Date: 04/15/2010 17:58:49 ******/
CREATE DATABASE [DBTEST] ON PRIMARY
( NAME = N'DBTEST', FILENAME = N'C:ProgrammiMicrosoft
SQL ServerMSSQL.1MSSQLDATADBTEST.mdf' ,
SIZE = 3072KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'DBTEST_log', FILENAME = N'C:Programmi
Microsoft SQL ServerMSSQL.1MSSQLDATADBTEST_log.ldf' ,
SIZE = 5120KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
ALTER DATABASE [DBTEST] SET COMPATIBILITY_LEVEL = 90
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [DBTEST].[dbo].[sp_fulltext_database] @action = 'disable'
end
GO
ALTER DATABASE [DBTEST] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [DBTEST] SET ANSI_NULLS OFF
GO
ALTER DATABASE [DBTEST] SET ANSI_PADDING OFF
GO
ALTER DATABASE [DBTEST] SET ANSI_WARNINGS OFF
GO
ALTER DATABASE [DBTEST] SET ARITHABORT OFF
GO
ALTER DATABASE [DBTEST] SET AUTO_CLOSE OFF
GO
ALTER DATABASE [DBTEST] SET AUTO_CREATE_STATISTICS ON
GO
ALTER DATABASE [DBTEST] SET AUTO_SHRINK OFF
GO
ALTER DATABASE [DBTEST] SET AUTO_UPDATE_STATISTICS ON
GO
ALTER DATABASE [DBTEST] SET CURSOR_CLOSE_ON_COMMIT OFF
GO
ALTER DATABASE [DBTEST] SET CURSOR_DEFAULT GLOBAL
GO
ALTER DATABASE [DBTEST] SET CONCAT_NULL_YIELDS_NULL OFF
GO
ALTER DATABASE [DBTEST] SET NUMERIC_ROUNDABORT OFF
GO
ALTER DATABASE [DBTEST] SET QUOTED_IDENTIFIER OFF
GO
ALTER DATABASE [DBTEST] SET RECURSIVE_TRIGGERS OFF
GO
ALTER DATABASE [DBTEST] SET DISABLE_BROKER
GO
ALTER DATABASE [DBTEST] SET AUTO_UPDATE_STATISTICS_ASYNC OFF
GO
ALTER DATABASE [DBTEST] SET DATE_CORRELATION_OPTIMIZATION OFF
GO
ALTER DATABASE [DBTEST] SET TRUSTWORTHY OFF
GO
ALTER DATABASE [DBTEST] SET ALLOW_SNAPSHOT_ISOLATION OFF
GO
ALTER DATABASE [DBTEST] SET PARAMETERIZATION SIMPLE
GO
ALTER DATABASE [DBTEST] SET READ_COMMITTED_SNAPSHOT OFF
GO
ALTER DATABASE [DBTEST] SET READ_WRITE
GO
ALTER DATABASE [DBTEST] SET RECOVERY SIMPLE
GO
ALTER DATABASE [DBTEST] SET MULTI_USER
GO
ALTER DATABASE [DBTEST] SET PAGE_VERIFY CHECKSUM
GO
ALTER DATABASE [DBTEST] SET DB_CHAINING OFF
GOQuesto codice continene una seriedi queries corrispondenti alle opzioni che abbiamo impostato tramite l’interfaccia grafica di SSMS.
Componenti SQL e tipi di dati
Come già detto il linguaggio T-SQL è un linguaggio proprietario della Microsoft, tuttavia esso si basa sugli elementi fondamentali del linguaggio SQL e li integra con funzionalità avanzate. Tali elementi sono comuni a molti linguaggi di programmazione e sono:
- Costanti
- Commenti
- Identificatori
- Parole riservate
Costanti
Una costante può essere alfanumerica, esadecimale o numerica. Una stringa costante deve essere delimitata da due apici (ad es. ‘Prova’) e se all’interno della stringa si vuole includere un apice occorre digitarne due di seguito (ad es. ‘Quest”ultima’). Le costanti esadecimali devono invece cominciare con i caratteri ‘0x’. Una costante ha sempre un tipo dati e una lunghezza.
Commenti
Esistono due modi per specificare un commento in T-SQL. E’ possibile racchiudere un commento all’interno di una sequenza del tipo /* */ (ad es. /*Questo è un commento*/) ed in tal caso il commento si estenderà a tutte le linee incluse tra i due delimitatori. Oppure è possibile utilizzare i doppi trattini su una singola linea (ad es. –Questo è un commento). Quest’ultima soluzione deriva dagli standard del linguaggio SQL, mentre la prima è un’estensione di T-SQL.
Identificatori
Gli identificatori vengono invece utilizzati appunto per identificare gli oggetti di un database come tabelle, le stored procedures e gli indici. Essi sono costituiti da una stringa di massimo 128 caratteri.
Parole riservate
Ogni linguaggio di programmazione è caratterizzato da alcune parole riservate che ovviamente non possono essere utilizzate come identificatori e T-SQL non fa eccezione (ad es. SELECT, CREATE, ecc.).
Passiamo adesso ai tipi di dati. T-SQL utilizza differenti tipi di dati:
- Numerici
- Caratteri
- Temporali
- Misti
- Altri
Vediamoli nel dettaglio.
Numerici
Servono ovviamente a rappresentare numeri e di seguito sono elencate le caratteristiche di quelli principali:
- decimal[(p[, s])] e numeric[(p[, s])] – Decimal e Numeric sono sinonimi, possono avere valori compresi tra 10^38 – 1 e – 10^38 -1. La memoria che occupano per essere immagazzinati varia a seconda della precisione che utilizziamo per rappresentarli, da un minimo di 2 bytes a un massimo di 17 bytes; "p" è la precisione, che rappresenta il numero massimo di cifre decimali che possono essere memorizzate (da entrambe le parti della virgola). Il massimo della precisione è 28 cifre; "s" è la scala, che rappresenta il numero di massimo di cifre decimali dopo la virgola e deve essere minore od uguale alla precisione.
- int – Occupa 4 byte di memoria e memorizza i valori da -2147483648 a 2147483647
- smallint – Occupa 2 byte di memoria e memorizza i valori da -32768 a 32,767
- tinyint – Occupa 1 byte di memoria e memorizza i valori da 0 a 255
- float[(n)] – Contiene numeri a virgola mobile positivi e negativi, compresi tra 2.23E-308 e 1.79E308 per i valori positivi e tra -2.23E-308 e -1.79E308 per i valori negativi, occupa 8 bytes di memoria ed ha una precisione di 15 cifre
- real – Contiene numeri a virgola mobile positivi e negativi comprese tra 1.18E-38 e 3.40E38 per i valori positivi e tra -1.18E-38 e -3.40E38 per i valori negativi, occupa 4 bytes di memoria ed ha una precisione di 7 cifre
Caratteri
Esistono due tipi di dati a livello di caratteri. Essi possono essere infatti stringhe di singoli byte di caratteri o stringhe di caratteri Unicode:
- char[(n)] – Ha una lunghezza fissa e può contenere fino ad 8000 caratteri ANSI (cioè 8000 bytes)
- varchar[(n)] – Ha una lunghezza variabile e può contenere fino ad 8000 caratteri ANSI (cioè 8000 bytes)
- nchar[(n)] – Ha una lunghezza fissa e può contenere fino a 4000 caratteri UNICODE (cioè 8000 bytes, ricordiamo che per i caratteri UNICODE servono 2 bytes per memorizzare un carattere)
- nvarchar[(n)] – ha una lunghezza variabile e può contenere fino a 4000 caratteri UNICODE (cioè 8000 bytes, ricordiamo che per i caratteri UNICODE servono 2 bytes per memorizzare un carattere)
Temporali
Alcuni tipi di dati temporali sono:
- datetime – Ammette valori compresi dal 1 gennaio 1753 al 31 dicembre 9999 (precisione al trecentesimo di secondo), occupa uno spazio di 8 byte
- smalldatetime – Meno preciso del precedente (precisione al minuto), occupa uno spazio di 4 byte
- date – Occupa uno spazio di 3 byte per memorizzare solo date
- time – Occupa uno spazio da 3 a 5 byte per memorizzare solo orari
Misti
- bit – Tipicamente è usato per rappresentare i flag, vero/false o true/false o si/no, perché può accettare solo due valori 0 o 1. Occupa un bit ovviamente. Le colonne che hanno un tipo dati bit non possono avere valori nulli e non possono avere indici.
- timestamp – Occupa 8 bytes ed è un contatore incrementale per colonna assegnato automaticamente da SQL Server 7.
Altri
- money – Contiene valori monetari da -922337203685477.5808 a 922337203685477.5807 con una precisione al decimillesimo di unità monetaria, occupa 8 bytes di memoria
- smallmoney – Contiene valori monetari da – 214748.3648 a 214748.3647 con una precisione al decimillesimo di unità monetaria, occupa 4 bytes di memoria.
- binary[(n)] – Ha una lunghezza fissa e può contenere fino ad 8000 bytes di dati binari
- varbinary[(n)] – Ha una lunghezza variabile e può contenere fino ad 8000 bytes di dati binari
Esistono poi i cosiddetti Large Objects Data Types (LOBs) che possono raggiungere una dimensione massima di 2GB. Questi oggetti vengono tipicamente utilizzati per la memorizzazione di grandi quantità di testo o di file multimediali e sono: varchar(MAX), nvarchar(MAX), varbinary(MAX), TEXT, NTEXT, IMAGE.
Esistono anche altri tipi di dati e per approfondire la conoscenza delle caratteristiche di questi e di quelli che vi ho elencato vi consiglio di consultare la documentazione ufficiale T-SQL.
Valori NULL
NULL è un particolare valore che può essere assegnato ad una colonna. Questo valore è tipicamente utilizzato quando l’informazione relativa ad una cella di una colonna è sconosciuta o non applicabile. Ogni espressione aritmetica o booleana che coinvolge valori NULL restituisce un valore NULL. Nelle funzioni di aggregazione i valori NULL vengono eliminati.
Funzioni predefinite, operatori e variabili globali
Il linguaggio T-SQL contiene diverse funzioni predefinite che possono essere suddivise in due categorie: aggregate e scalari. Andiamo a vedere quelle più importanti.
Funzioni aggregate
Le funzioni aggregate (o funzioni di aggregazione) vengono applicate ad un insieme di dati appartenenti ad una colonna e restituiscono sempre un singolo valore. Quelle principali sono:
- AVG – Calcola la media aritmetica dei valori di una colonna (che chiaramente deve contenere valori numerici)
- MAX – Restituisce il valore massimo dei dati di una colonna (che può avere come tipi di dati numeri, stringhe e valori temporali)
- MIN – Restituisce il valore minimo dei dati di una colonna (che può avere come tipi di dati numeri, stringhe e valori temporali)
- SUM – Effettua la somma dei valori dei valori di una colonna (che chiaramente deve contenere valori numerici)
- COUNT – Calcola il numero di valori non nulli in una colonna. Se questa funzione viene utilizzata nella forma COUNT(*) restituisce il numero delle righe di una tabella
Funzioni Scalari
Le funzioni scalari operano su un valore o su una lista di valori e possono essere suddivise in:
- Funzioni numeriche
- Funzioni temporali
- Funzioni di gestione delle stringhe
- Funzioni di sistema
Le principali sono:
- Abs(espressione_numerica) – Valore assoluto
- Acos( espressione_numerica) – Arcoseno
- Ascii(character_espressione) – Converte un carattere nel suo codice ASCII
- Asin( espressione_numerica) – Arcoseno
- Atan( espressione_numerica) – Arcotangente
- Cast(espressione as tipo_di_dato) – Converte una espressione SQL in un determinato tipo di dato
- Char(espressione_intera) – Converte in ASCII il carattere corrispondente
- Convert(data_type [(length)], espressione [, style]) – Converte dati da un tipo ad un altro
- Cos(espressione_numerica) – Coseno
- Cot(espressione_numerica) – Cotangente
- Dateadd(datepart, number, date) – Aggiunge un numero alla parte della data (esempio 3 mesi)
- Datediff(datepart, startdate, enddate) – Calcola la differenza tra due date (in giorni, mesi o anni in base al parametro datepart)
- Datename(datepart, date) – Il nome della parte della data
- Datepart(datepart, date) – Il valore della parte della data
- Day(date) – Il giorno della data passata
- Exp(espressione_numerica) – Esponente
- Getdate( ) – Restituisce la data corrente
- Isdate(espressione) – Valuta se l’espressione è di tipo DATETIME
- Isnull(espressione, valore_di_sostituzione) – Se l’espressione è null la sostituisce con il secondo valore
- Isnumeric(espressione) – Valuta se l’espressione è di tipo NUMERIC
- Left(espressione, numero) – La parte di stringa a partire dal numero
- Len(string_espressione) – La lunghezza della stringa
- Log(espressione_numerica) – Logaritmo naturale
- Log10(espressione_numerica) – Logaritmo in base 10
- Lower(character_espressione) – Converte in minuscolo
- Ltrim(character_espressione) – Toglie gli spazi a sinistra
- Month(date) – Il mese della data inserita
- Nullif(espressione, espressione) – Restituisce null se espressioni sono equivalenti
Per operare su valori scalari sono necessari operatori scalari e il linguaggio T-SQL supporta diversi operatori di tipo numerico e booleano. Sono presenti operatori aritmetici di tipo unario e binario. Gli operatori unari sono + e -. Quelli binari sono +, -, *, / e %. Gli operatori booleani hanno due differenti notazioni a seconda che vangano applicati a stringhe o ad altri tipi di dati. Gli operatori AND, OR e NOT vengono applicati a tutti i tipi di dati (eccetto BIT).
Infine soffermiamoci sulle cosiddette variabili globali che possono essere utilizzate come se fossero costanti. Questo tipo di variabili sono precedute da una doppia chiocciola (@@) e alcune di queste sono:
- @@CONNECTIONS – Restituisce il numero di tentativi di login effettuati da quando il sistema è stato avviato
- @@ERROR – Restituisce informazioni sul valore ritornato dall’ultima istruzione eseguita
- @@LANGID – Restituisce l’identificatore del linguaggio utilizzato correntemente nel database
- @@ROWCOUNT – Restituisce in numero di righe coinvolte dall’ultima istruzione
- @@VERSION – Restituisce la versione corrente del DBMS
- @@SERVERNAME – Restituisce informazioni riguardanti il server
Definire e creare tabelle
A questo punto abbiamo creato il nostro database e conosciamo gli elementi di base del linguaggio T-SQL ma affinchè il database sia funzionale è necessario che esso contenga almeno una tabella. Tipicamente i database di grandi e medie organizzazioni contengono centinaia di tabelle.
La progettazione di una tabella è un’attività cruciale poichè presuppone la definizione del giusto numero di colonne, del relativo tipo di dati e delle eventuali relazioni con altre tabelle.
Una tabella è un contenitore di dati raggruppati in una o più colonne e può avere zero o più righe. La definizione delle colonne è una fase molto importante poichè ciascuna di esse conterrà un solo tipo di dati e quindi si deve essere assolutamente certi del tipo di dati da assegnare loro. Chiaramente è opportuno dare sia alle colonne che alla tabella un nome appropriato ai dati contenuti.
Andiamo adesso a creare la nostra prima tabella. Supponiamo di voler creare una tabella contenente i dati anagrafici dei dipendenti di un’azienda. Avviamo SQL Server Management Studio e colleghiamoci al nostro database (DBTEST).
Clicchiamo con il tasto destro del mouse sul nodo Tables e scegliamo l’opzione New Table
Si aprirà la finestra Table Designer
In questa schermata occorre definire tutti i dettagli delle colonne che conterrà la tabella. Per la nostra tabella di anagrafica dei dipendenti inseriamo le seguenti colonne
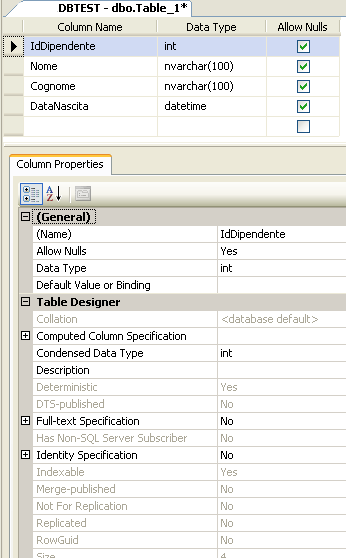
Come potete notare selezionando ciascuna colonna nella tab Column Properties compaiono tutte le proprietà della stessa. Quando si inseriscono i nomi delle colonne è buona norma evitare spazi, eventualmente utilizzate gli underscore (_).
Tra le proprietà di una colonna c’è Allow Nulls. Questa scelta determina se la colonna potrà contenere o meno valori NULL. Le colonne che verranno usate come chiavi o nelle relazioni (come vedremo successivamente) dovranno avere tale proprietà settata a false.
Adesso impostiamo la proprietà Is Identity a true per la colonna IdDipendente
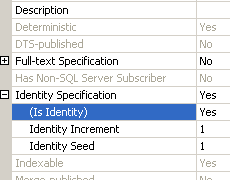
Questa opzione indica a SQL Server di generare automaticamente un progressivo numerico per ogni nuova riga che verrà inserita nella tabella.
Clicchiamo sul pulsante di salvataggio e si aprirà una finestrella in cui inserire il nome della tabella
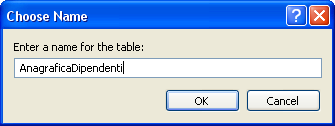
clicchiamo su ok ed espandendo nuovamente il nodo Tables del nostro database troveremo la tabella appena creata
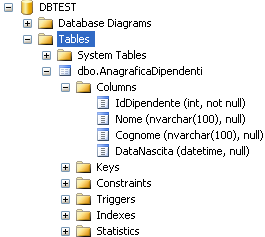
Chiaramente è sempre possibile cliccare con il tasto destro del mouse su ogni colonna e selezionare l’opzione Properties, utilizzando la relativa finestra per cambiare le proprietà che si desidera.
Clicchiamo invece con il tasto destro del mouse proprio sulla tabella e apriamo la finestra delle proprietà (Table Properties)
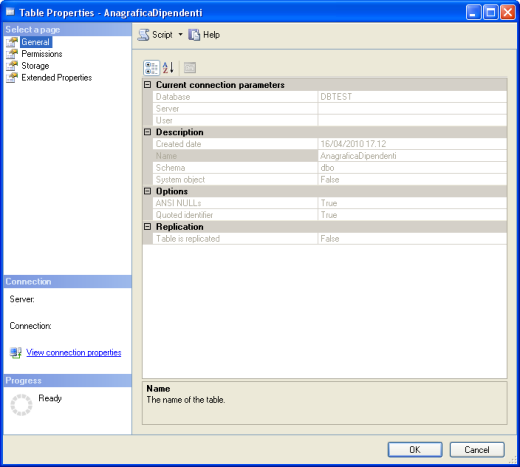
in essa è possibile consultare importanti informazioni.
Oltre all’opzione Properties il menù contestuale che viene proposto quando si clicca sulla tabella contiene molte utili opzioni
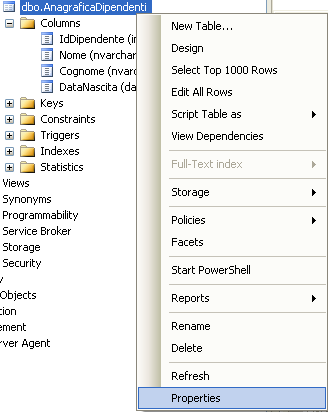
Tra queste, a parte quelle il cui funzionamento è abbastanza ovvio, mi preme evidenziarne alcune:
- Design – Permette di modificare la tabella accedendo alla finestra Table Designer che abbiamo visto nella fase di creazione
- View Dependencies – Fornisce una lista di ogni oggetto del database correlato alla tabella
- Policies – Permette di consultare o definire regole per la tabella
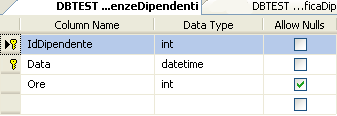
Per gli scopi della presente guida creiamo una seconda tabella denominata PresenzeDipendenti con i seguenti campi: IdDipendente (int), DataPresenza(datetime), Ore(int).
Chiavi e relazioni
Dopo la creazione di una tabella il passo successivo è quello di definire la sua chiave primaria, operazione molto semplice in SQL Server Management Studio.
Selezioniamo la tabella (nel nostro caso AnagraficaDipendenti) e clicchiamo con il tasto destro del mouse su di essa, scegliendo dal menù relativo l’opzione Design

In questo modo potremo accedere alla finestra di progettazione della tabella, nella quale clicchiamo con in tasto destro del mouse sulla colonna IdDipendente e scegliamo l’opzione Set Primary Key
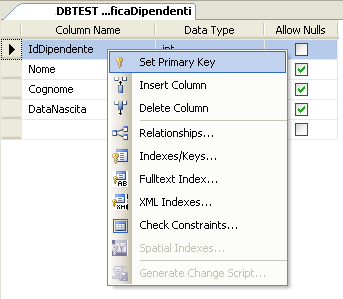
A questo punto sulla sinistra della colonna potete notare il simbolo della chiave
Clicchiamo infine sul pulsante di salvataggio nella barra degli strumenti.
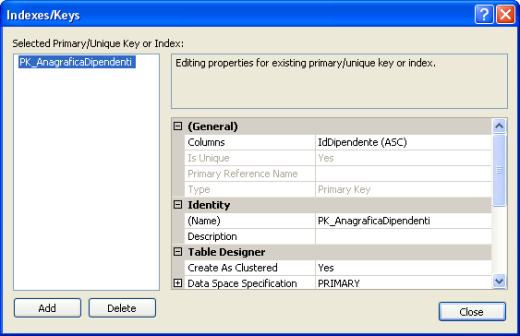
Per modificare la chiave primaria possiamo cliccare sul tasto Manage Indexes/Keys nella barra degli strumenti

accedendo alla finestra Indexes/Keys
Procedendo allo stesso modo impostiamo la chiave primaria della tabella PresenzeDipendenti sulle due colonne IdDipendente-Data
Passiamo adesso a definire una relazione tra le due tabelle. La relazione tra le tabelle AnagraficaDipendenti e PresenzeDipendenti è di tipo uno a molti perché ad ogni dipendente possono corrispondere n record della tabella PresenzeDipendenti.
Clicchiamo con il tasto destro del mouse sulla tabella PresenzeDipendenti, scegliamo l’opzione Design e nella barra degli strumenti clicchiamo sul tasto Relationship

Nella relativa finestra clicchiamo su Add per inserire una nuova relazione (possiamo lasciare il nome suggerito da SQL Server)
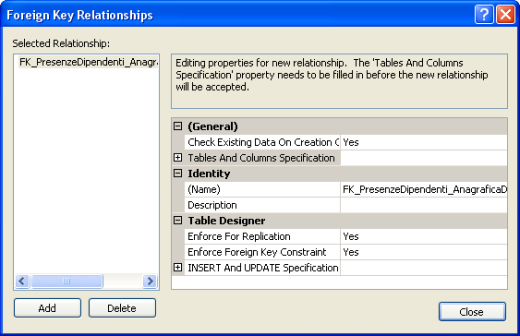
Espandiamo il nodo Tables And Columns Specification e clicchiamo sul tasto con i tre puntini (ellipsis button)

Si aprirà la finestra Tables and Columns, nella quale possiamo modificare il nome della relazione e selezionare la tabella padre della relazione (nel nostro caso AnagraficaDipendenti), mentre la tabella figlia ovviamente non è modificabile. Selezioniamo la colonna IdDipendente per entrambe le tabelle e clicchiamo su OK

Attenzione non è necessario che le colonne coinvolte nella relazione abbiano lo stesso nome, è sufficiente che abbiano lo stesso tipo di dati.
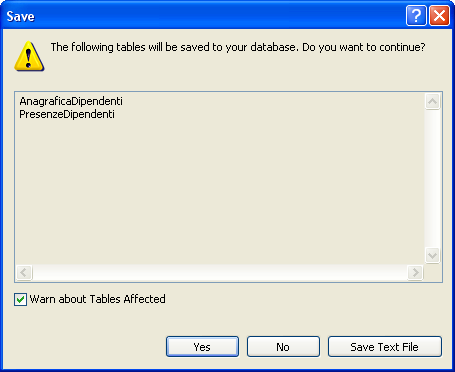
Tornando alla finestra di definizione delle relazioni lasciamo tutte le altre opzioni di default e chiudiamo la stessa. La chiusura della finestra non determina il salvataggio delle modifiche, occorre sempre cliccare sul tasto di salvataggio nella barra degli strumenti.
Prima di effettuare il salvataggio SQL Server ci mostrerà le tabelle coinvolte nell’operazione:
Indici
Dopo aver creato le tabelle del nostro database potremmo fermarci qui e cominciare a lavorare sui dati. Tuttavia questa non è la scelta migliore soprattutto quando ci si trova a dover lavorare con database reali di grandi dimensioni, con molte tabelle e grandi quantità dati.
Quando le tabelle contengono grandi quantità di informazioni la ricerca di un singolo record all’interno di esse potrebbe richiedere molto tempo, con un degrado delle prestazioni di tutto il database.
In questo scenario il database può essere paragonato ad un libro senza indice in cui vogliamo trovare una pagina specifica sfogliando le pagine una ad una. Come ben sappiamo i libri hanno invece sempre un indice e tramite esso la ricerca di una pagina specifica è un’operazione semplice e veloce. Una cosa simile è buona norma applicarla alle tabelle di SQL Server.
La definizione di una indice in SQL Server serve a migliorare le prestazioni. Infatti quando viene effettuata una ricerca su una tabella in cui è definito un indice la ricerca stessa non viene effettuata sui dati memorizzati nella tabella ma si focalizza su un sottoinsieme di dati corrispondenti all’indice della tabella stessa, rendendo l’operazione molto più veloce.
Un indice può essere creato su una singola colonna (indice semplice) o su più colonne (indice composto) e può essere di due tipi: clustered o nonclustered.
Indici clustered
Un indice clustered definisce l’ordine fisico dei dati di una tabella. Se abbiamo più di una colonna definita in un indice clustered i dati vengono ordinati in modo sequenziale in base a tali colonne. Può essere definito solo un indice clustered per tabella perché ovviamente sarebbe impossibile memorizzare i dati in più ordini contemporaneamente.
Quando vengono inseriti dati SQL Server inserisce i riferimenti agli stessi all’interno dell’indice e inserisce la riga nella posizione appropriata. Una buona norma è quella di non definire un indice su colonne che vengono aggiornate frequentemente poiché in questo caso SQL Server si troverà a dover continuamente modificare l’ordine fisico dei dati con un grosso dispendio di capacità di elaborazione della macchina.
Indici nonclustered
Diversamente da un indice clustered un indice nonclustered non memorizza direttamente una parte dei dati della tabella ma memorizza puntatori ai dati corrispondenti alle colonne in esso definite. Questo tipo di indici viene memorizzato in una struttura separata rispetto alla tabella.
Quando si effettua una ricerca sui dati memorizzati su una tabella sulla quale è definito un indice nonclustered SQL Server utilizza l’informazione definita nei puntatori dell’indice per individuare le righe che corrispondono ai criteri della ricerca.
Un indice può essere unico (unique) o non unico (nonunique). Un indice unico assicura che i valori contenuti nelle colonne definite nell’indice siano univoci all’interno della tabella. Un indice non unico invece permette di inserire nella tabella più righe con gli stessi valori per le colonne definite nello stesso. Per tale motivo gli indici unici sono comunemente utilizzati per supportare costanti come le chiavi primarie mentre quelli non unici vengono comunemente utilizzati per supportare la ricerca di dati tramite colonne che non costituiscono chiavi.
Chiaramente la definizione di indici richiede un’attenta analisi delle tabelle del database e della quantità stimata di dati che esse potranno contenere. Esistono delle norme dettate dal buon senso che è utile conoscere prima di definire un indice: un indice può contenere fino a 16 colonne ma in genere non dovrebbe contenerne più di quattro o cinque; la quantità totale di dati per le colonne contenute in un indice di una riga non può superare i 900 byte; non definire indici su colonne il cui contenuto viene aggiornato frequentemente; ecc. Molto spesso gli indici vengono definiti su colonne di una tabella che costituiscono una relazione con altre tabelle.
Ma vediamo adesso come si fa a definire un indice. Come ricorderete quando abbiamo creato la tabella AnagraficaDipendenti abbiamo impostato per la colonna IdDipendente la proprietà IsIdentity a true. Ciò significa che quando viene inserita una riga nella tabella in tale colonna viene inserito automaticamente un valore intero progressivo.
Supponiamo di volere creare adesso un indice clustered sulle colonne Nome e Cognome della stessa tabella. Clicchiamo con il tasto destro del mouse sulla tabella e scegliamo l’opzione Design che, come ormai ben sappiamo, determina l’apertura della finestra di progettazione. Clicchiamo sul tasto Manage Indexes e Keys e lavoriamo nuovamente sulla finestra Indexes/Keys.
Nella finestra ovviamente troveremo la chiave primaria che abbiamo definito in precedenza e clicchiamo sul tasto Add. Viene aggiunto di seguito alla chiave primaria un altro valore, quello dell’indice che stiamo andando a definire
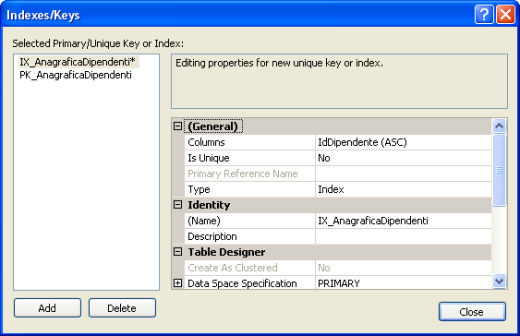
Nell’area delle proprietà dell’indice possiamo cambiare il suo nome o lasciare quello suggerito da SQL Server. Selezioniamo le colonne da inserire nell’indice (nel nostro caso Cognome e Nome) e impostiamo per la proprietà Is Unique il valore Yes (cioè non possono esserci più record con lo stesso nome e cognome)
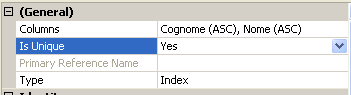
Infine clicchiamo su OK. Come potete vedere la creazione di un indice è un processo molto semplice utilizzando SQL Server.
Diagrammi
Quando si termina di costruire un database, con tutti gli elementi relativi (tabelle, indici e relazioni) si passa alla cosiddetta documentazione dello stesso e SQL Server ci viene in aiuto in questo contesto con il Database Diagram Tool, uno strumento molto utile.
Uno degli aspetti più noiosi nella creazione della documentazione di un database è quello di presentare le tabelle e le relative relazioni in un diagramma manualmente. Quando si ha a che fare con database di grandi dimensioni chiaramente disegnare un diagramma relativo manualmente è un compito gravoso.
Un diagramma standard deve permettere di visualizzare tabelle, colonne e relazioni. Altre utili informazioni da visualizzare sono le chiavi primarie di ciascuna tabella. Fortunatamente per noi il Database Diagram Tool di SQL Server Management Studio ci viene in soccorso nella creazione di diagrammi che presentino tali informazioni.
Questo tool tuttavia offre più della semplice possibilità di creare diagrammi, costituendo anche una sorta di interfaccia attraverso cui creare o modificare tabelle, relazioni, chiavi, indici, ecc. Ogni modifica che viene effettuata nel diagramma viene propagata al database.
Una cosa importante da sottolineare è che non è possibile inserire in un diagramma procedure, schemi, utenti, viste e in generale qualsiasi oggetto che non sia una tabella.
Andiamo adesso a creare il diagramma del nostro semplice database di esempio. Clicchiamo con il tasto destro del mouse sul nodo Database Diagrams nella finestra Object Explorer e scegliamo l’opzione Install Diagram Support
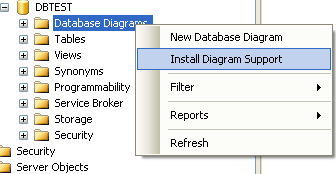
Comparirà una finestra di dialogo in cui ci viene chiesta la conferma per la creazione degli oggetti necessari,clicchiamo su Yes. Fatto questo clicchiamo nuovamente con il tasto destro del mouse sul nodo e scegliamo l’opzione New Database Diagram. La prima finestra che ci viene presentata è la finestra Add Table. In essa selezioniamo le tabelle del nostro database e clicchiamo su Add
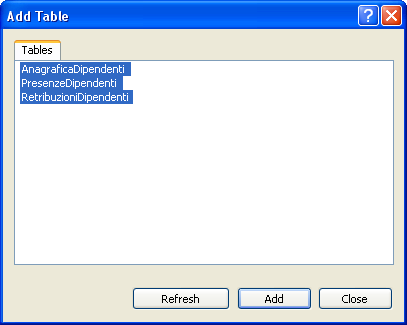
Dopo la chiusura della finestra Add Table e dopo aver inserito il nome del diagramma (nel nostro caso DiagrammaTest) nella successiva finestra di dialogo potremo vedere nella finestra principale di SQL Server Management Studio il nostro diagramma
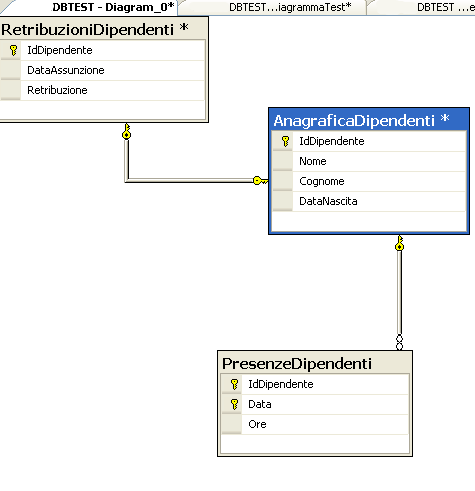
Diamo adesso un’occhiata alla barra degli strumenti relativa al diagramma e vediamone le funzionalità più interessanti

Il primo pulsante permette la creazione di una nuova tabella in modo del tutto simile a quello che abbiamo visto nella lezione sulla creazione delle tabelle ma con la differenza che occorre utilizzare la finestra delle proprietà per ciascuna colonna invece di avere le proprietà visibili in basso.
Il secondo permette di aggiungere al diagramma tabelle già esistenti ma che non sono state incluse in esso al momento della creazione
Il pulsante Add Related Tables che permette di inserire nel diagramma tutte le tabelle collegate a quella correntemente selezionata, ovvero fra le quali sono state definite relazioni

Mentre con il seguente pulsante si elimina una tabella dal diagramma

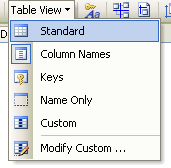
Ogni tabella visualizzata è caratterizzata da un layout predefinito. E’ possibile variarlo cliccando sul pulsante Table View e selezionando la vista desiderata
Il pulsante seguente permette invece di visualizzare opportune linee che rendono l’idea dei fogli su cui sarà suddivisa un’eventuale stampa del database

Agendo tramite questi strumenti è possibile qualsiasi tipo di diagramma di un database.
Lavorare con i dati
Il primo passaggio quando si comincia a lavorare con i dati è ovviamente quello di inserire record nelle tabelle del database. In SQL Server questa operazione si può effettuare o tramite istruzioni SQL nella finestra Query Editor o attraverso SQL Server Management Studio.
Chiaramente lo scopo della presente guida non è quello di approfondire gli aspetti del linguaggio T-SQL perché viene data per scontata una minima conoscenza del linguaggio SQL (che, ricordiamo, costituisce la base del linguaggio T-SQL) da parte di coloro che stanno leggendo la presente guida, tuttavia verranno presentati alcuni frammenti di codice che possono aiutare nella comprensione delle attività che è possibile effettuare sui dati.
Per inserire dati nella nostra tabella AnagraficaDipendenti nella finestra Object Explorer clicchiamo con il tasto destro del mouse su di essa e scegliamo nel menù contestuale l’opzione Script Table As – INSERT to – New Query Editor Window
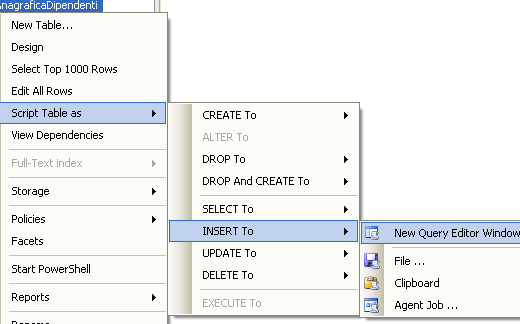
Viene generato il seguente codice T-SQL
INSERT INTO [DBTEST].[dbo].[AnagraficaDipendenti]
([Nome]
,[Cognome]
,[DataNascita])
VALUES
(< Nome, nvarchar(100),>
,< Cognome, nvarchar(100),>
,< DataNascita, datetime,>)
GOnel quale potete notare la mancanza della colonna IdDipendente che, come abbiamo detto, viene gestita automaticamente da SQL Server e per la quale quindi non è possibile inserire valori manualmente.
Modificando i dati dello script nel modo seguente
INSERT INTO [DBTEST].[dbo].[AnagraficaDipendenti]
([Nome]
,[Cognome]
,[DataNascita])
VALUES
('Carlo', 'Rossi', '05/05/1965')
GOpossiamo inserire il nostro primo record nella tabella premendo il pulsante Execute nella barra degli strumenti o il tasto F5 della tastiera, azioni che indicano a SQL Server di eseguire lo script.
Se lo script non contiene errori dovremmo vedere il seguente risultato

messaggio che indica il corretto inserimento della riga nella tabella. Eseguendo quindi la seguente query nel Query Editor
SELECT * FROM dbo.AnagraficaDipendentiil risultato sarà il seguente

In modo del tutto analogo sempre tramite il menù contestuale utilizzato per l’istruzione di insert è possibile generare automaticamente anche altri tipi di istruzione come quelle di update e di delete.
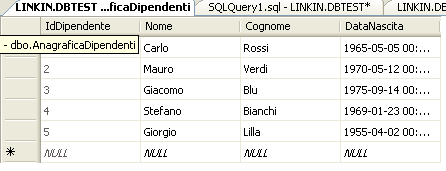
Vediamo adesso come operare sui dati in modo visuale tramite SQL Server Management Studio. Clicchiamo con il tasto destro del mouse sulla nostra tabella e scegliamo l’opzione Edit All Rows.
Nella finestra principale di SQL Server verrà visualizzata la seguente griglia (ho inserito altri record nella tabella prima di effettuare questa operazione)
Tramite essa possiamo modificare i dati esistenti, cancellarli o inserirne di nuovi. Chiaramente nel nostro contesto d’esempio è evidente come sia molto più comodo operare in questo modo, tuttavia se immaginiamo di operare su tabelle con centinaia di migliaia di righe pensare di andare a modificare manualmente ciascuna di esse è una pazzia e le istruzioni T-SQL risultano sicuramente l’opzione migliore.
Quando si opera sui dati in entrambi i modi ovviamente è necessario rispettare i tipi di dati delle colonne e tutte le opzioni impostate in fase di creazione delle tabelle (ad esempio occorre fare attenzione a non tentare di inserire valori NULL nelle colonne che non lo permettono). Ogni violazione di queste regole porterà SQL Server a mostrare messaggi d’errore.
Dopo avere inserito alcune righe nelle nostre due tabelle di prova (facendo attenzione ad inserire il valore corretto nella colonna IdDipendente della tabella PresenzeDipendenti in modo che esso corrisponda ad un valore esistente nella tabella AnagraficaDipendenti) avremo una situazione simile alla seguente per le due tabelle
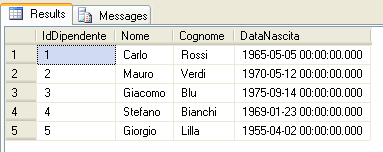
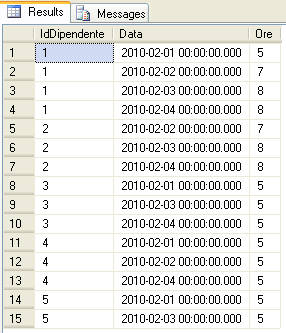
Chiaramente lavorare sui dati implica anche effettuare modifiche e cancellazioni e le sintassi di base per effettuare tali operazioni sono rispettivamente
e

L’approfondimento delle varie forme che queste istruzioni possono assumere esula dagli scopi della presente guida e vi invito ad approfondire autonomamente la conoscenza della sintassi SQL.
Interrogare i dati
L’obiettivo delle interrogazioni (query) sui dati è quello di ottenere informazioni da SQL Server in modo più veloce possibile. Il modo più semplice di ottenere informazioni è quello di utilizzare SQL Server management Studio, utilizzando il quale non è necessario conoscere i dettagli della sintassi di una query. Per effettuare però interrogazioni particolari è più opportuno utilizzare direttamente istruzioni T-SQL all’interno della finestra Query Editor.
I risultati delle interrogazioni possono essere semplicemente visualizzati o anche memorizzati (anche su file ad esempio) in modo che essi possano essere utilizzati per vari scopi.
Effettuare interrogazioni tramite SQL Server Management Studio è davvero molto semplice. Per fare questo nella finestra Object Explorer clicchiamo con il tasto destro del mouse sulla tabella AnagraficaDipendenti e scegliamo l’opzione Select Top 1000 Rows. Questa azione comporta l’apertura di una nuova finestra Query Editor che mostra le righe della tabella
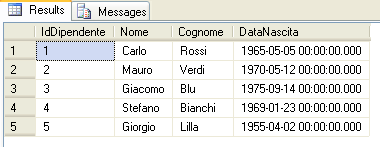
Sopra tale finestra possiamo notare l’istruzione SELECT generata automaticamente da SSMS
/****** Script for SelectTopNRows command from SSMS ******/
SELECT TOP 1000 [IdDipendente]
,[Nome]
,[Cognome]
,[DataNascita]
FROM [DBTEST].[dbo].[AnagraficaDipendenti]Il valore 1000 accanto alla clausola top indica a SQL Server di restituire le prime 1000 righe della tabella e ovviamente se desideriamo visualizzare un numero diverso di righe basta modificare tale valore e rieseguire la query.
Se invece vogliamo effettuare interrogazioni sui dati senza l’aiuto di SSMS dobbiamo costruire manualmente la nostra query in uno script T-SQL. La scrittura manuale di una query mette a disposizione funzionalità che l’interrogazione automatica di SSMS non può fornire. Scrivendo una query manualmente è possibile estrarre dati in qualsiasi ordine, interrogare un numero di colonne minore di quelle totali di una tabella, effettuare interrogazioni legando i dati di più tabelle contemporaneamente e molto altro.
Per questo motivo è molto utile dare un’occhiata alla sintassi di una istruzione SELECT nel linguaggio T-SQL

Vi invito a consultare la documentazione ufficiale del linguaggio T-SQL per approfondire il significato di tutte le componenti di questa fondamentale istruzione.
Scriviamo a questo punto la nostra prima semplice istruzione SELECT nel Query Editor
SELECT * FROM dbo.AnagraficaDipendentiQuesta istruzione, quando eseguita restituisce lo stesso risultato della SELECT generata automaticamente da SSMS, l’unica differenza è che mentre nella prima le colonne erano tutte elencate, in quest’ultima ho utilizzato il simbolo * che indica a SQL Server che si desidera visualizzare tutte le colonne di una tabella.
E’ in generale una buona norma scrivere sempre il nome delle colonne che si desidera visualizzare, tralasciando quelle non rilevanti. Questa può sembrare una pratica noiosa da seguire ma nel caso di interrogazioni complesse che coinvolgono diverse tabelle essa migliora la velocità delle query.
Esistono diverse modalità di visualizzare i dati di una interrogazione: in griglia, in modalità testuale e in un file. Per scegliere tra queste opzioni basta collocarsi in una finestra Query Editor e cliccare nella barra dei menù su Query, selezionando poi l’opzione Results To che ci permette di scegliere fra le tre modalità
Scegliendo l’opzione che desideriamo ed eseguendo la query avremo i dati nella modalità scelta.
Ecco ad esempio i nostri dati in formato text
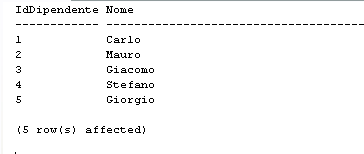
Esistono diversi modi di limitare la ricerca di record in una query ed il principale è quello di utilizzare una clausola WHERE. All’interno di tale clausola è infatti possibile impostare dei filtri sui valori delle colonne di una tabella utilizzando operatori come <, >, =, LIKE e NOT.
Eseguendo una query simile alla seguente otterremo tutti i record della tabella AnagraficaDipendenti in cui il cognome del dipendente inizia con la lettera A
SELECT * FROM dbo.AnagraficaDipendenti WHERE Cognome LIKE 'A%'Chiaramente si tratta di un esempio banale e lo scopo di tale guida non è quello di illustrare le potenzialità del linguaggio SQL, per approfondire le quali vi invito a consultarne la documentazione ufficiale.
Quando il motore di SQL Server esegue una istruzione SELECT è la clausola WHERE la prima ad essere valutata. I dati vengono analizzati utilizzando gli indici, se presenti, per determinare se le varie righe soddisfino le condizioni specificate nella clausola WHERE e in caso positivo esse vengono incluse nell’ insieme di risultati (result set).
La scansione di una tabella può presentare importanti problemi di prestazioni e l’ottenimento dei risultati in alcuni casi può richiedere davvero molto tempo. Per tale motivo per tabelle di grandi dimensioni è sempre consigliabile definire opportuni indici (come abbiamo visto nella lezione su questo tema).
Transazioni
Come abbiamo visto nelle lezioni precedenti tramite le istruzioni T-SQL è possibile inserire dati nelle tabelle, modificare e cancellare tali dati. In alcune circostanze quando si esegue una sequenza di combinazioni di tali operazioni è desiderabile che tale sequenza porti o ad eseguire tutte le operazioni in essa contenute o a non eseguirne nessuna.
In tali scenari ci vengono in aiuto le cosiddette transazioni. Una transazione è fondamentalmente un metodo attraverso cui i programmatori possono definire un’unità di lavoro che deve essere completata nella sua interezza per essere considerata valida.
Esistono quattro concetti fondamentali legati ad una transazione:
- Atomicità – Tutte le modifiche ai dati all’interno di una transazione devono essere valide e trasmesse correttamente al database. Se una soltanto delle operazioni non giunge a buon fine tutte le altre devono essere annullate (il cosiddetto rollback della transazione).
- Consistenza – Finchè dati non vengono trasmessi al database essi devono rimanere in uno stato consistente e mantenere la propria integrità.
- Isolamento – Ogni modifica fatta all’interno di una transazione deve essere isolata da modifiche apportate da altre transazioni contemporanee.
- Permanenza – Se la transazione va a buon fine le modifiche vengono trasmesse al database e qualsiasi malfunzionamento di sistema (hardware o software) non deve comportare la perdita di tali modifiche.
Una transazione può essere utilizzata per gestire qualsiasi manipolazione sui dati che si basi su istruzioni UPDATE, DELETE e INSERT o combinazioni di esse. Ovviamente non ha senso utilizzare una transazione se si effettuano soltanto delle SELECT.
Un concetto molto importante legato alle transazioni è quello di deadlock. Con questo termine si indica la situazione in cui due differenti manipolazioni sugli stessi dati, in transazioni differenti, vengono effettuate contemporaneamente. In questa situazione ogni transazione attende che l’altra finisca le sue manipolazioni e quindi si viene a creare una sorta di blocco (il deadlock appunto) che può interessare solo le tabelle coinvolte o in alcuni casi l’intero database.
Una transazione viene avviata e alla fine della stessa è possibile rendere definitive le manipolazioni sui dati (si parla di commit della transazione) o annullarle interamente (rollback dell atransazione). L’avvio di una transazione avviene tramite il comando BEGIN TRAN. Dopo tale comando (e prima di un eventuale comando COMMIT TRAN o ROLLBACK TRAN) tutte le operazioni che si effettuano sui dati sono incluse in una transazione.
Il comando COMMIT TRAN rende le modifiche effettuate sui dati definitive sul database e una volta eseguito non consente di ritornare alla situazione precedente alla transazione. Se invece si vogliono annullare tutte le modifiche fatte sui dati a partire dall’inizio di una transazione occorre utilizzare il comando ROLLBACK TRAN.
Vediamo adesso alcuni esempi di utilizzo di tali comandi. Utilizziamo la tabella AnagraficaDipendenti e supponiamo di volere cambiare il nome del dipendente con IdDipendente = 3, quindi scriviamo il seguente codice
SELECT 'Prima',IdDipendente,Cognome,Nome
FROM dbo.AnagraficaDipendenti
WHERE IdDipendente = 3
BEGIN TRAN Modifica
UPDATE dbo.AnagraficaDipendenti
SET Nome = 'Augusto'
WHERE IdDipendente = 3
COMMIT TRAN
SELECT 'Dopo',IdDipendente,Cognome,Nome
FROM dbo.AnagraficaDipendenti
WHERE IdDipendente = 3Il risultato della nostra istruzione sarà
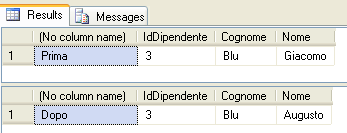
Vediamo adesso l’applicazione del comando ROLBACK TRAN cercando di modificare ancora il nome dello stesso dipendente in Giulio
SELECT 'Prima',IdDipendente,Cognome,Nome
FROM dbo.AnagraficaDipendenti
WHERE IdDipendente = 3
BEGIN TRAN Modifica
UPDATE dbo.AnagraficaDipendenti
SET Nome = 'Giulio'
WHERE IdDipendente = 3
SELECT 'Durante',IdDipendente,Cognome,Nome
FROM dbo.AnagraficaDipendenti
WHERE IdDipendente = 3
ROLLBACK TRAN
SELECT 'Dopo',IdDipendente,Cognome,Nome
FROM dbo.AnagraficaDipendenti
WHERE IdDipendente = 3Il risultato della nuova istruzione sarà
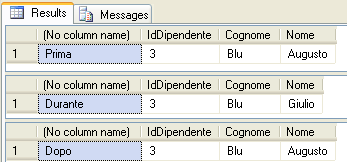
Come potete notare all’interno della transazione viene eseguito l’update del record ma successivamente al rollback la situazione viene riportata allo stato originale. Chiaramente non ha senso utilizzare una transazione per un solo UPDATE ma questo esempio è molto utile per capire la modalità di funzionamento di tale meccanismo.
Stored procedure e funzioni
Strored procedure e funzioni sono due diversi tipi di oggetti che forniscono funzionalità similari. La differenza principale è che una stored procedure è un insieme di codice che viene eseguito in una unità di lavoro, mentre una funzione è un insieme di codice che viene eseguito in una unità di lavoro ma che è contenuta in un’altra unità di lavoro.
Quando si scrive una query in una finestra Query Editor è possibile salvarne il codice sul disco ma non è possibile memorizzarlo su SQL Server. Spesso tuttavia ci si trova nella situazione di dover eseguire interrogazioni multiple in SQL Server e memorizzare tale sequenza di query sul server. Per fare ciò è possibile utilizzare appunto stored procedure e funzioni.
SQL Server assume che ognuno di questi oggetti verrà eseguito più volte e per tale motivo quando viene eseguito per la prima volta viene creato il cosiddetto query plan, con i dettagli su come eseguire al meglio le istruzioni. Come per gli altri oggetti di un database è possibile assegnare un determinato livello di sicurezza a stored procedure e funzioni, in modo che soltanto certi utenti possano eseguirle.
Stored Procedure
Una stored procedure (SP) è dunque un insieme di comandi T-SQL compilati, direttamente accessibili da SQL Server. Tali comandi vengono eseguiti come un’unica unita di lavoro (batch) sul server e il beneficio è che il traffico di rete viene ridotto limitando la congestione della rete stessa. Oltre a istruzioni SELECT, UPDATE e DELETE una SP possono richiamare altre SP, utilizzare istruzioni che controllano il flusso di esecuzione e funzioni di aggregazione.
E’ importante sottolineare che oltre alle SP create dai programmatori esistono centinaia di SP di sistema all’interno di SQL Server (tutte cominciano con il prefisso sp_).
I benefici derivanti dall’utilizzo delle SP sono diversi. Ad esempio evitano l’accesso diretto alle tabelle da parte egli utenti ed inoltre vengono ottimizzate tramite sistemi di caching per essere più performanti possibile. Si può dire che esse costituiscano una sorta di interfaccia tramite cui operare sui dati di un database senza conoscerne la struttura e le relazioni.
La sintassi per la creazione di una SP è la seguente
Dopo aver inserito il nome della funzione occorre specificare i parametri (se necessari e comunque preceduti dalla @) che la SP richiede, con relativo tipo di dati ed eventualmente valore di default. E’ anche possibile ritornare uno o più valori o una tabella di dati utilizzando un parametro per trasmettere tali informazioni. Tale parametro deve essere seguito dalla parola riservata OUTPUT e per esso non può essere definito un valore di default.
Nella sintassi generale possiamo notare anche le opzioni RECOMPILE e ENCRYPTION. La prima indica a SQL Server di ricompilare la SP ogni volta che viene eseguita per forzare ogni volta la rigenerazione del piano di esecuzione, cosa che abbiamo detto in precedenza migliora le prestazioni. La seconda comporta la crittografia del contenuto della SP in modo che esso non sia visibile e comprensibile da chi non ha diritto di farlo.
Dopo la parola riservata AS comincia poi un blocco BEGIN-END dove possiamo inserire le nostre istruzioni T-SQL. Di seguito un esempio di una SP che mette in join le tabelle AnagraficaDipendenti e PresenzeDipendenti e restituisce i dati del dipendente corrispondente ad un determinato IdDipendente
CREATE PROCEDURE ProceduraTest
@IdDipendente int
AS
BEGIN
SELECT *
FROM dbo.AnagraficaDipendenti A
INNER JOIN dbo.PresenzeDIpendenti P
ON A.IdDipendente = P.IdDipendente
WHERE A.IdDipendente = @IdDipendente
ENDPer chiamare tale procedura tramite il Query Editor basta scrivere
EXEC ProceduraTest 1Il risultato sarà il seguente
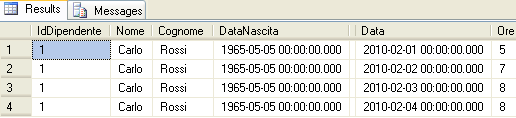
cioè i dati relativi al dipendente con IdDipendente = 1.
All’interno di SQL Server management Studio se clicchiamo sul nodo Stored Procedures del nostro database e scegliamo l’opzione New Stored Procedure SQL Server genererà per noi il template relativo sul quale poi potremo lavorare.
Funzioni
Una SP non può essere non inclusa in un’istruzione di SELECT, essa semplicemente completa il proprio lavoro e termina la propria esecuzione. Questo è proprio uno scenario in cui le funzioni sono molto utili poichè esse sono simili alle SP ma è possibile utilizzarle all’interno di una query per sfruttare i dati che esse restituiscono.
Le funzioni possono essere di due tipi: scalari o tabellari. Le scalari restituiscono un singolo valore e la relativa sintassi è la seguente

Notate che anche le funzioni possono richiedere parametri, modificabili all’interno delle stesse se nella loro definizione dopo il tipo di dati non viene messo il valore READONLY. Di diverso rispetto alle SP c’è l’istruzione RETURNS che serve a specificare il tipo di dati del valore scalare che la funzione restituirà e l’istruzione RETURN che fa sì che la funzione restituisca tale valore.
Ecco un esempio di una semplice funzione che ricevendo come input un IdDipendente ed una data restituisce il numero di ore lavorative di quel dipendente in quella data
CREATE FUNCTION GetOre
(
@IdDipendente int,
@Data datetime
)
RETURNS int
AS
BEGIN
DECLARE @NumeroOre int
SELECT @NumeroOre = Ore
FROM dbo.PresenzeDipendenti
WHERE IdDipendente = @IdDipendente AND Data = @Data
RETURN @NumeroOre
END
GOPer chiamare tale funzione tramite il Query Editor basta scrivere
SELECT dbo.GetOre(1, '20100204')Il risultato sarà il seguente
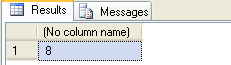
cioè il numero di ore lavorative del dipendente con IdDipendente = 1 nel giorno 04/02/2010.
Le funzioni tabellari sono del tutto simili ma restituiscono una tabella di dati. La sintassi è la seguente

L’espressione select_stmt indica una query che restituirà i dati richiesti in forma tabellare.
Come nel caso delle SP cliccando sui nodi relativi alle funzioni nella finestra Object Explorer e scegliendo l’opzione New SQL Server genererà automaticamente gli script di base.
Viste
Una vista è una sorta di tabella virtuale che non contiene fisicamente dati ma soltanto una query che l’utente definisce al momento della sua creazione. Si può pensare dunque ad una vista come una query fatta su una o più tabelle che viene memorizzata sul database. Le viste vengono utilizzate molto come misura di sicurezza, restringendo la visualizzazione dei dati da parte degli utenti solo a certe colonne o righe e restituendo dati riepilogativi anziché dettagliati.
Le viste quindi si utilizzano fondamentalmente per due scopi: uno è quello di raggruppare dati appartenenti a diverse tabelle ma correlati; l’altro è quello di consentire agli utenti di visualizzare informazioni specifiche provenienti da determinate tabelle senza che essi accedano direttamente alle tabelle per motivi, come accennato, anche di sicurezza. Esse non sono uno strumento che serve a processare dati, a differenza ad esempio delle stored procedure, ma soltanto a gestire una query alla volta.
Come abbiamo più volte rimarcato la sicurezza è una componente fondamentale di un database e poichè le viste costituiscono uno strumento utile proprio per assicurare questo requisito è possibile crittografare le query che si trovano all’interno di esse.
Vediamo un esempio pratico di come funziona una vista. Prendiamo come al solito in considerazione le nostre due tabelle AnagraficaDipendenti e PresenzeDipendenti. Supponiamo che gli utenti di un’applicazione che gestisce tali tabelle abbiano il permesso di consultare nome, cognome e l’importo della retribuzione di ciascun dipendente ma non la data di nascita degli stessi.
Creiamo una opportuna vista tramite SQL Server Management Studio. Per fare ciò clicchiamo nella finestra Object Explorer con il tasto destro del mouse sul nodo Views del nostro database e scegliamo l’opzione New View
Si aprirà la finestra Add table con l’elenco delle tabelle del nostro database
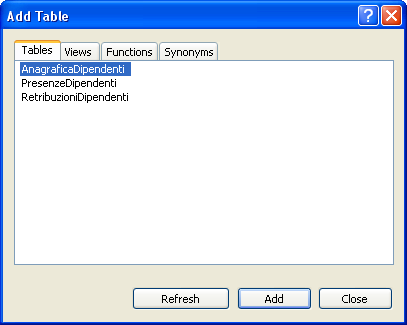
Selezioniamo le due tabelle che ci interessano e clicchiamo su Close.
Si aprirà a questo punto la finestra View Designer che sarà simile alla seguente
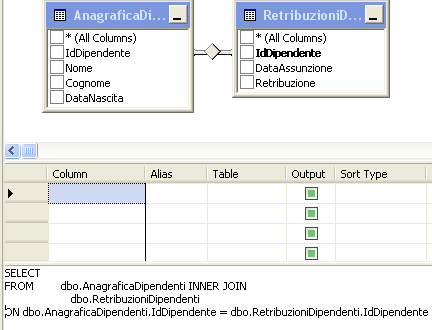
Spuntiamo nelle tabelle i campi che vogliamo visualizzare in seguito all’esecuzione della vista e clicchiamo sul pulsante di salvataggio. Ci verrà richiesto di inserire il nome delle vista
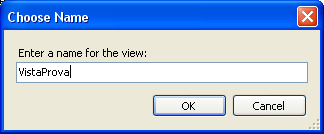
Clicchiamo su OK e ritroveremo la nostra vista nella finestra Object Explorer
Se vogliamo accedere nuovamente al designer della nostra vista basta cliccare con il tasto destro del mouse sulla stessa e scegliere l’opzione Design. Nella finestra View Designer possiamo modificare la nostra vista e nella parte centrale impostare tutta una serie di opzioni sulle colonne delle tabelle coinvolte come: nome alternativo (Alias), ordine (Sort Order) ed eventuali filtri (Filter)
Se invece desiderate modificare la vista direttamente tramite il codice T-SQL cliccando nuovamente con il tasto destro del mouse su di essa scegliamo l’opzione Script View – ALTER To – New Query Editor Window. Si aprira una finestra del Query Editor simile alla seguente
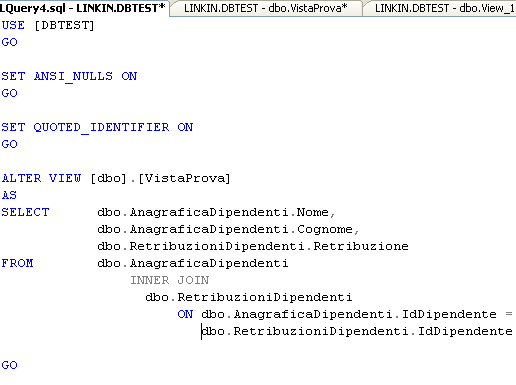
in cui è possibile andare ad effettuare le modifiche che si desidera.
Una volta definita la vista è possibile effettuare query tramite la stessa come se fosse una tabella reale. Possiamo scrivere ad esempio
SELECT *
FROM dbo.VistaProva
WHERE IdDipendente = 3Trigger
Spesso, soprattutto nei sistemi di grandi dimensioni, la modifica di determinati dati richiede un’azione automatica su altri dati, residenti sullo stesso database o su database differenti ed i trigger sono gli strumenti adatti a fare questo.
Un trigger è una stored procedure specializzata che può essere eseguita o in caso di modifica dei dati (trigger DML – Data Modification Language) o in caso di definizione del modello dei dati (trigger DDL – Data Definition Language) come nel caso di istruzioni CREATE TABLE.
Noi ci soffermeremo sui trigger DML che possono essere considerati come parti di codice legate a tabelle specifiche che vengono eseguite automaticamente in conseguenza di istruzioni INSERT, DELETE o UPDATE.
I trigger DML possono essere utilizzati per diversi scopi. Un utilizzo abbastanza diffuso è legato a diverse forme di validazione e controllo sui dati. Chiaramente l’utilizzo di chiavi e vincoli è preferibile dal punto di vista delle prestazioni ma i trigger sono la scelta migliore quando le validazioni da effettuare sono complesse.
Un altro uso molto diffuso si può riscontrare quando è necessario effettuare modifiche sui dati di altre tabelle nel momento in cui si verifica una variazione dei dati sulla tabella contenente un trigger.
E’ possibile creare trigger separati per ciascuna azione che si effettua su una tabella tranne per le istruzioni SELECT perchè ovviamente tali istruzioni non comportano modifiche ai dati.
I trigger DML possono essere di tre tipi:
- INSERT trigger
- DELETE trigger
- UPDATE trigger
E’ possibile anche avere una combinazione dei tre tipi.
La sintassi T-SQL per la creazione di un trigger è abbastanza complessa ed è la seguente

A parte gli elementi che è facile comprendere vorrei soffermarmi su alcuni elementi di tale sintassi.
Il primo è l’opzione

FOR, AFTER e INSTEAD OF sono tre opzioni che specificano quando il trigger deve scattare. L’opzione FOR indica un’azione che deve essere contemporanea all’aggiornamento dei dati della tabella; l’opzione AFTER indica un’azione successiva all’aggiornamento dei dati della tabella; l’opzione INSTEAD OF è la più complessa da comprendere e indica che deve essere eseguita l’istruzione del trigger al posto dell’istruzione T-SQL predefinita specificata dopo (INSERT, DELETE o UPDATE).
L’istruzione
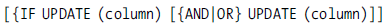
serve invece a verificare se sono stati modificati i dati di specifiche colonne. Impostate correttamente queste opzioni è possibile scrivere il codice T-SQL da eseguire (sql_statements).
Quando una tabella viene modificata, indipendentemente dal tipo di modifica, SQL Server utilizza due tabelle logiche di sistema: DELETED e INSERTED. Quando viene inserito un record in una tabella una copia della riga viene inserita nella tabella INSERTED così come quando una riga viene cancellata una copia di tale riga viene inserita nella tabella DELETED. La modifica porta invece all’inserimento della riga modificata in entrambe le tabelle: nella DELETED con i valori precedenti alla modifica e nella INSERTED con i valori successivi alla modifica.
Per determinare quali campi sono stati modificati una pratica molto comune è quella di comparare i valori della stessa riga tra le due tabelle.
Per creare un trigger in SQL Server management Studio basta espandere il nodo della tabella per la quale si vuole creare, cliccare con il tasto destro del mouse sul nodo Triggers e scegliere l’opzione New Trigger. Verrà generato il seguente codice che dovrà essere modificato per i propri scopi
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date,,>
-- Description: <Description,,>
-- =============================================
CREATE TRIGGER <Schema_Name, sysname, Schema_Name>.<
Trigger_Name, sysname, Trigger_Name>
ON <Schema_Name, sysname, Schema_Name>.<Table_Name,
sysname, Table_Name>
AFTER <Data_Modification_Statements, , INSERT,DELETE,UPDATE>
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- Insert statements for trigger here
END
GOReporting Services
La reportistica è un’area fondamentale nella gestione delle aziende moderne. Nel corso dell’installazione di SQL Server tra le varie componenti da installare abbiamo selezionato Reporting Services. Tale componente utilizza due database di SQL Server (ReportServer e ReportServerTempDB) per memorizzare le informazioni da utilizzare per la creazione di diversi tipi di report.
Il database ReportServer memorizza diverse informazioni tra cui definizioni dei report, origini dati, utenti, ruoli. Il databse ReportServerTempDB memorizza invece oggetti temporanei come tabelle di lavoro e dati sulle sessioni. Le origini dati (data source) dei report possono essere SQL Server, Analysis Services, Excel, Access, Oracle, files, origini dati OLE DB o ODBC.
Per utilizzare Reporting Services in SQL Server 2008 è necessario prima configurarlo utilizzando il tool Reporting Services Configuration Manager. Per fare ciò clicchiamo sul Start – Tutti i programmi – Microsoft SQL Server 2008 – Configuration Tools – Reporting Services Configuration Manager
Comparirà la seguente finestra di dialogo
in cui dobbiamo inserire il nome del nostro server e selezionare l’istanza di SQL Server. Clicchiamo su Connect e accediamo alla finestra Reporting Services Configuration Manager

La prima opzione da impostare nella definizione del servizio è l’account che Reporting Services utilizzerà all’interno di Windows. Cliccando su Service Account comparirà una schermata in cui deve essere selezionato l’account prescelto. E’ indicato selezionare un account di rete quando si ha SQL Server su un server e l’installazione di IIS su un altro server all’interno della rete. Oppure per rendere più sicura la configurazione è possibile selezionare un account di Windows
Passiamo adesso alla schermata Web Service URL, lasciamo i valori di default e clicchiamo su Apply. Se tutto è andato a buon fine in basso nella finestra avremo un messaggio simile al seguente
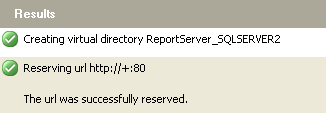
Nella schermata Database clicchiamo sul tasto Change Database e scegliamo se utilizzare un database per i report esistente (a questo punto non ne dovremmo avere) o crearne uno nuovo, impostando tutte le relative credenziali. I passaggi sono molto semplici, basta inserire in una delle schermate successive il nome del nuovo database e proseguire con il wizard fino al termine. Alla fine la schermata riepilogativa sarà simile alla seguente
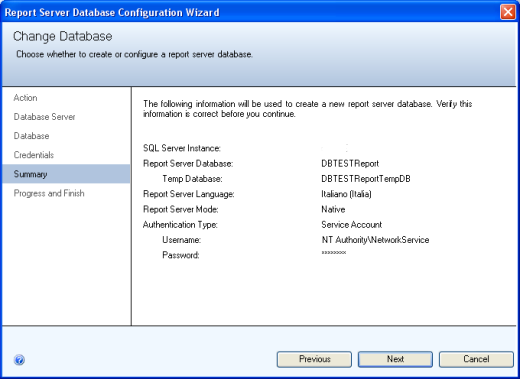
Clicchiamo su Next e poi accediamo all’ultima sezione da configurare prima di poter creare il nostro primo report, la sezione Report Manager URL
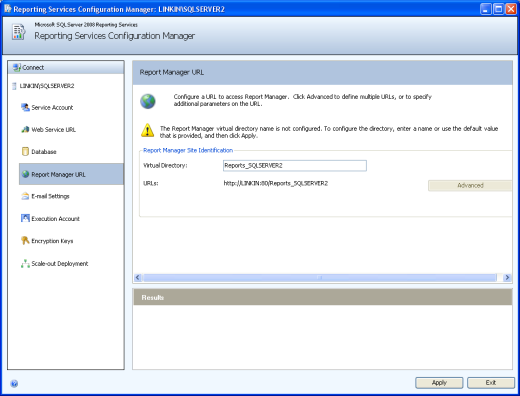
Inseriamo il nome della cartella virtuale che verrà tradotto in un indirizzo per accedere al Report Manager. Clicchiamo su Apply e abbiamo concluso la configurazione.
Vediamo adesso come costruire il nostro primo semplice report. Clicchiamo su Start – Tutti i programmi – Microsoft SQL Server 2008 – SQL Server Business Intelligence Development Studio
All’interno del Development Studio clicchiamo sul menù File e scegliamo l’opzione New – Project. Si aprirà una finestra di dialogo in cui dobbiamo selezionare il tipo di progetto Report Server Project Wizard
Denominiamo il nostro progetto ReportProjectTest e clicchiamo su Ok. Verrà avviato un wizard in cui nella prima schermata dobbiamo selezionare l’origine dei dati
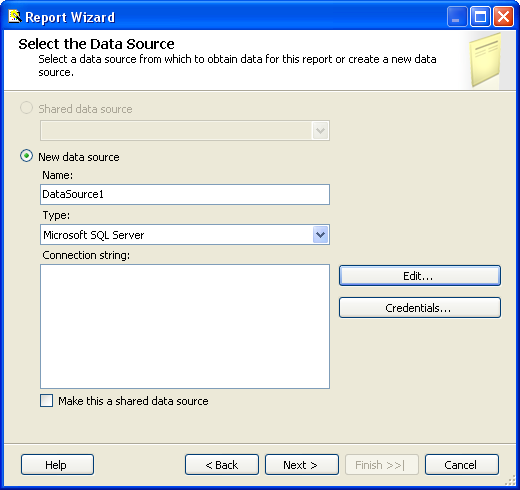
Clicchiamo su Edit, impostiamo le credenziali di connessione al nostro server ed il database da utilizzare (nel nostro caso quello che contiene le tabelle che abbiamo creato nella presente guida) e proseguiamo
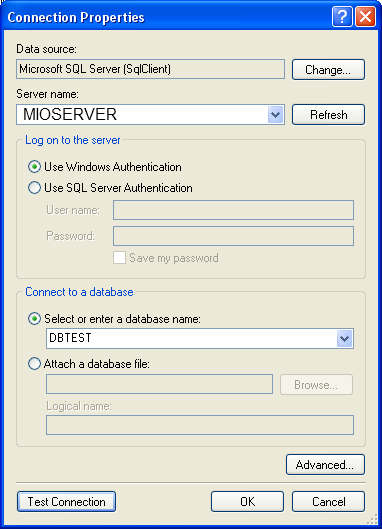
Il prossimo passo è quello di scrivere la query che estrapola i dati di interesse per il nostro report. Nel nostro caso è una semplice query sulla tabella AnagraficaDipendenti
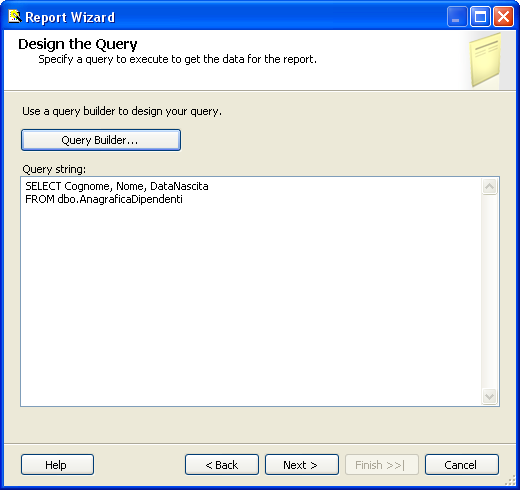
Proseguendo nel wizard dovremo scegliere alcune semplici opzioni tra cui il tipo di report. Proseguiamo fino alla fine e nella schermata finale selezioniamo l’opzione Preview report.
Cliccando su Finish il risultato dovrebbe essere simile al seguente
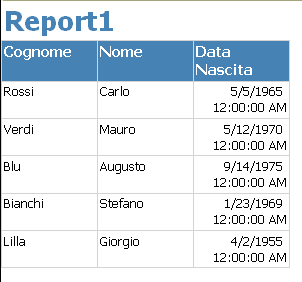
Chiaramente si tratta di un report molto semplice e per approfondire le diverse opzioni e funzionalità disponibili vi invito a consultare la documentazione ufficiale Microsoft.
Considerazioni sulle prestazioni
Migliorare le prestazioni di un database richiede diversi accorgimenti. Quest’attività si differenzia dagli altri processi amministrativi e comprende vari passaggi. Se il DBMS non ha prestazioni accettabili l’amministratore del sistema ha l’obbligo di effettuare le opportune verifiche e possibilmente agire sul software in modo da ottimizzare le prestazioni.
Le prestazioni possono essere misurate in base a due criteri:
- Tempo di risposta
- Throughput
Il tempo di risposta misura la velocità di una transazione o di un programma ed è visto come il tempo che intercorre dal momento in cui un utente invia un comando al momento in cui riceve una risposta. Il Throughput misura invece il comportamento generale del sistema basandosi sul numero di transazioni che possono essere gestite dal sistema in un dato periodo di tempo (infatti si misura in transazioni per secondo).
Esiste una relazione tra tempo di risposta e throughput: quando il tempo di risposta si degrada (perchè ad esempio molti utenti stanno operando contemporaneamente sul sistema) anche il throughput si degrada, quindi c’è una relazione di tipo direttamente proporzionale.
I fattori che influenzano le prestazioni possono essere suddivisi in tre categorie:
- Applicazioni che accedono al database
- Motore di database
- Risorse di sistema
A loro volta questi possono essere influenzati da altri fattori.
Applicazioni
I fattori che influenzano le prestazioni delle applicazioni sono l’efficienza del codice e la loro progettazione fisica.
Molti problemi prestazionali sono causati dall’uso improprio di istruzioni T-SQL e dalla loro sequenza nelle applicazioni. Per tale motivo è opportuno assumere alcuni accorgimenti in quest’area. Un paio di esempi sono l’incoraggiamento nell’uso degli indici clustered e l’indicazione di non utilizzare il predicato NOT IN, accorgimenti che hanno un impatto positivo sulle prestazioni.
Per quanto riguarda la progettazione del database si raccomanda di denormalizzare alcune delle tabelle dello stesso. Denormalizzare significa che i dati di due o più tabelle vengono uniti in modo da avere una certa quantità di informazione ridondante. Si pensi ad una tabella in cui si inseriscono i record della tabella AnagraficaDipendenti ed i record della tabella PresenzeDipendenti. Tale tabella avrà informazioni ridondanti su nome, cognome e data di nascita dei dipendenti.
La denormalizzaione dei dati presenta vantaggi e svantaggi. I vantaggi sono che riduce l’uso di operazioni di join e riduce pure il numero di tabelle del database. Gli svantaggi invece sono la maggiore quantità di memoria fisica richiesta e la maggiore difficoltà nel modificare i dati (a causa della ridondanza).
Motore di database
Il motore di database (database engine) può influire sulle prestazioni dell’intero sistema. Le sue due componenti che più delle altre possono causare un degrado delle prestazioni sono l’ottimizzatore (optimizer) e i blocchi (locks).
L’ottimizzatore è un componente che formula diversi piani di esecuzione per le query e poi sceglie quello migliore. La decisione su quale piano di esecuzione utilizzare dipende da diversi fattori come gli indici da utilizzare e l’ordine dei join tra le tabelle. Queste decisioni possono influire sulle prestazioni.
I blocchi invece vengono utilizzati dal sistema come meccanismo per proteggere il lavoro di un utente da sovrascritture e servono essenzialmente a prevenire modifiche contemporanee degli stessi dati. I blocchi influiscono sulle prestazioni a seconda delle dimensioni degli oggetti che vengono bloccati e dal livello di isolamento. I blocchi a livello di riga sono quelli che influenzano meno le prestazioni rispetto ad esempio ai blocchi a livello di tabella.
Risorse di sistema
Il motore di database gira su sistemi operativi Windows che ovviamente utilizzano determinate risorse di sistema. Tali risorse hanno un impatto significativo sulle prestazioni del sistema operativo e del DBMS.
Quelle principali sono:
- Processore
- Memoria
- Velocità di I/O del disco
- Rete
Ovviamente più potenti e performanti sono questi componenti e migliori saranno le prestazioni del database.
Tutti i fattori che influenzano le prestazioni possono essere monitorati attraverso differenti componenti che possono essere suddivisi in quattro categorie:
- Performance Monitor
- Viste dinamiche di gestione (Dynamic Management Views – DMV)
- Comandi DBCC
- Stored procedure di sistema
Il Performance Monitor è uno strumento grafico di Windows che fornisce la funzionalità di monitorare le attività di Windows e quindi anche del DBMS. Ad esso si accede tramite gli Strumenti di Amministrazione di Windows
Gli altri strumenti di gestione sono un po’ più complessi e per approfondirne la conoscenza vi invito a consultare la documentazione ufficiale Microsoft.