Nelle applicazioni reali, si opera frequentemente su grandi moli di dati distribuiti su più tabelle. In questi contesti, risulta molto utile la clausola JOIN del linguaggio SQL, che serve a combinare i dati di due o più tabelle basandosi su alcune condizioni logiche. Comprendere i vari tipi di JOIN è cruciale per sfruttare al meglio le potenzialità dei database, soprattutto in SQL Server.
In particolare, in SQL Server esistono tre differenti tipi di JOIN:
- INNER JOIN
- OUTER JOIN
- CROSS JOIN
Per comprendere meglio le differenze tra le diverse tipologie di JOIN, supponiamo di operare su un database in cui abbiamo definito due tabelle denominate Dipendenti e Aree, strutturate come segue:
CREATE TABLE [dbo].[Dipendenti](
[IdDipendente] [int] IDENTITY(1,1) NOT NULL,
[Cognome] [nvarchar](150) NOT NULL,
[Nome] [nvarchar](150) NULL,
[Email] [nvarchar](150) NULL,
[IdArea] [int] NULL,
PRIMARY KEY CLUSTERED
(
[IdDipendente] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[Aree](
[IdArea] [int] IDENTITY(1,1) NOT NULL,
[NomeArea] [nvarchar](255) NOT NULL,
PRIMARY KEY CLUSTERED
(
[IdArea] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARYIl legame tra le due tabelle è costituito dal campo IdArea, che indica l’area aziendale a cui ogni dipendente appartiene. È importante notare che non tutti i dipendenti sono necessariamente associati a un’area. A questo punto, procediamo a populare le tabelle con alcuni dati:
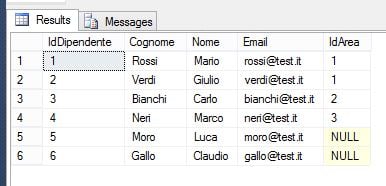
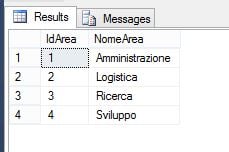
A questo punto abbiamo tutti gli elementi per analizzare i diversi tipi di JOIN.
INNER JOIN in SQL Server
L’INNER JOIN restituisce tutte le righe delle tabelle coinvolte in cui esiste una corrispondenza tra i valori delle colonne presenti nella clausola ON. Consideriamo di voler ottenere l’ID, il nome, il cognome e l’area di tutti i dipendenti assegnati a un’area aziendale:
SELECT D.IdDipendente, D.Nome, D.Cognome, A.NomeArea
FROM dbo.Dipendenti D
INNER JOIN dbo.Aree A
ON A.IdArea = D.IdAreaQuesta query restituisce il seguente result set:
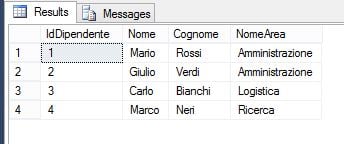
Con l’INNER JOIN, vengono escluse quelle righe della tabella Dipendenti che non hanno una corrispondenza nella tabella Aree in base al campo specificato nella clausola ON del JOIN (cioè IdArea). In questo specifico caso, vengono esclusi i dipendenti con IdDipendente 5 e 6, poiché non sono assegnati ad alcuna area.
OUTER JOIN in SQL Server
Esistono tre tipi di OUTER JOIN in SQL Server:
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
L’OUTER JOIN restituisce tutte le righe della tabella a sinistra (LEFT) o a destra (RIGHT) della clausola di JOIN, o entrambe (FULL), indipendentemente dalla corrispondenza tra i campi presenti nella clausola ON.
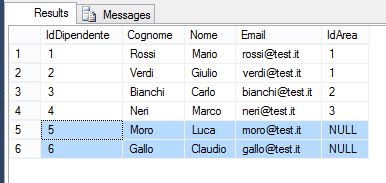
Se vogliamo ottenere l’ID, il nome, il cognome e l’area di tutti i dipendenti, indipendentemente dal fatto che essi siano assegnati effettivamente a un’area, utilizziamo il LEFT OUTER JOIN:
SELECT D.IdDipendente, D.Nome, D.Cognome, A.NomeArea
FROM dbo.Dipendenti D
LEFT OUTER JOIN dbo.Aree A
ON A.IdArea = D.IdAreaIl risultato di questa query è il seguente:
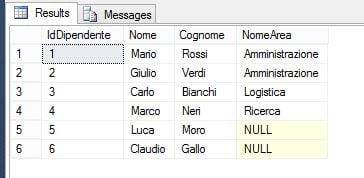
Vengono restituiti tutti i record della tabella a sinistra del JOIN (cioè Dipendenti), anche se non tutti hanno un valore nel campo IdArea. Quindi, se c’è una corrispondenza tra le due tabelle, viene riportata la relativa area; se non c’è, vengono comunque riportati i dati dei dipendenti.
Se desideriamo visualizzare il nome di tutte le aree aziendali, indipendentemente dal fatto che ad esse appartengano dipendenti, possiamo utilizzare il RIGHT OUTER JOIN:
SELECT A.NomeArea, D.IdDipendente, D.Nome, D.Cognome
FROM dbo.Dipendenti D
RIGHT OUTER JOIN dbo.Aree A
ON A.IdArea = D.IdAreaIl risultato sarà quindi il seguente:
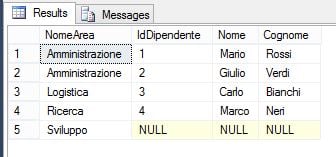
Vengono restituiti tutti i record della tabella a destra del JOIN (cioè Aree), anche se non tutti hanno una corrispondenza con la tabella a sinistra (cioè Dipendenti). Questo significa che, se c’è una corrispondenza tra le due tabelle, verrà riportato il relativo dipendente; se non c’è, verranno comunque riportati i dati delle aree.
Per ottenere tutti i dati di entrambe le tabelle, indipendentemente dall’esistenza di una corrispondenza, utilizziamo il FULL OUTER JOIN:
SELECT D.IdDipendente, D.Nome, D.Cognome, A.NomeArea
FROM dbo.Dipendenti D
FULL OUTER JOIN dbo.Aree A
ON A.IdArea = D.IdAreaIl risultato di questa query è il seguente:
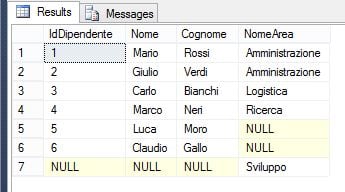
Vengono restituiti tutti i record di entrambe le tabelle. Se esiste una corrispondenza tra un dipendente e un’area, tutti i campi della relativa riga contengono valori; altrimenti, i campi relativi vengono presentati come NULL.
CROSS JOIN in SQL Server
Il CROSS JOIN combina tutte le righe della tabella a sinistra con tutte le righe della tabella a destra, creando tutte le possibili combinazioni di righe. Se nelle nostre tabelle abbiamo rispettivamente 6 e 4 righe, il risultato di questo tipo di JOIN sarà di 24 righe (6×4):
SELECT D.IdDipendente, D.Nome, D.Cognome, A.NomeArea
FROM dbo.Dipendenti D
CROSS JOIN dbo.Aree A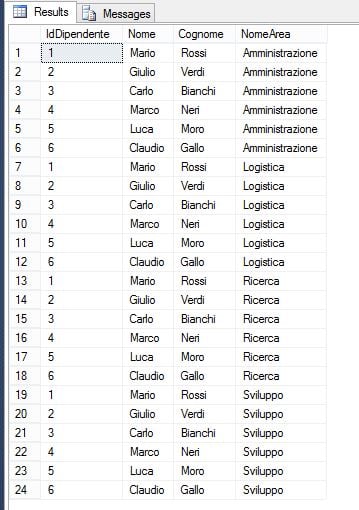
È importante notare che in questa tipologia di JOIN la clausola ON non è richiesta, poiché si tratta di un prodotto cartesiano. Il CROSS JOIN richiede un tempo di esecuzione maggiore rispetto agli altri JOIN, e gli utilizzi sono limitati a scenari specifici, come la generazione di report o combinazioni di dati.
Considerazioni finali
In conclusione, i JOIN vengono utilizzati per estrapolare dati da più tabelle in un’unica query. Nei nostri esempi abbiamo utilizzato un solo tipo di JOIN, ma in una singola query è possibile combinare più tabelle utilizzando diversi tipi di JOIN, a seconda delle necessità. Per ottimizzare le prestazioni dei JOIN, è opportuno limitare il numero di righe coinvolte nelle operazioni, specificando una clausola WHERE. Inoltre, un aspetto fondamentale da ricordare è che le prestazioni dei JOIN migliorano quando le colonne utilizzate per collegare le tabelle sono indicizzate.
Questa comprensione dei JOIN è essenziale per uno sviluppo efficace in SQL Server e migliora significativamente la tua capacità di gestire e analizzare i dati in scenari complessi.